Mathematics Prerequisites
Math is not just a way of calculating numerical answers; it is a way of thinking, using clear definitions for concepts and rigorous logic to organize our thoughts and back up our assertions.
Cheng (2025)
These lecture notes use:
- algebra
- precalculus
- univariate calculus
- linear algebra
- vector calculus
Some key results are listed here.
1 Algebra
1.1 Elementary Algebra
Mastery of Elementary Algebra (a.k.a. “College Algebra”) is a prerequisite for calculus, which is a prerequisite for Epi 202 and Epi 203, which are prerequisites for this course (Epi 204). Nevertheless, each year, some Epi 204 students are still uncomfortable with algebraic manipulations of mathematical formulas. Therefore, I include this section as a quick reference.
1.1.1 Equalities
1.1.2 Inequalities
1.1.3 Infimum and supremum
1.1.4 Sums
1.1.5 Products
1.1.6 Division
1.1.7 Sums and products together
1.1.8 Quotients
Additional reference for elementary algebra: https://en.wikipedia.org/wiki/Population_proportion#Mathematical_definition
1.1.9 Exponentials and Logarithms
2 Derivatives
ProofProof
Proof. Apply Theorem 27 and Theorem 23.
3 Integration
Integration is the inverse operation of differentiation: it recovers a function from its derivative and accumulates quantities such as areas, totals, and probabilities. We begin with antiderivatives, then state basic integration rules, and conclude with the Fundamental Theorem of Calculus and a worked example from probability.
3.1 Antiderivatives
Exm
Example 3 (Antiderivative of a power function) For \(f(x) = x^2\), an antiderivative is \(F(x) = \frac{x^3}{3}\), since \(\frac{\partial}{\partial x}\frac{x^3}{3} = x^2 = f(x)\).
Adding any constant \(C\) gives another antiderivative; for example, with \(C = 7\), \(F(x) = \frac{x^3}{3} + 7\) also satisfies \(F'(x) = x^2\), since adding a constant does not change the derivative. See Figure 3.
Show R code
ggplot() +
geom_function(fun = \(x) x^2, xlim = x_lim, linewidth = 1) +
labs(x = "x", y = expression(f(x))) +
theme_minimal()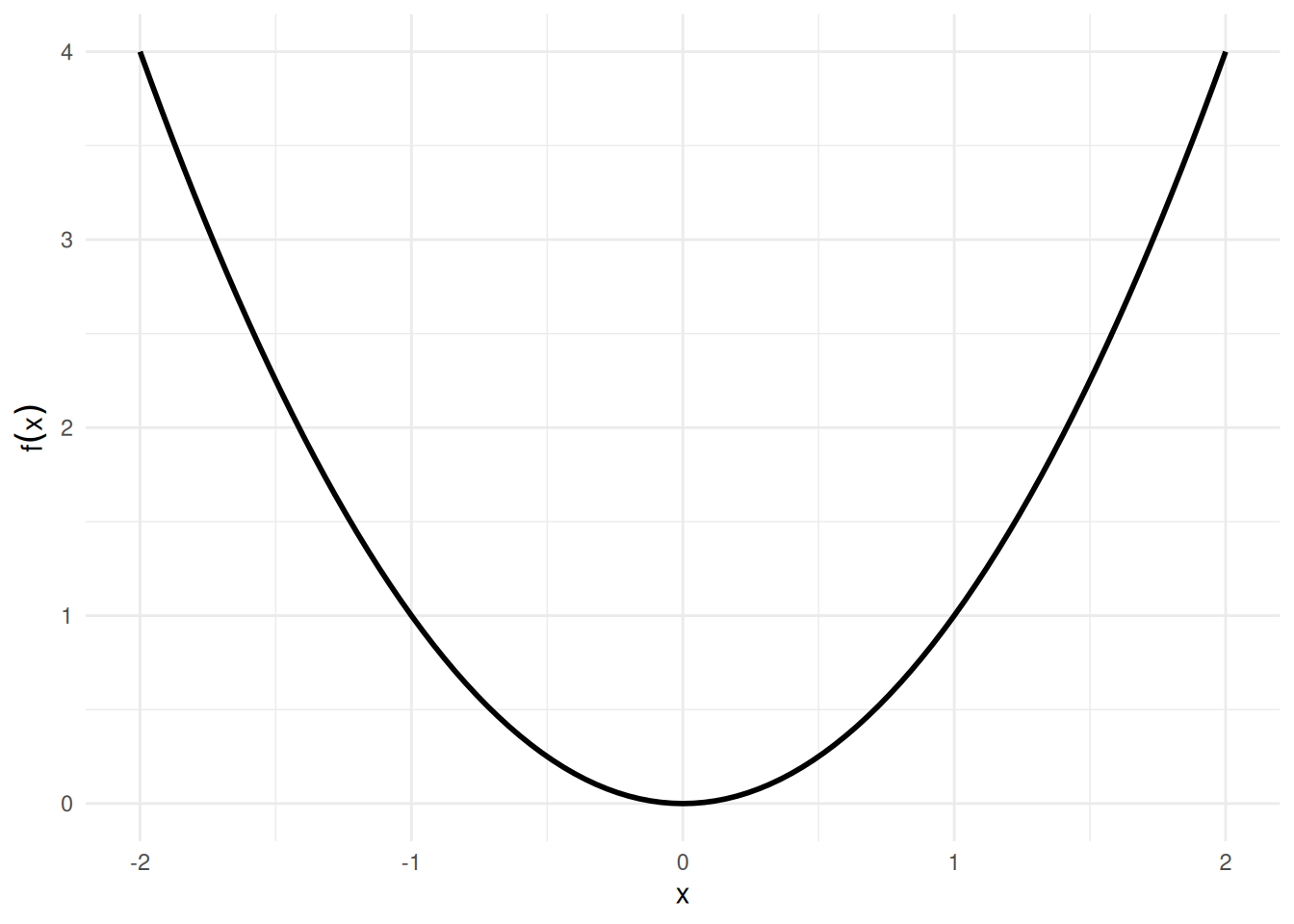
Show R code
x_seq <- seq(x_lim[1], x_lim[2], length.out = 200)
df <- do.call(rbind, lapply(C_vals, \(C) {
