rm(list =ls())# delete any data that's already loaded into Rconflicts_prefer(dplyr::filter)ggplot2::theme_set(ggplot2::theme_bw()+# ggplot2::labs(col = "") +ggplot2::theme( legend.position ="bottom", text =ggplot2::element_text(size =12, family ="serif")))knitr::opts_chunk$set(message =FALSE)options('digits'=6)panderOptions("big.mark", ",")pander::panderOptions("table.emphasize.rownames", FALSE)pander::panderOptions("table.split.table", Inf)conflicts_prefer(dplyr::filter)# use the `filter()` function from dplyr() by defaultlegend_text_size=9run_graphs=TRUE
set.seed(1)mu<-2sigma<-1n<-20x<-rnorm(n =n, mean =mu, sd =sigma)xbar<-mean(x)se<-sigma/sqrt(n)CI_freq<-xbar+se*qnorm(c(.025, .975))print(CI_freq)#> [1] 1.75226 2.62879
Show R code
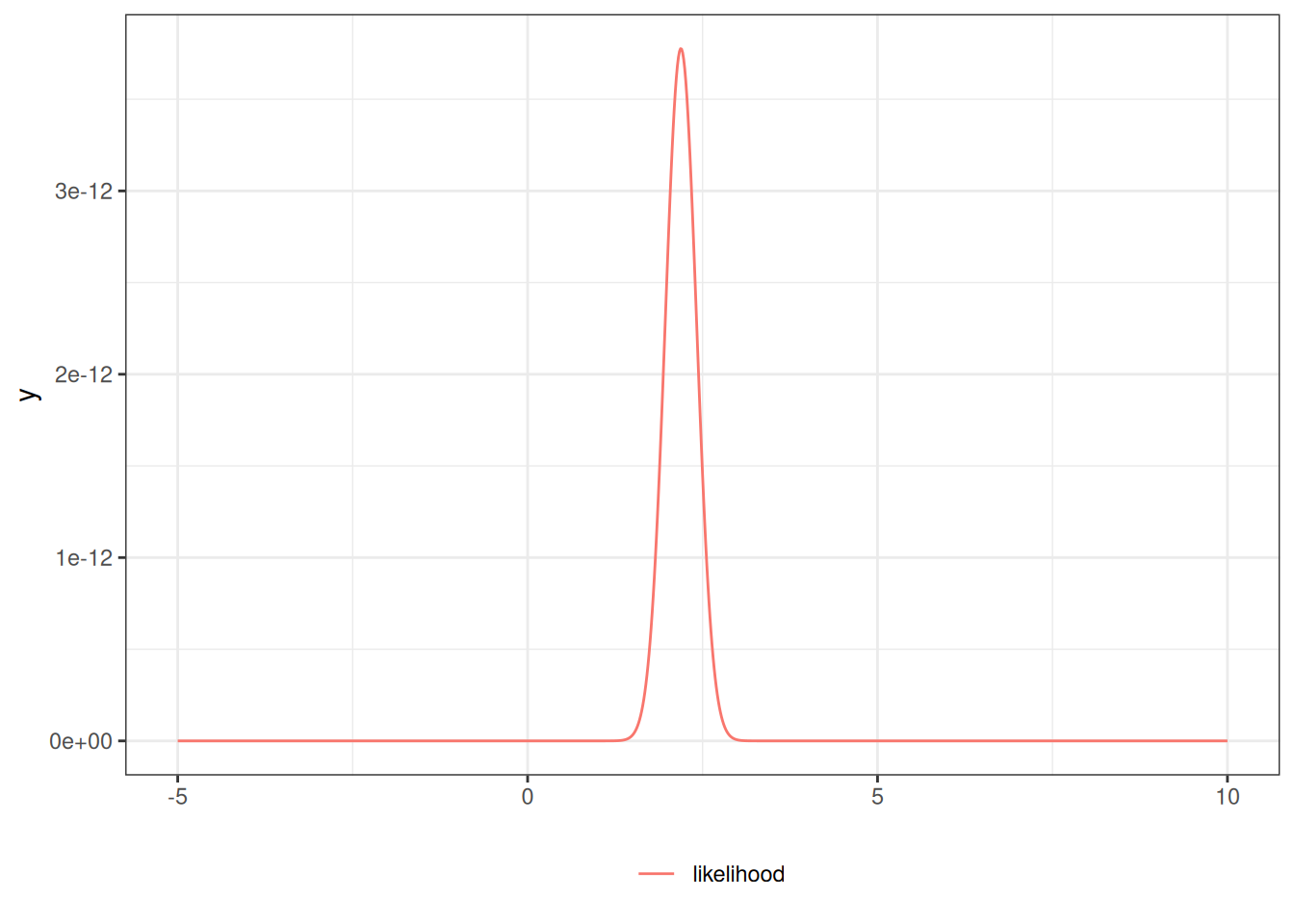
lik0<-function(mu)dnorm(x =x, mean =mu, sd =1)|>prod()lik<-function(mu){(2*pi*sigma^2)^(-n/2)*exp(-1/(2*sigma^2)*(sum(x^2)-2*mu*sum(x)+n*(mu^2)))}library(ggplot2)ngraph<-1001plot1<-ggplot()+geom_function(fun =lik, aes(col ="likelihood"), n =ngraph)+xlim(c(-5, 10))+theme_bw()+labs(col ="")+theme(legend.position ="bottom")print(plot1)
Here’s a Bayesian CI:
Show R code
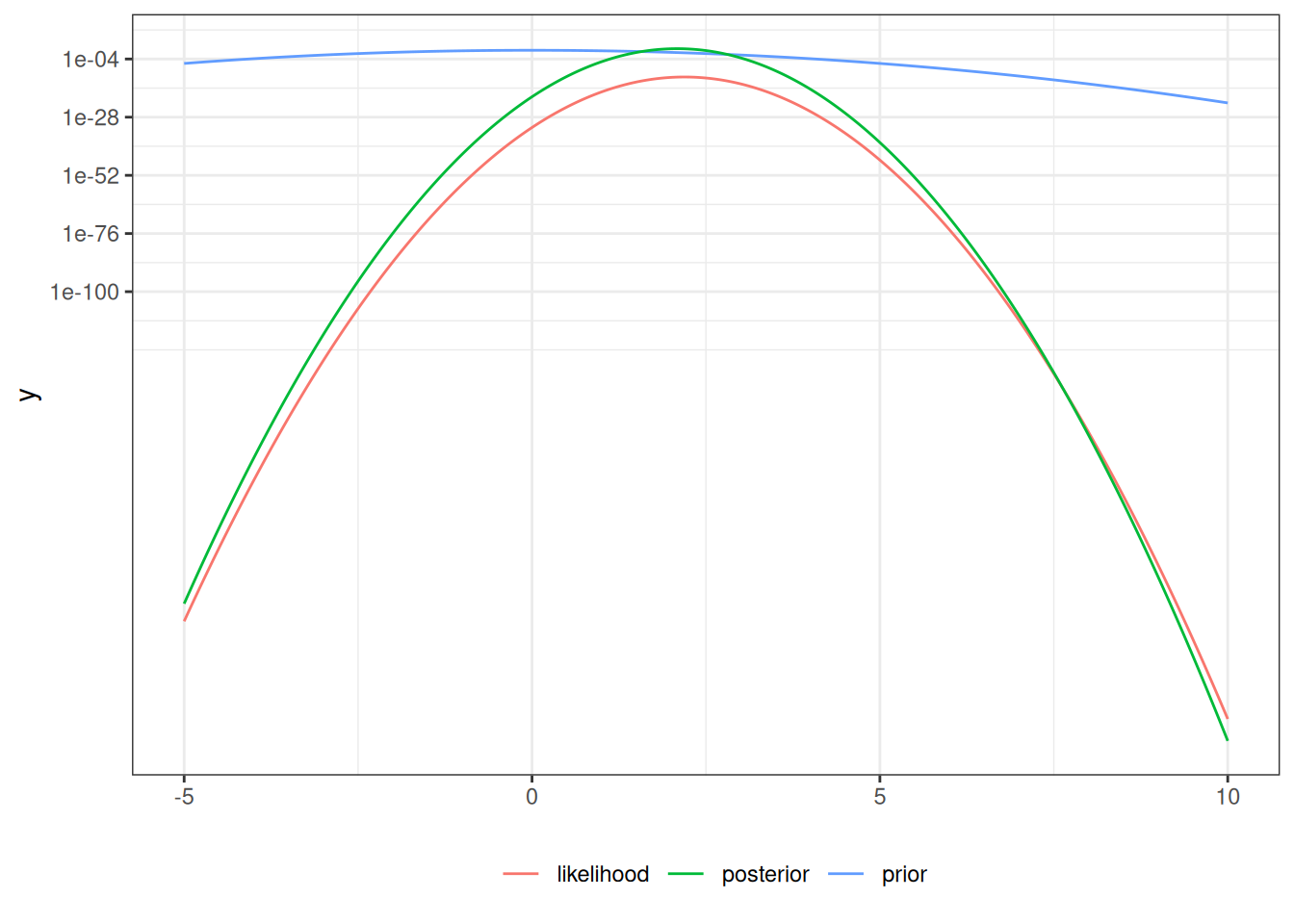
