Functions from these packages will be used throughout this document:
[R code]
library(conflicted) # check for conflicting function definitions# library(printr) # inserts help-file output into markdown outputlibrary(rmarkdown) # Convert R Markdown documents into a variety of formats.library(pander) # format tables for markdownlibrary(ggplot2) # graphicslibrary(ggfortify) # help with graphicslibrary(dplyr) # manipulate datalibrary(tibble) # `tibble`s extend `data.frame`slibrary(magrittr) # `%>%` and other additional piping toolslibrary(haven) # import Stata fileslibrary(knitr) # format R output for markdownlibrary(tidyr) # Tools to help to create tidy datalibrary(plotly) # interactive graphicslibrary(dobson) # datasets from Dobson and Barnett 2018library(parameters) # format model output tables for markdownlibrary(haven) # import Stata fileslibrary(latex2exp) # use LaTeX in R code (for figures and tables)library(fs) # filesystem path manipulationslibrary(survival) # survival analysislibrary(survminer) # survival analysis graphicslibrary(KMsurv) # datasets from Klein and Moeschbergerlibrary(parameters) # format model output tables forlibrary(webshot2) # convert interactive content to static for pdflibrary(forcats) # functions for categorical variables ("factors")library(stringr) # functions for dealing with stringslibrary(lubridate) # functions for dealing with dates and timeslibrary(broom) # Summarizes key information about statistical objects in tidy tibbleslibrary(broom.helpers) # Provides suite of functions to work with regression model 'broom::tidy()' tibbles
Here are some R settings I use in this document:
[R code]
rm(list =ls()) # delete any data that's already loaded into Rconflicts_prefer(dplyr::filter)ggplot2::theme_set( ggplot2::theme_bw() +# ggplot2::labs(col = "") + ggplot2::theme(legend.position ="bottom",text = ggplot2::element_text(size =12, family ="serif")))knitr::opts_chunk$set(message =FALSE)options('digits'=6)panderOptions("big.mark", ",")pander::panderOptions("table.emphasize.rownames", FALSE)pander::panderOptions("table.split.table", Inf)conflicts_prefer(dplyr::filter) # use the `filter()` function from dplyr() by defaultlegend_text_size =9run_graphs =TRUE
This course is about generalized linear models (for non-Gaussian outcomes)
UC Davis STA 108 (“Applied Statistical Methods: Regression Analysis”) is a prerequisite for this course, so everyone here should have some understanding of linear regression already.
We will review linear regression to:
make sure everyone is caught up
provide an epidemiological perspective on model interpretation.
1.2 Chapter overview
Section 2: how to interpret linear regression models
Section 3: how to estimate linear regression models
Section 4: how to tell if your model is insufficiently complex
Section 5: how to quantify uncertainty about our estimates and generate predictions
2 Understanding Gaussian Linear Regression Models
2.1 General form of a Gaussian linear regression model
Definition 1 (General form of a Gaussian linear regression model) A Gaussian linear regression model has two components:
Here \(\tilde{x}_i\) is the observed covariate vector for unit \(i\). Here \(\ \sim_{\perp\!\!\!\perp}\ \) means independently distributed. Conditional on \(\tilde{x}_1,\ldots,\tilde{x}_n\), the responses are independent across units, and each \(Y_i|\tilde{x}_i\) follows the same conditional distributional form with common variance \(\sigma^2\) while allowing \(\mu_i\) to vary by observation.