data.frame(
x = x_seq,
y = x_seq^3 / 3 + C,
C = factor(C)
)
}))
ggplot(df, aes(x = x, y = y, color = C)) +
geom_line(linewidth = 0.8) +
labs(x = "x", y = expression(F(x)), color = "C") +
theme_minimal()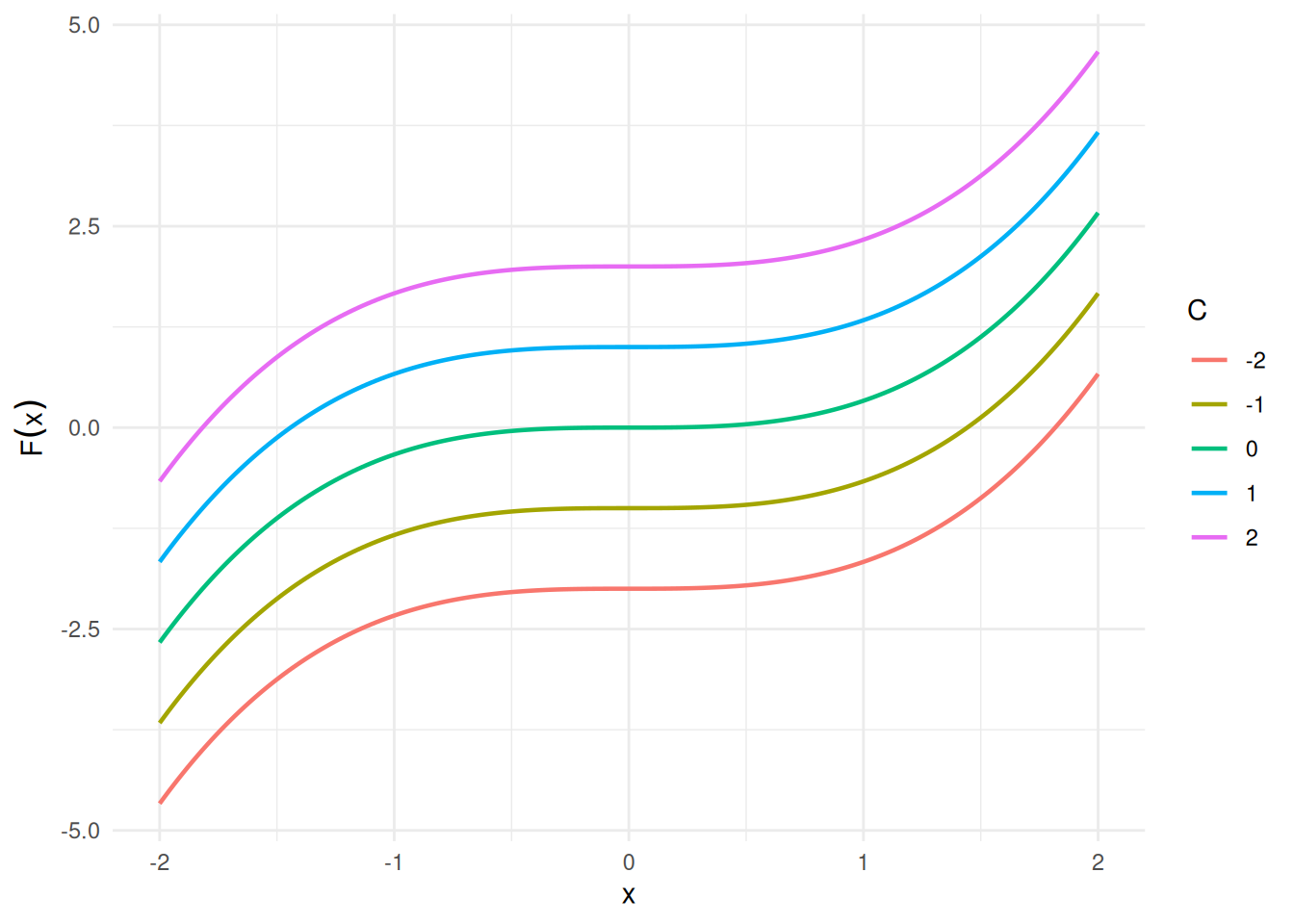
3.2 Regularity Conditions
NoteGeneral Riemann integrability
More generally, using partitions \(\mathcal{P}\) of arbitrary mesh — subintervals of varying widths \(\Delta x_i\) — a bounded function \(f\) is Riemann integrable on \([a, b]\) if
\[\int_a^b f(x)\,dx = \lim_{\|\mathcal{P}\| \to 0} \sum_{i=1}^n f(x_i^*)\,\Delta x_i\]
exists and is finite, where \(\|\mathcal{P}\| = \max_i \Delta x_i\) is the mesh of the partition.
Before stating the Fundamental Theorem of Calculus, we record two prerequisite results. The FTC requires the integrand \(f\) to be continuous, and the two theorems below establish where continuity comes from (differentiability \(\Rightarrow\) continuity) and what it buys us (continuity \(\Rightarrow\) integrability).
Exm
Example 6 (Continuous but not differentiable: \(\mathopen{}\left|x\right|\mathclose{}\)) The absolute-value function \(f(x) = \mathopen{}\left|x\right|\mathclose{}\) is continuous at \(x = 0\) (\(\lim_{x \to 0}\mathopen{}\left|x\right|\mathclose{} = 0 = \mathopen{}\left|0\right|\mathclose{}\)), but it is not differentiable at \(x = 0\): the left-derivative is \(-1\) and the right-derivative is \(+1\).
This shows that the converse of Theorem 30 fails: continuity does not imply differentiability. See Figure 4.
Show R code
ggplot() +
geom_function(fun = abs, xlim = c(-2, 2), linewidth = 1) +
geom_point(aes(x = 0, y = 0), size = 3) +
labs(x = "x", y = expression(f(x) == abs(x))) +
theme_minimal()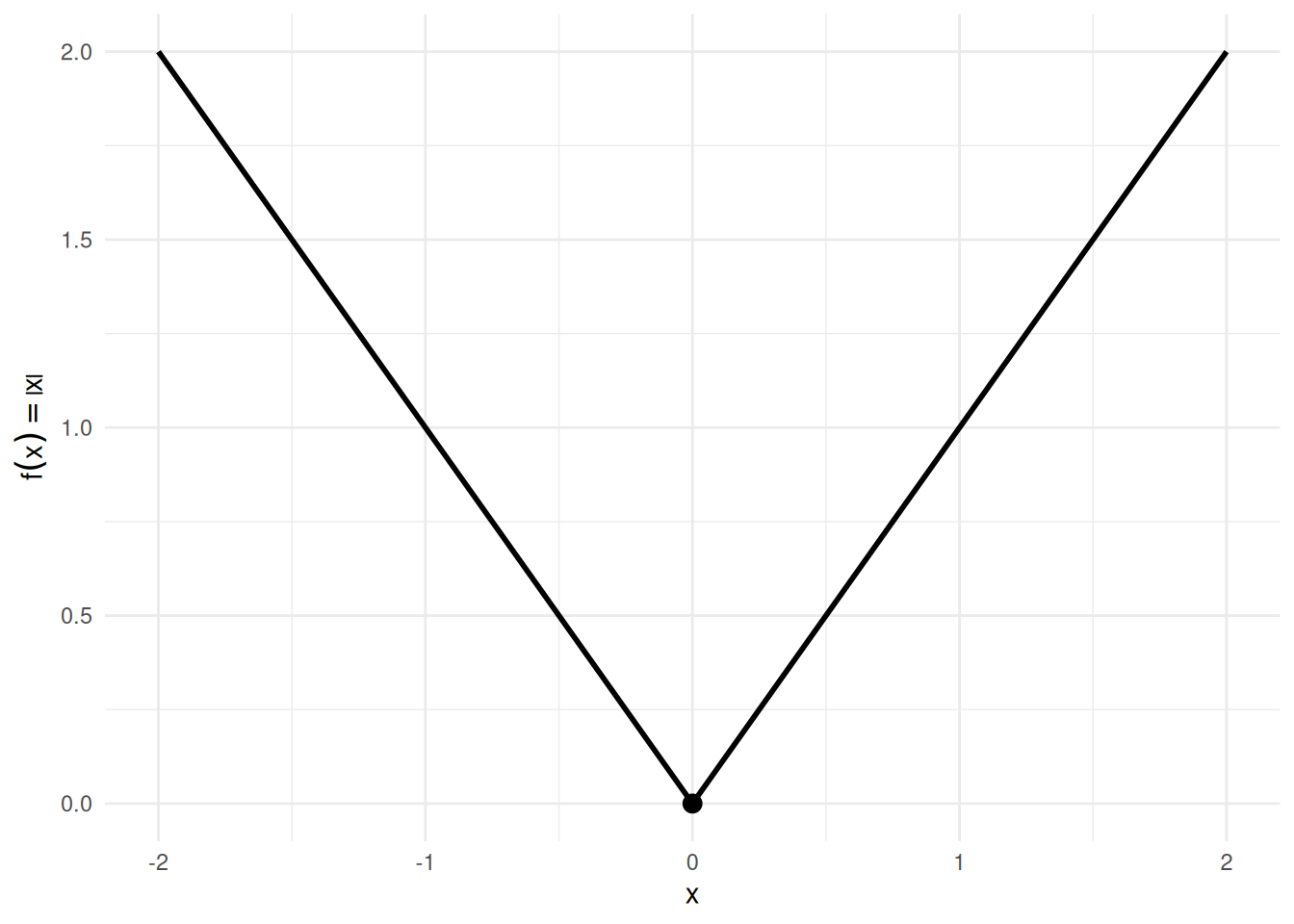
Exm
Example 8 (Integrable but not continuous: a step function) Let \(f(x) = 0\) for \(x < \tfrac{1}{2}\) and \(f(x) = 1\) for \(x \ge \tfrac{1}{2}\). Then \(f\) is discontinuous at \(x = \tfrac{1}{2}\), but it is integrable on \([0, 1]\):
\[ \int_0^1 f(x)\,dx = \int_0^{1/2} 0\,dx + \int_{1/2}^1 1\,dx = 0 + \tfrac{1}{2} = \tfrac{1}{2}. \]
This shows that the converse of Theorem 31 fails: integrability does not imply continuity. See Figure 5.