mu_prior_mean<-0mu_prior_sd<-1mu_post_mean<-n/(n+1)*xbarmu_post_var<-1/(n+1)mu_post_sd<-sqrt(mu_post_var)CI_bayes<-qnorm( p =c(.025, .975), mean =mu_post_mean, sd =mu_post_sd)print(CI_bayes)#> [1] 1.65851 2.51391prior<-function(mu)dnorm(mu, mean =mu_prior_mean, sd =mu_prior_sd)posterior<-function(mu)dnorm(mu, mean =mu_post_mean, sd =mu_post_sd)plot2<-plot1+geom_function(fun =prior, aes(col ="prior"), n =ngraph)+geom_function(fun =posterior, aes(col ="posterior"), n =ngraph)print(plot2+scale_y_log10())
Here’s \(p(M \in (l(x),r(x))|X=x)\):
Show R code
pr_in_CI<-pnorm(CI_freq, mean =mu_post_mean, sd =mu_post_sd)|>diff()print(pr_in_CI)#> [1] 0.930583
1 Example with JAGS
This example demonstrates Bayesian inference using JAGS (Just Another Gibbs Sampler) for a simple Bernoulli model from Dobson’s text.
We’ll use a simple Bernoulli model to estimate a probability parameter using Bayesian inference.
Show R code
# JAGS chain initialization functioninitsfunction<-function(chain){stopifnot(chain%in%(1:4))# max 4 chains allowedrng_seed<-(1:4)[chain]rng_name<-c("base::Wichmann-Hill", "base::Marsaglia-Multicarry","base::Super-Duper", "base::Mersenne-Twister")[chain]return(list(".RNG.seed"=rng_seed, ".RNG.name"=rng_name))}# Generate sample dataset.seed(1)data1<-rbinom(n =91, size =1, prob =.6)# Run JAGS modeljags_post0<-run.jags( n.chains =2, inits =initsfunction, model =system.file("extdata/model.dobson.jags", package ="rme"), data =list(r =data1, N =length(data1)), monitor ="p")#> Compiling rjags model...#> Calling the simulation using the rjags method...#> Note: the model did not require adaptation#> Burning in the model for 4000 iterations...#> Running the model for 10000 iterations...#> Simulation complete#> Calculating summary statistics...#> Calculating the Gelman-Rubin statistic for 1 variables....#> Finished running the simulation
Cowles, Mary Kathryn. 2013. Applied Bayesian Statistics: With R and OpenBUGS Examples. Vol. 98. Springer Texts in Statistics. Springer Nature. https://doi.org/10.1007/978-1-4614-5696-4.
Hobbs, N. Thompson, and Mevin B Hooten. 2015. Bayesian Models: A Statistical Primer for Ecologists. STU - Student edition. Princeton University Press.
Korner-Nievergelt, Fränzi, and Fränzi Korner-Nievergelt. 2015. Bayesian Data Analysis in Ecology Using Linear Models with R, BUGS, and Stan. 1st ed. Academic Press.
McElreath, Richard. 2020. Statistical Rethinking : A Bayesian Course with Examples in R and Stan. Second edition. Chapman & Hall/CRC Texts in Statistical Science Series. CRC Press.