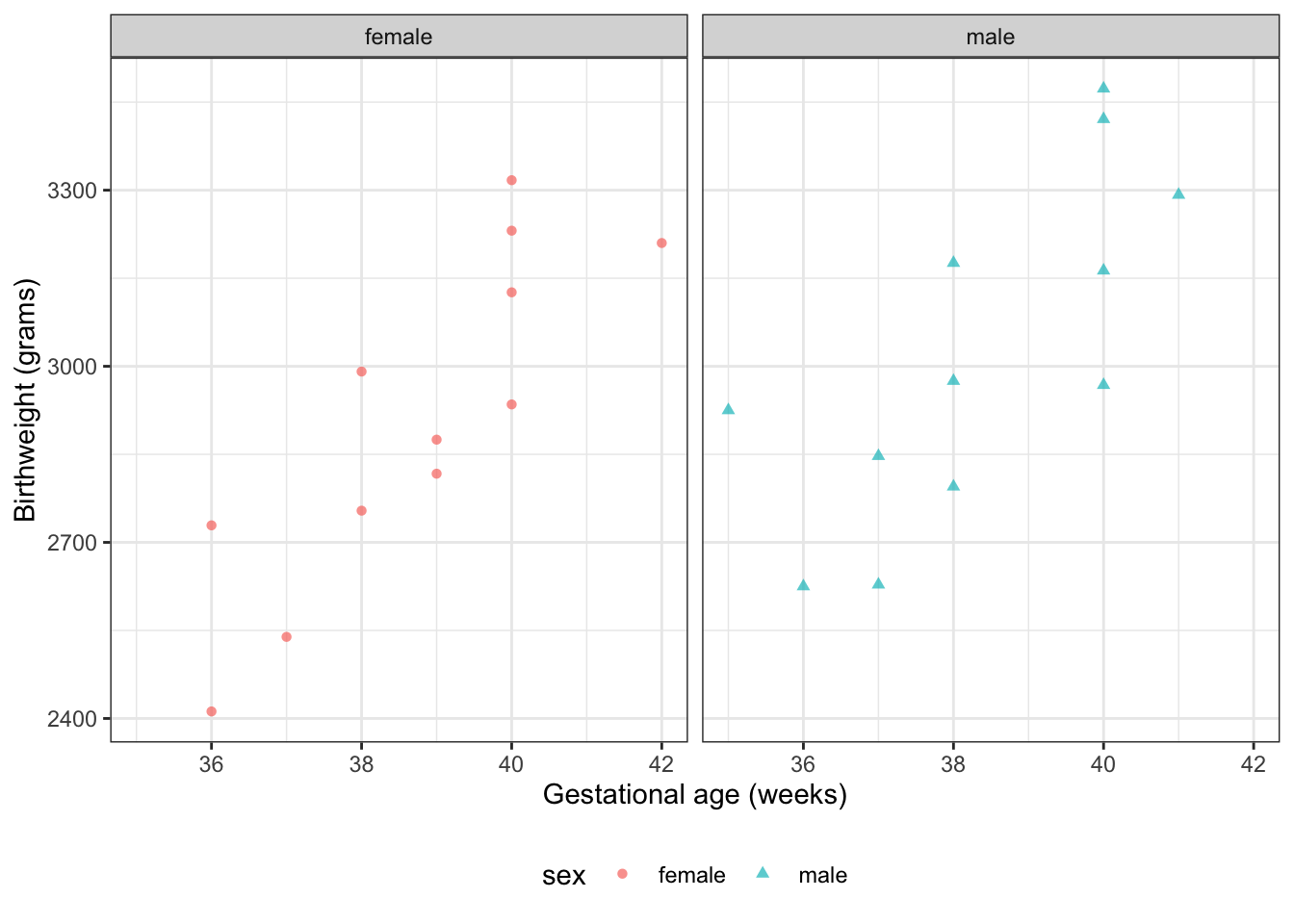
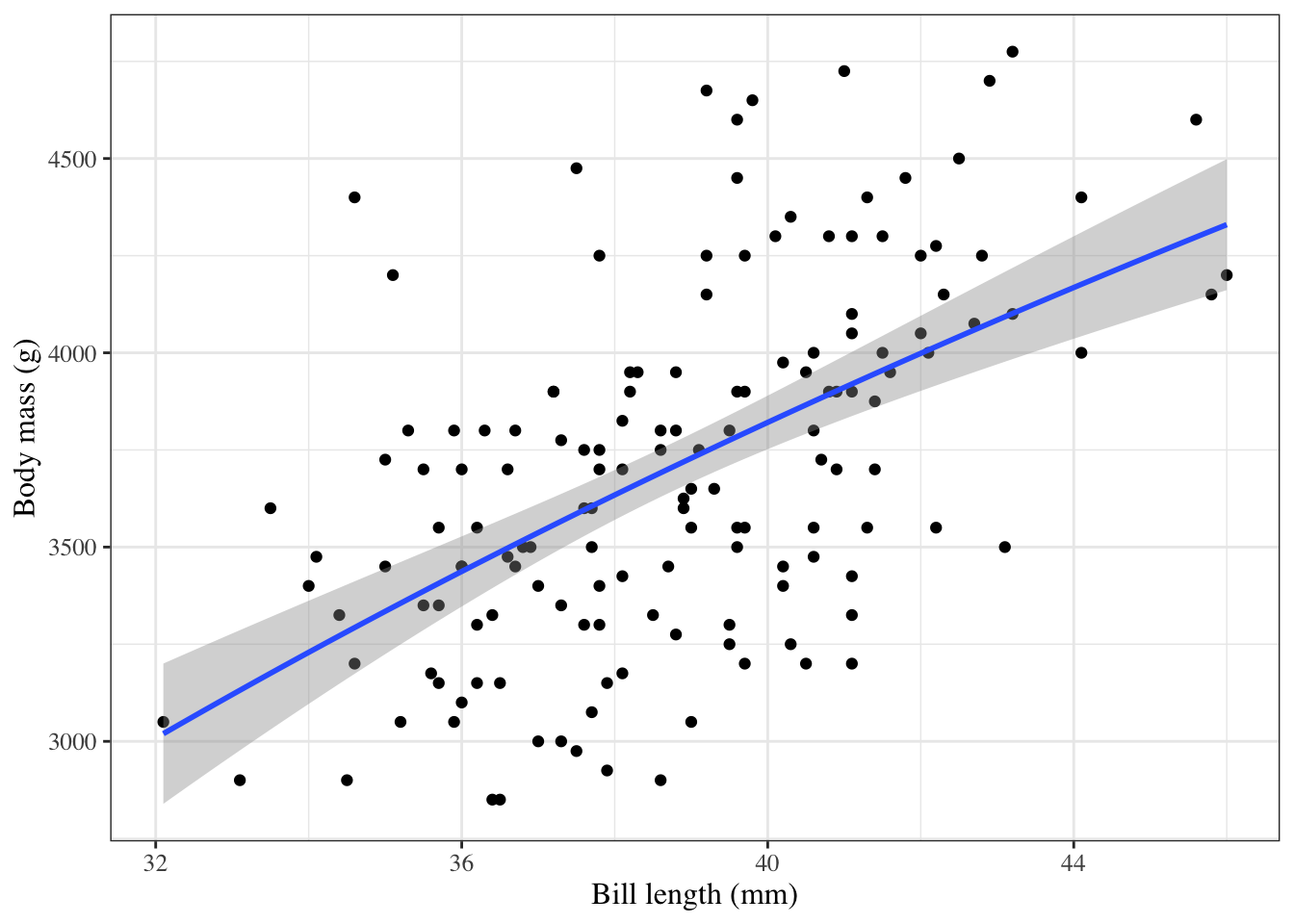
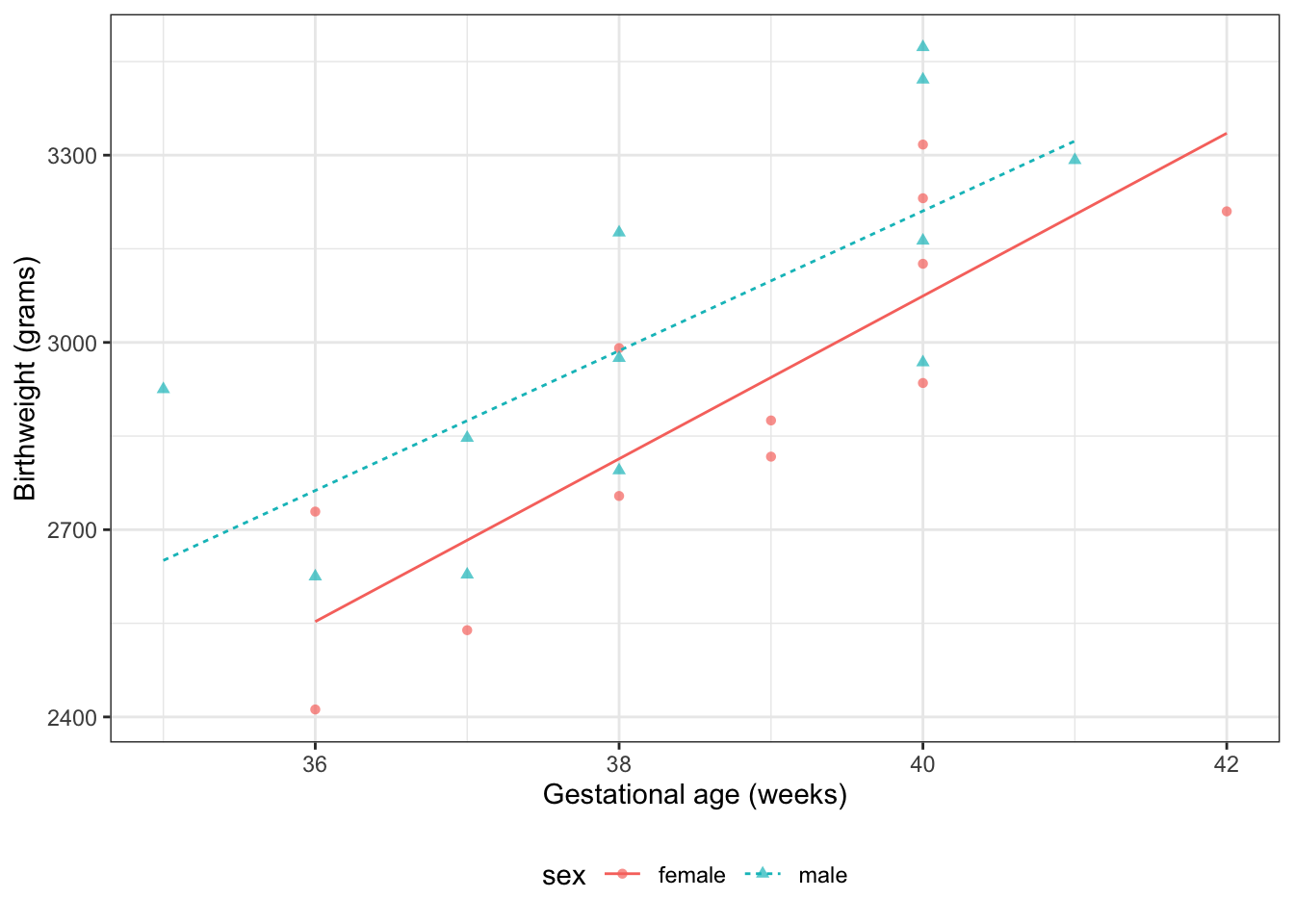
2.2 Motivating example: birthweights and gestational age