Show R code
step_df <- data.frame(
x = c(0, 0.5, 0.5, 1),
y = c(0, 0, 1, 1),
segment = c("left", "left", "right", "right")
)
ggplot() +
geom_rect(
aes(xmin = 0.5, xmax = 1, ymin = 0, ymax = 1),
fill = "steelblue", alpha = 0.3
) +
geom_line(
data = step_df,
aes(x = x, y = y, group = segment),
linewidth = 1
) +
geom_point(aes(x = 0.5, y = 0), shape = 1, size = 3) +
geom_point(aes(x = 0.5, y = 1), shape = 16, size = 3) +
scale_x_continuous(breaks = c(0, 0.5, 1), labels = c("0", "1/2", "1")) +
scale_y_continuous(limits = c(-0.1, 1.2)) +
labs(x = "x", y = "f(x)") +
theme_minimal()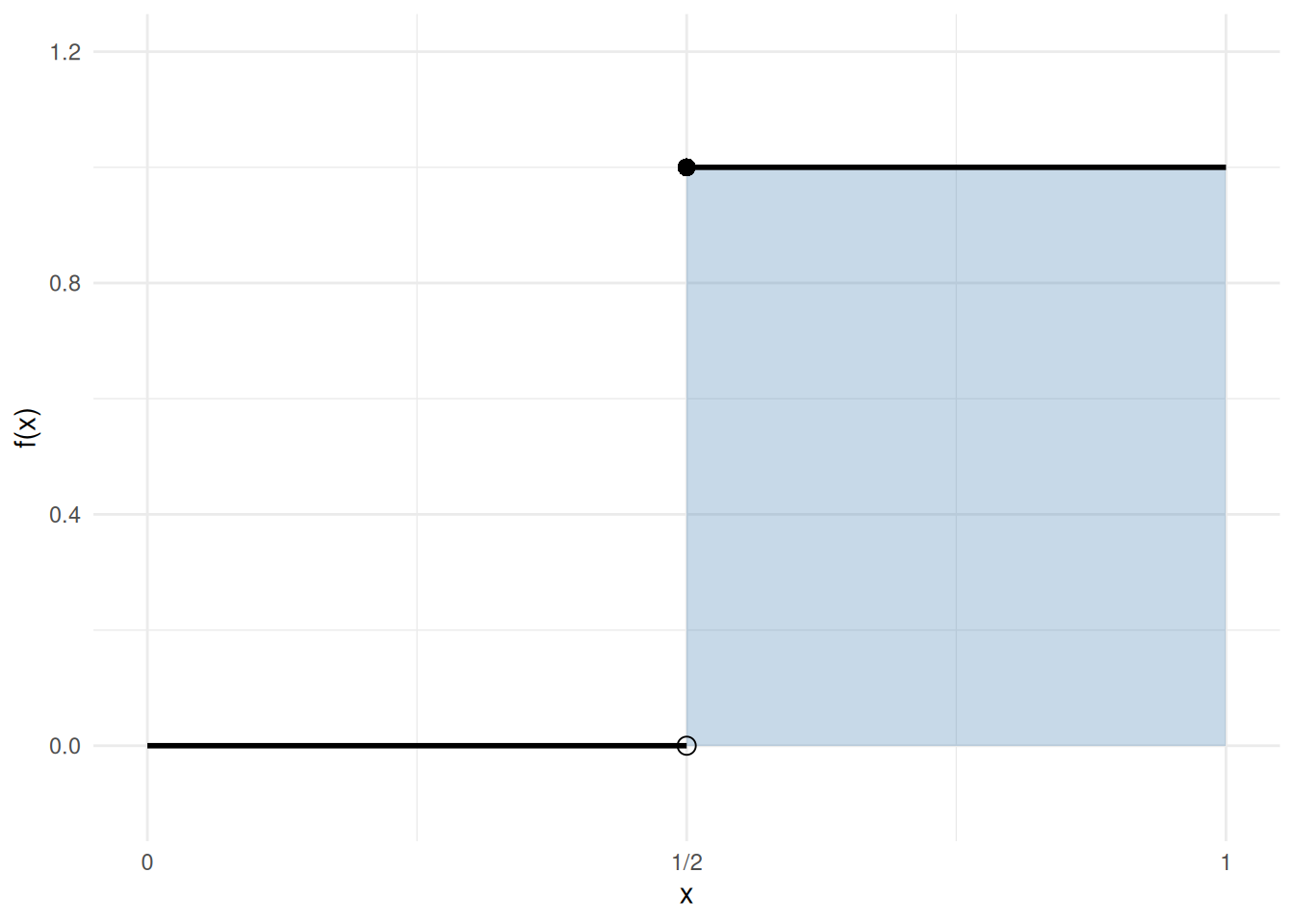
Together, Theorem 30 and Theorem 31 establish the chain:
\[\text{differentiable} \;\Rightarrow\; \text{continuous} \;\Rightarrow\; \text{integrable}\]
Example 6 and Example 8 show that neither implication reverses in general.
3.3 Fundamental Theorem of Calculus
The two parts of the FTC together express that differentiation and integration are inverse operations:
- Part 1: differentiating the integral of \(f\) recovers \(f\) (Equation 2).
- Part 2: the integral of \(f\) over \([a, b]\) equals the difference of any antiderivative’s values at the endpoints (Equation 3), which rearranges to “integrating the derivative of \(F\) recovers the net change in \(F\)” (Equation 4).
The standard form of the FTC assumes \(f\) is continuous on \([a, b]\); continuity is sufficient but not strictly necessary (see the preceding callout note for the more general statement). Since differentiability implies continuity (Theorem 30), the FTC applies in particular whenever \(f\) is differentiable — a common situation in Epi 204.
Exm
Example 9 (FTC Part 1 visualized: accumulation function for \(f(t) = 2t\)) Take \(f(t) = 2t\) on \([0, 2]\). The accumulation function from \(0\) is
\[F(x) \;\stackrel{\text{def}}{=}\; \int_0^x 2t\,dt \;=\; \mathopen{}\left[t^2\right]\mathclose{}_{t=0}^{t=x} \;=\; x^2 - 0^2 \;=\; x^2,\]
so \(F(x) = x^2\), and indeed \(F'(x) = 2x = f(x)\), as Theorem 32 Part 1 predicts. Figure 6 shows the integrand on the left (shaded area equals \(F(x)\) at each \(x\)) and the accumulation function \(F(x) = x^2\) on the right (its slope at \(x\) equals \(f(x) = 2x\)).
Show R code
ggplot() +
geom_area(
data = data.frame(t = seq(0, x_focus, length.out = 200)),
aes(x = t, y = 2 * t),
fill = "steelblue", alpha = 0.4
) +
geom_function(fun = \(t) 2 * t, xlim = c(0, 2.2), linewidth = 1) +
geom_vline(
data = data.frame(x = x_marks),
aes(xintercept = x, color = factor(x)),
linetype = "dashed", linewidth = 0.6
) +
labs(x = "t", y = "f(t) = 2t", color = "x") +
theme_minimal() +
theme(legend.position = "bottom")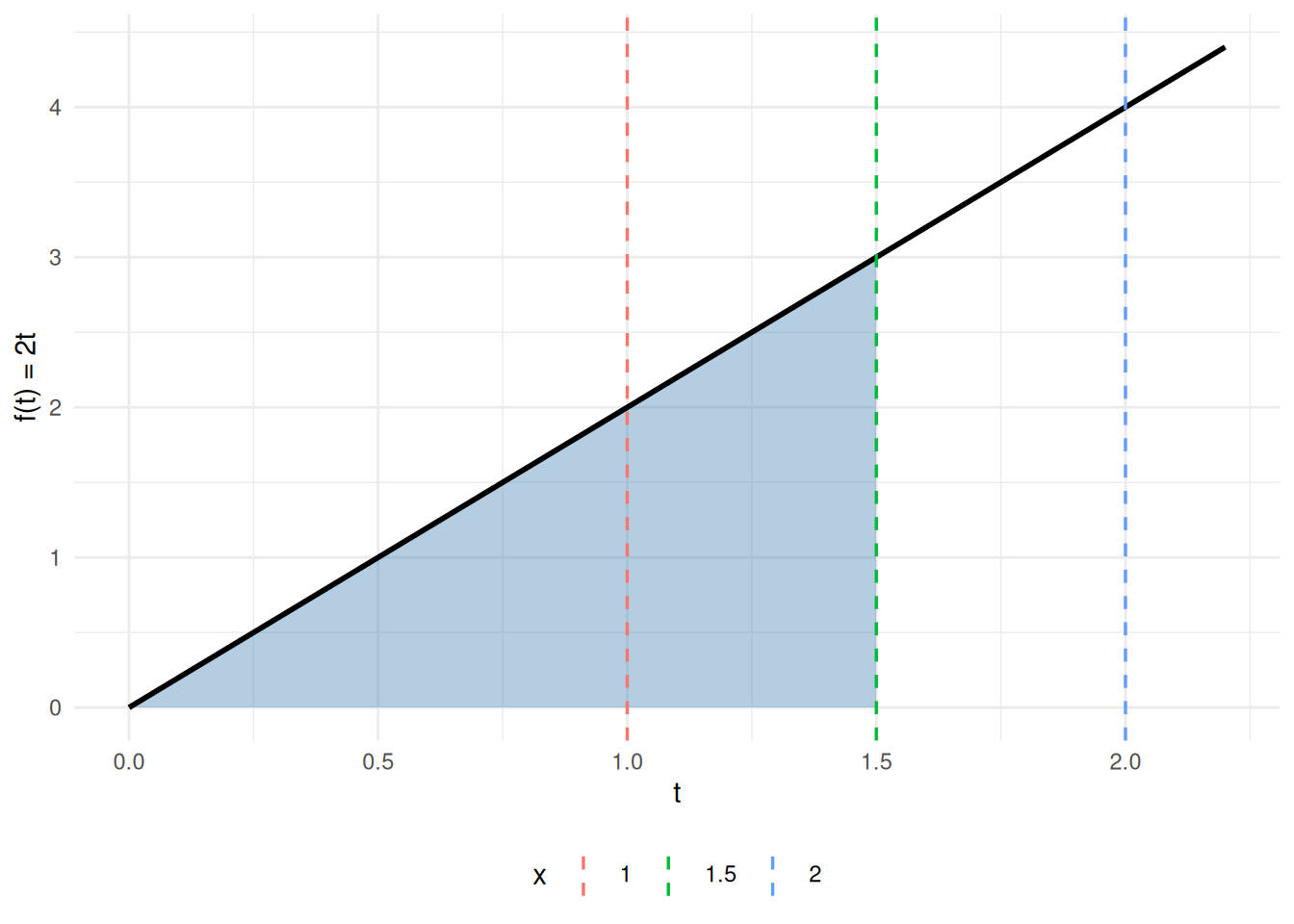
Show R code
slope_df <- data.frame(
x = x_marks,
Fx = x_marks^2,
slope = 2 * x_marks
)
ggplot() +
geom_function(fun = \(x) x^2, xlim = c(0, 2.2), linewidth = 1) +
geom_point(
data = slope_df,
aes(x = x, y = Fx, color = factor(x)),
size = 3
) +
geom_segment(
data = slope_df,
aes(
x = x - 0.3, xend = x + 0.3,
y = Fx - 0.3 * slope, yend = Fx + 0.3 * slope,
color = factor(x)
),
linewidth = 0.8
) +
labs(x = "x", y = expression(F(x) == x^2), color = "x") +
theme_minimal() +
theme(legend.position = "bottom")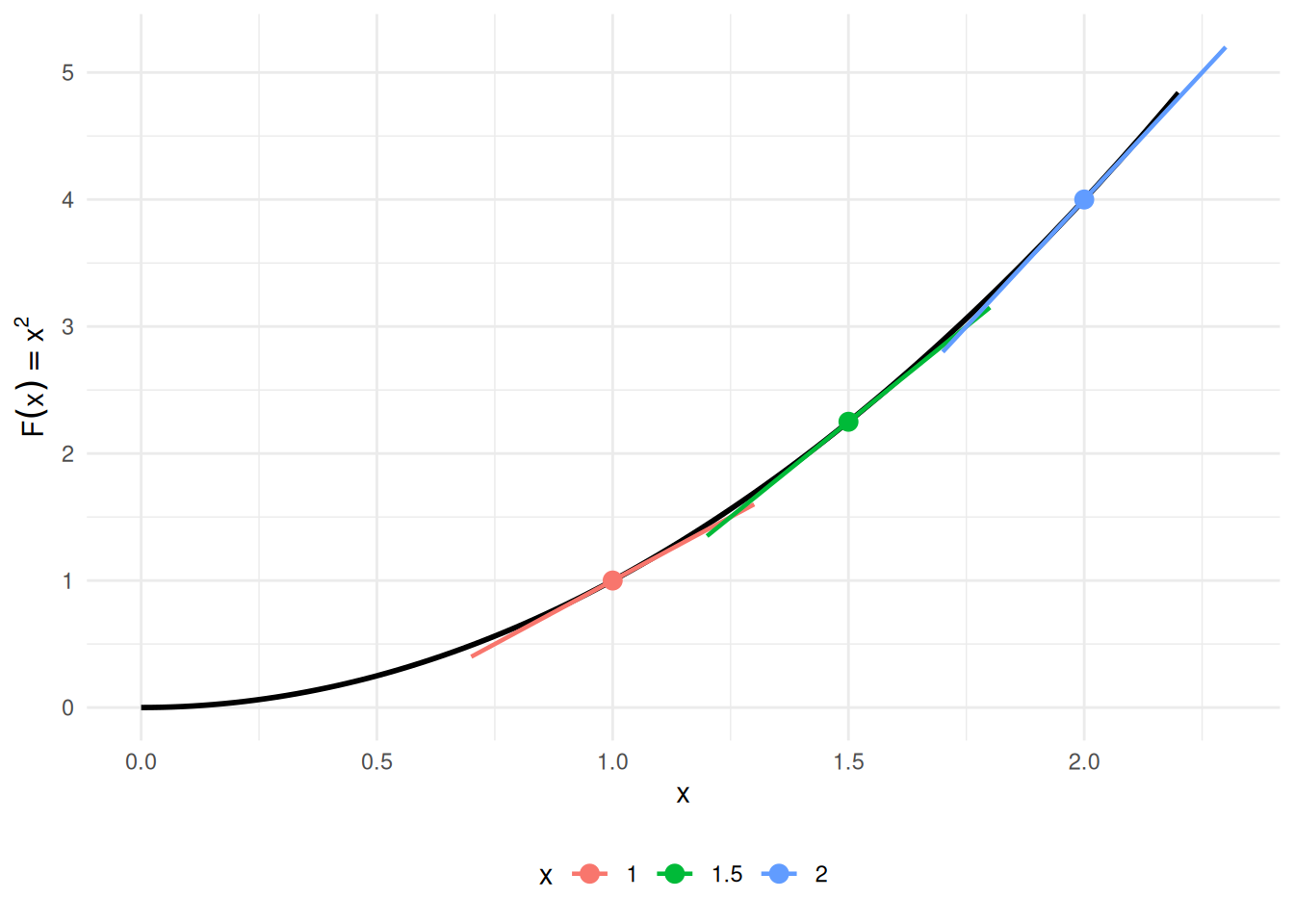
Exm
Example 10 (CDF and PDF of the exponential distribution) In what follows, \(f\) denotes the PDF and \(F\) the CDF — the same letters as the antiderivative pair in Definition 7, because the FTC will show \(F\) is exactly an antiderivative of \(f\).
For the exponential distribution with rate parameter \(\lambda > 0\), the probability density function (PDF) is (Kleinbaum and Klein 2012, sec. II, p. 295, “Survival and Hazard Functions for Selected Distributions”):
\[f(t) = \lambda \text{e}^{-\lambda t}, \quad t \ge 0\]
FTC Part 2 gives the cumulative distribution function (CDF) from the PDF. Apply the \(\text{e}^{cx}\) rule from Theorem 28 with \(c = -\lambda\) to antidifferentiate the integrand:
\[ \begin{aligned} F(t) &= \int_0^t \lambda \text{e}^{-\lambda u}\,du \\ &= \mathopen{}\left[\lambda \cdot\frac{1}{-\lambda}\text{e}^{-\lambda u}\right]\mathclose{}_{u=0}^{u=t} \\ &= \mathopen{}\left[(-1)\text{e}^{-\lambda u}\right]\mathclose{}_{u=0}^{u=t} \\ &= \mathopen{}\left[-\text{e}^{-\lambda u}\right]\mathclose{}_{u=0}^{u=t} \\ &= -\text{e}^{-\lambda t} - \mathopen{}\left(-\text{e}^{0}\right)\mathclose{} \\ &= -\text{e}^{-\lambda t} - (-1) \\ &= 1 - \text{e}^{-\lambda t} \end{aligned} \]
FTC Part 1 recovers the PDF from the CDF:
\[ \begin{aligned} \frac{\partial}{\partial t} F(t) &= \frac{\partial}{\partial t}\mathopen{}\left(1 - \text{e}^{-\lambda t}\right)\mathclose{} \\ &= 0 - (-\lambda)\text{e}^{-\lambda t} \\ &= \lambda\text{e}^{-\lambda t} \\ &= f(t) \end{aligned} \]
For a concrete instance: with \(\lambda = 1\) (standard exponential), the probability that \(T \le 2\) is:
\[ F(2) = 1 - \text{e}^{-1 \cdot 2} = 1 - \text{e}^{-2} \approx 1 - 0.135 = 0.865 \]
See Figure 7.
Show R code
ggplot() +
geom_area(
data = data.frame(t = seq(0, t_focus, length.out = 300)),
aes(x = t, y = lambda * exp(-lambda * t)),
fill = "steelblue", alpha = 0.4
) +
geom_function(
fun = \(t) lambda * exp(-lambda * t),
xlim = c(0, t_max), linewidth = 1
) +
labs(x = "t", y = "f(t)") +
theme_minimal()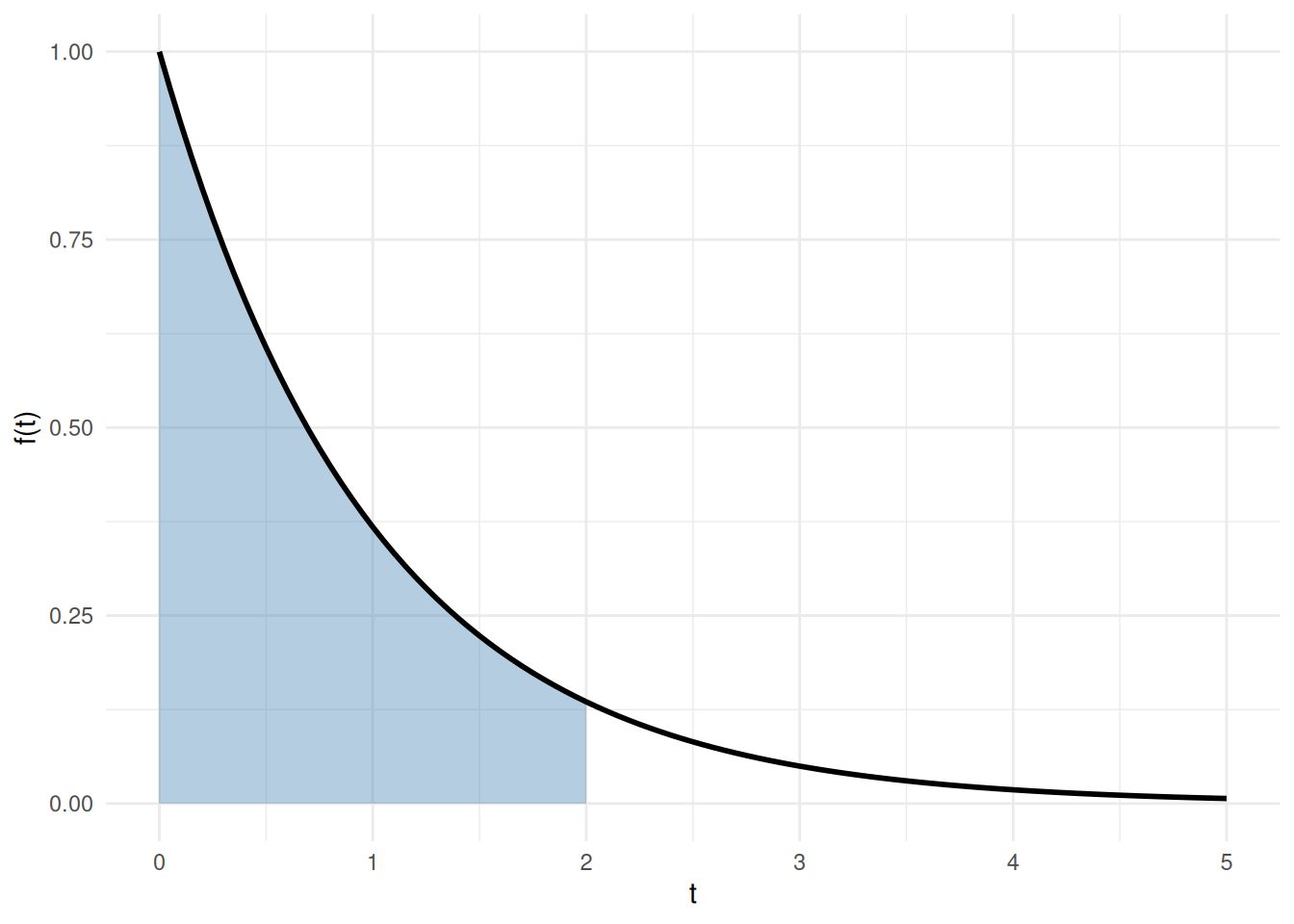
Show R code
ggplot() +
geom_function(
fun = \(t) 1 - exp(-lambda * t),
xlim = c(0, t_max), linewidth = 1
) +
geom_point(
aes(x = t_focus, y = F_at_focus),
size = 3, color = "steelblue"
) +
geom_segment(
aes(x = t_focus, xend = t_focus, y = 0, yend = F_at_focus),
linetype = "dashed", color = "steelblue"
) +
geom_segment(
aes(x = 0, xend = t_focus, y = F_at_focus, yend = F_at_focus),
linetype = "dashed", color = "steelblue"
) +
labs(x = "t", y = "F(t)") +
theme_minimal()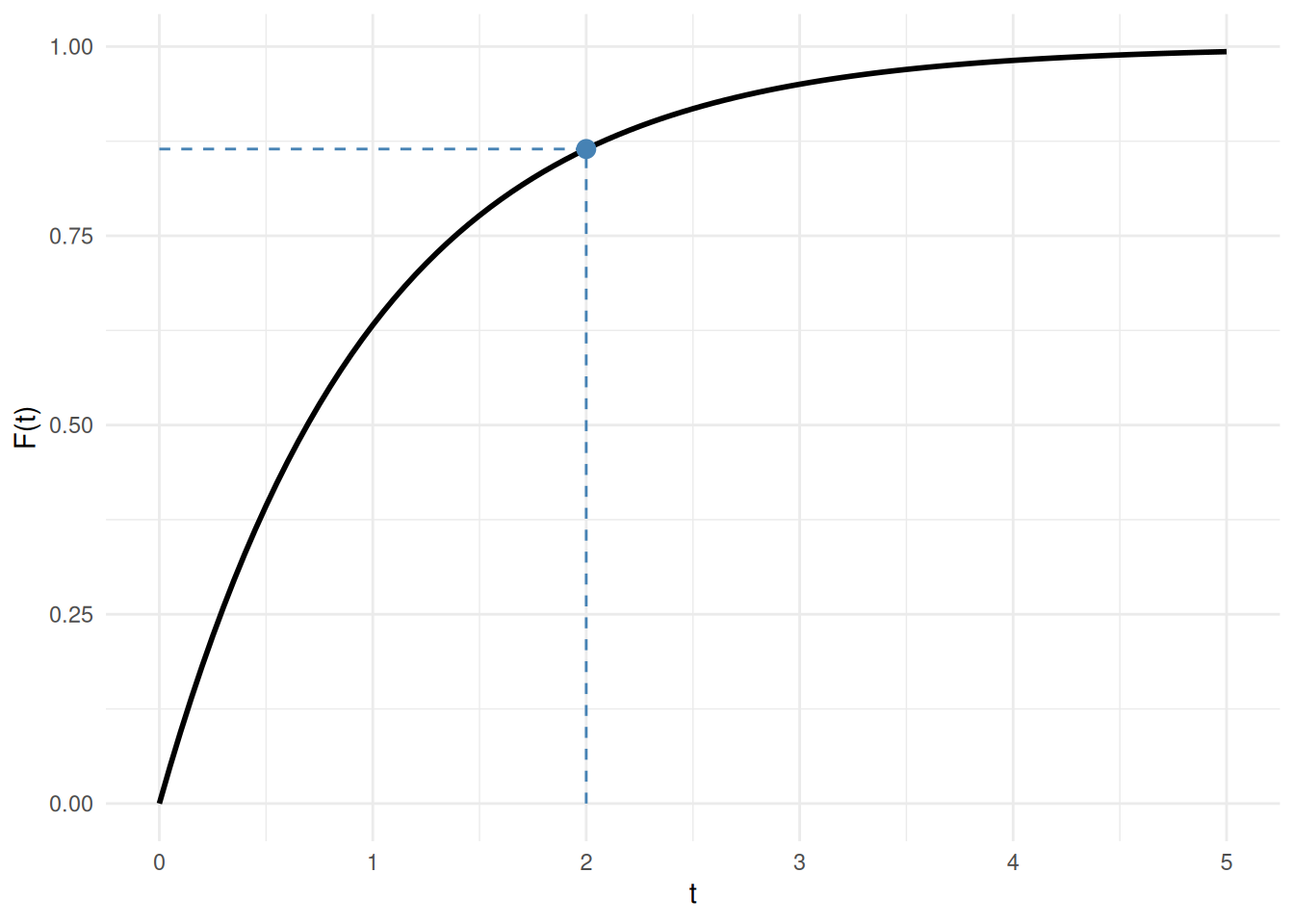
4 Double Integrals
The Fubini–Tonelli theorem states conditions under which the order of integration in a double integral can be exchanged. We state two versions: the Riemann version (Theorem 33) is what Epi 204 directly uses for double integrals of continuous functions on simple regions; the σ-finite measure-theoretic version (Theorem 34) is included to make the joint-distribution form corollary in the probability chapter follow from a stated theorem rather than from an aside.
This generalization is not required for Epi 204 itself, but it is what justifies the joint-distribution form corollary used later in the probability chapter: probability measures are finite (hence σ-finite), so the σ-finiteness hypothesis is automatic. The integrability conditions (nonnegativity or absolute integrability) still need to be verified in each application.
ProofProof
Proof. A closed bounded rectangle \([a, b] \times [c, d]\) is both vertically simple (with \(g_1 \equiv c\), \(g_2 \equiv d\)) and horizontally simple (with \(h_1 \equiv a\), \(h_2 \equiv b\)). Applying both parts of Theorem 33 to \(f\) on this rectangle gives the two iterated forms shown.
5 Linear Algebra
5.1 Vectors
Column vectors are the default convention in these notes and in most statistics textbooks. They are also called \(p \times 1\) matrices.
The transpose operation converts a column vector to a row vector, or more generally, swaps the rows and columns of a matrix (Definition 20).
5.1.1 Special vectors
The zero vector is the additive identity for vector addition: \(\tilde{x}+ \tilde{0}= \tilde{x}\) for any vector \(\tilde{x}\) of the same length.
The dot product \({\tilde{1}}^{\top}\tilde{x}= \tilde{1} \cdot \tilde{x}= \sum_{i=1}^p x_i\) is the sum of all entries of \(\tilde{x}\).
They are also called unit vectors or standard basis vectors.
ProofProof
Proof. Writing the product componentwise:
\[ \begin{aligned} {\tilde{e}_j}^{\top}\tilde{x} &= \sum_{i=1}^{p} (\tilde{e}_j)_i\, x_i \\&= \sum_{i=1}^{p} \begin{cases} 1 \cdot x_i & \text{if } i = j \\ 0 \cdot x_i & \text{if } i \neq j \end{cases} \\&= x_j \end{aligned} \]
Note
See also the definitions in
“Linear combination” can also refer to weighted sums of vectors, or in other words matrix-vector multiplication.
The dot-product has a different generalization for two matrices; see wikipedia for more.
ProofProof
Proof. Apply:
- Definition 16
- symmetry of scalar multiplication
- Definition 16 again
5.1.2 Orthogonality
Orthogonality generalizes the geometric notion of perpendicularity to arbitrary dimensions.
The indicator vectors \(\tilde{e}_1, \tilde{e}_2, \ldots, \tilde{e}_p\) (Definition 15) form an orthonormal set.
5.2 Matrices
The entry in row \(i\) and column \(j\) is denoted \(a_{ij}\) or \((\mathbf{A})_{ij}\). A column vector of length \(p\) is a special case: a \(p \times 1\) matrix. A row vector of length \(p\) is a \(1 \times p\) matrix.
5.2.1 Matrix transpose
The order of the factors reverses when transposing a product.
5.2.2 Matrix addition
5.2.3 Scalar multiplication
5.2.4 Matrix multiplication
Matrix multiplication is only defined when the number of columns in \(\mathbf{A}\) equals the number of rows in \(\mathbf{B}\).
Matrix multiplication is not commutative in general: \(\mathbf{A}\mathbf{B} \neq \mathbf{B}\mathbf{A}\).
5.2.5 Matrix-vector multiplication
Matrix-vector multiplication is a generalization of the dot product. Each entry of the result is a dot product of a row of \(\mathbf{A}\) with the vector \(\tilde{x}\).
5.3 Special Matrices
See also Definition 21 for the zero matrix.
Covariance matrices and information matrices are symmetric.
Diagonal matrices are denoted \(\mathbf{D} = \text{diag}(d_1, d_2, \ldots, d_p)\), where \(d_1, \ldots, d_p\) are the diagonal entries.
A matrix that has an inverse is called invertible or non-singular.
ProofProof
Proof. We verify symmetry and idempotency.
Symmetry: \[{(\mathbf{I} - \mathbf{P})}^{\top} = {\mathbf{I}}^{\top} - {\mathbf{P}}^{\top} = \mathbf{I} - \mathbf{P}\]
Idempotency: \[\begin{aligned} (\mathbf{I} - \mathbf{P})^2 &= (\mathbf{I} - \mathbf{P})(\mathbf{I} - \mathbf{P}) \\ &= \mathbf{I} - \mathbf{P} - \mathbf{P} + \mathbf{P}^2 \\ &= \mathbf{I} - \mathbf{P} - \mathbf{P} + \mathbf{P} \\ &= \mathbf{I} - \mathbf{P} \end{aligned}\]
ProofProof
Proof. We verify symmetry and idempotency.
Symmetry: \[\begin{aligned} {\mathbf{H}}^{\top} &= {\left(\mathbf{X}({\mathbf{X}}^{\top}\mathbf{X})^{-1}{\mathbf{X}}^{\top}\right)}^{\top} \\ &= {({\mathbf{X}}^{\top})}^{\top} \cdot {\left(({\mathbf{X}}^{\top}\mathbf{X})^{-1}\right)}^{\top} \cdot {\mathbf{X}}^{\top} \\ &= \mathbf{X}\cdot ({\mathbf{X}}^{\top}\mathbf{X})^{-1} \cdot {\mathbf{X}}^{\top} \\ &= \mathbf{H} \end{aligned}\]
where the third line uses \({({\mathbf{X}}^{\top})}^{\top} = \mathbf{X}\) and the fact that \({\mathbf{X}}^{\top}\mathbf{X}\) is symmetric, so its inverse is also symmetric (\({\left(({\mathbf{X}}^{\top}\mathbf{X})^{-1}\right)}^{\top} = ({\mathbf{X}}^{\top}\mathbf{X})^{-1}\)).
Idempotency: \[\begin{aligned} \mathbf{H}^2 &= \mathbf{X}({\mathbf{X}}^{\top}\mathbf{X})^{-1}{\mathbf{X}}^{\top} \cdot \mathbf{X}({\mathbf{X}}^{\top}\mathbf{X})^{-1}{\mathbf{X}}^{\top} \\ &= \mathbf{X}({\mathbf{X}}^{\top}\mathbf{X})^{-1}({\mathbf{X}}^{\top}\mathbf{X})({\mathbf{X}}^{\top}\mathbf{X})^{-1}{\mathbf{X}}^{\top} \\ &= \mathbf{X}({\mathbf{X}}^{\top}\mathbf{X})^{-1}{\mathbf{X}}^{\top} \\ &= \mathbf{H} \end{aligned}\]
The hat matrix appears in the formula for fitted values in linear regression: \(\hat{\tilde{y}} = \mathbf{X}\hat{\tilde{\beta}} = \mathbf{X}({\mathbf{X}}^{\top}\mathbf{X})^{-1}{\mathbf{X}}^{\top}\tilde{y}= \mathbf{H}\tilde{y}\). It “puts a hat” on \(\tilde{y}\) — hence the name.
ProofProof
Proof. \[\begin{aligned} {(\mathbf{P}\tilde{v})}^{\top}\,(\mathbf{I} - \mathbf{P})\tilde{v} &= {\tilde{v}}^{\top}\,{\mathbf{P}}^{\top}\,(\mathbf{I} - \mathbf{P})\tilde{v} \\ &= {\tilde{v}}^{\top}\,\mathbf{P}\,(\mathbf{I} - \mathbf{P})\tilde{v} \\ &= {\tilde{v}}^{\top}\,(\mathbf{P} - \mathbf{P}^2)\tilde{v} \\ &= {\tilde{v}}^{\top}\,(\mathbf{P} - \mathbf{P})\tilde{v} \\ &= {\tilde{v}}^{\top}\,\mathbf{0}\,\tilde{v} \\ &= 0 \end{aligned}\]
where the second line uses symmetry (\({\mathbf{P}}^{\top} = \mathbf{P}\)) and the fourth line uses idempotency (\(\mathbf{P}^2 = \mathbf{P}\)).
5.4 Quadratic Forms
Quadratic forms are the matrix generalizations of the scalar expression \(c x^2\). They occur frequently in statistics:
- The residual sum of squares in linear regression (Section 6) is a quadratic form.
- The variance of a linear combination of estimates (?@sec-infer-LMs) is a quadratic form: \(\operatorname{Var}\mathopen{}\left({\tilde{x}}^{\top}\hat{\tilde{\beta}}\right)\mathclose{} = {\tilde{x}}^{\top}\,\operatorname{Var}\mathopen{}\left(\hat{\tilde{\beta}}\right)\mathclose{}\,\tilde{x}\).
5.5 Design Matrix
The product \(\mathbf{X}\tilde{\beta}\) collects all the linear predictors \({\tilde{x}_i}^{\top}\tilde{\beta}\) into a single \(n \times 1\) vector:
\[ \mathbf{X}\tilde{\beta}= \begin{bmatrix} {\tilde{x}_1}^{\top}\tilde{\beta}\\ \vdots \\ {\tilde{x}_n}^{\top}\tilde{\beta} \end{bmatrix} \]
The matrix \({\mathbf{X}}^{\top}\mathbf{X}\) is a \(p \times p\) symmetric matrix that appears in the OLS estimator \(\hat{\tilde{\beta}} = ({\mathbf{X}}^{\top}\mathbf{X})^{-1}{\mathbf{X}}^{\top}\tilde{y}\).
6 Vector Calculus
(adapted from Fieller (2016), §7.2)
This section covers derivatives of functions of vectors and matrices. Linear algebra prerequisites — including vectors, matrices, transpose, dot product, and quadratic forms — are covered in Section 5.
Let \(\tilde{x}\) and \(\tilde{\beta}\) be column vectors of length \(p\) (see Definition 11 and Definition 16).
ProofProof
Proof. \[ \begin{aligned} \frac{\partial}{\partial \beta} (x^{\top}\beta) &= \begin{bmatrix} \frac{\partial}{\partial \beta_1}(x_1\beta_1+x_2\beta_2 +...+x_p \beta_p ) \\ \frac{\partial}{\partial \beta_2}(x_1\beta_1+x_2\beta_2 +...+x_p \beta_p ) \\ \vdots \\ \frac{\partial}{\partial \beta_p}(x_1\beta_1+x_2\beta_2 +...+x_p \beta_p ) \end{bmatrix} \\ &= \begin{bmatrix} x_{1} \\ x_{2} \\ \vdots \\ x_{p} \end{bmatrix} \\ &= \tilde{x} \end{aligned} \]
This is like taking the derivative of \(cx^2\) with respect to \(x\) in non-vector calculus.
This is like taking the derivative of \(x^2\).
See https://quickfem.com/finite-element-analysis/, specifically https://quickfem.com/wp-content/uploads/IFEM.AppF_.pdf
See also https://en.wikipedia.org/wiki/Gradient#Relationship_with_Fr%C3%A9chet_derivative
This chain rule is like the univariate chain rule (Theorem 27), but the order matters now. The version presented here is for the gradient (column vector); the total derivative (row vector) would be the transpose of the gradient.
7 Additional resources
7.1 Calculus
7.2 Linear Algebra and Vector Calculus
7.3 Numerical Analysis
7.4 Real Analysis
- Grinberg (2017)
References
Banerjee, Sudipto, and Anindya Roy. 2014. Linear Algebra and Matrix Analysis for Statistics. Vol. 181. Crc Press Boca Raton. https://www.routledge.com/Linear-Algebra-and-Matrix-Analysis-for-Statistics/Banerjee-Roy/p/book/9781420095388.
Banner, Adrian D. 2007. The Calculus Lifesaver : All the Tools You Need to Excel at Calculus. A Princeton Lifesaver Study Guide. Princeton University Press. https://press.princeton.edu/books/paperback/9780691130880/the-calculus-lifesaver.
Billingsley, Patrick. 1995. Probability and Measure. 3rd ed. Wiley Series in Probability and Mathematical Statistics. Wiley.
Cheng, Eugenia. 2025. “Opinion | How Math Turned Me from a D.E.I. Skeptic to a Supporter.” The New York Times. https://www.nytimes.com/2025/09/05/opinion/math-dei.html.
Dobson, Annette J, and Adrian G Barnett. 2018. An Introduction to Generalized Linear Models. 4th ed. CRC press. https://doi.org/10.1201/9781315182780.
Fieller, Nick. 2016. Basics of Matrix Algebra for Statistics with R. Chapman; Hall/CRC. https://doi.org/10.1201/9781315370200.
Fubini, Guido. 1907. “Sugli Integrali Multipli.” Rendiconti Della Reale Accademia Dei Lincei. Classe Di Scienze Fisiche, Matematiche e Naturali 16: 608–14.
Grinberg, Raffi. 2017. The Real Analysis Lifesaver: All the Tools You Need to Understand Proofs. 1st ed. Princeton Lifesaver Study Guides. Princeton University Press. https://press.princeton.edu/books/paperback/9780691172934/the-real-analysis-lifesaver.
Gut, Allan. 2013. Probability: A Graduate Course. 2nd ed. Springer Texts in Statistics. Springer. https://doi.org/10.1007/978-1-4614-4708-5.
Kaplan, Daniel. 2022. MOSAIC Calculus. Www.mosaic-web.org. www.mosaic-web.org.
Khuri, André I. 2003. Advanced Calculus with Applications in Statistics. John Wiley & Sons. https://www.wiley.com/en-us/Advanced+Calculus+with+Applications+in+Statistics%2C+2nd+Edition-p-9780471391043.
Kleinbaum, David G, and Mitchel Klein. 2012. Survival Analysis: A Self-Learning Text. 3rd ed. Springer. https://link.springer.com/book/10.1007/978-1-4419-6646-9.
Larson, Ron, and Bruce H. Edwards. 2018. Calculus. 11th ed. Cengage Learning. https://www.cengage.com/c/calculus-11e-larson/.
Miller, Steven J. 2016. The Probability Lifesaver: Calculus Review Problems. https://web.williams.edu/Mathematics/sjmiller/public_html/probabilitylifesaver/index.htm#:~:text=http%3A//web.williams.edu/Mathematics/sjmiller/public_html/probabilitylifesaver/supplementalchap_calcreview.pdf.
Rudin, Walter. 1976. Principles of Mathematical Analysis. 3rd ed. International Series in Pure and Applied Mathematics. McGraw-Hill.
Searle, Shayle R, and Andre I Khuri. 2017. Matrix Algebra Useful for Statistics. John Wiley & Sons.
Wikipedia contributors. 2024. Fubini’s Theorem — Wikipedia, the Free Encyclopedia. https://en.wikipedia.org/wiki/Fubini%27s_theorem.