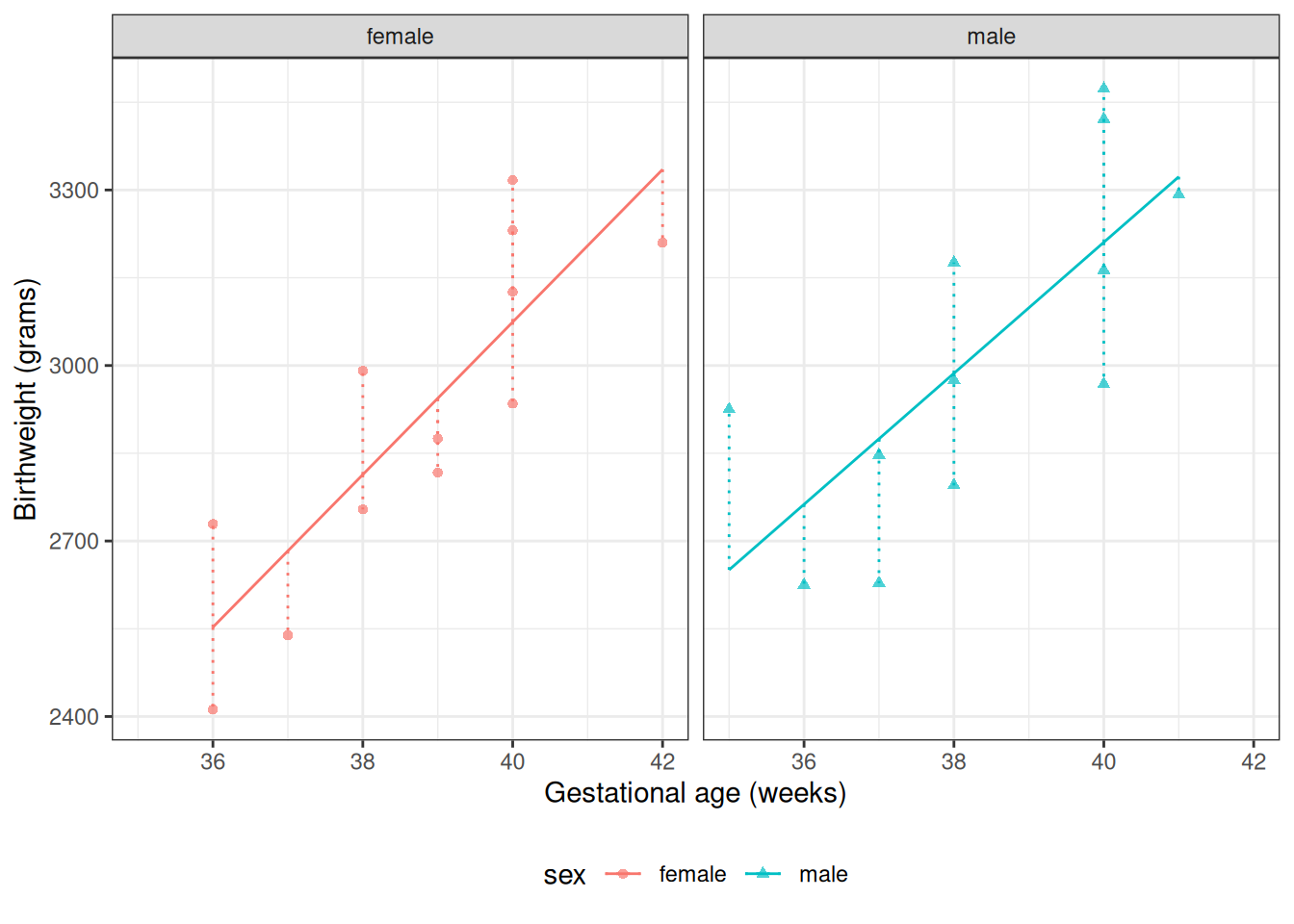
Suppose we want to learn about the distributions of birthweights (outcome\(Y\)) for (human) babies born at different gestational ages (covariate\(A\)) and with different chromosomal sexes (covariate\(S\)) (Dobson and Barnett (2018) Example 2.2.2).
pred_female <-coef(bw_lm1)["(Intercept)"] +coef(bw_lm1)["age"] *36## or using built-in prediction:pred_female_alt <-predict(bw_lm1, newdata =tibble(sex ="female", age =36))
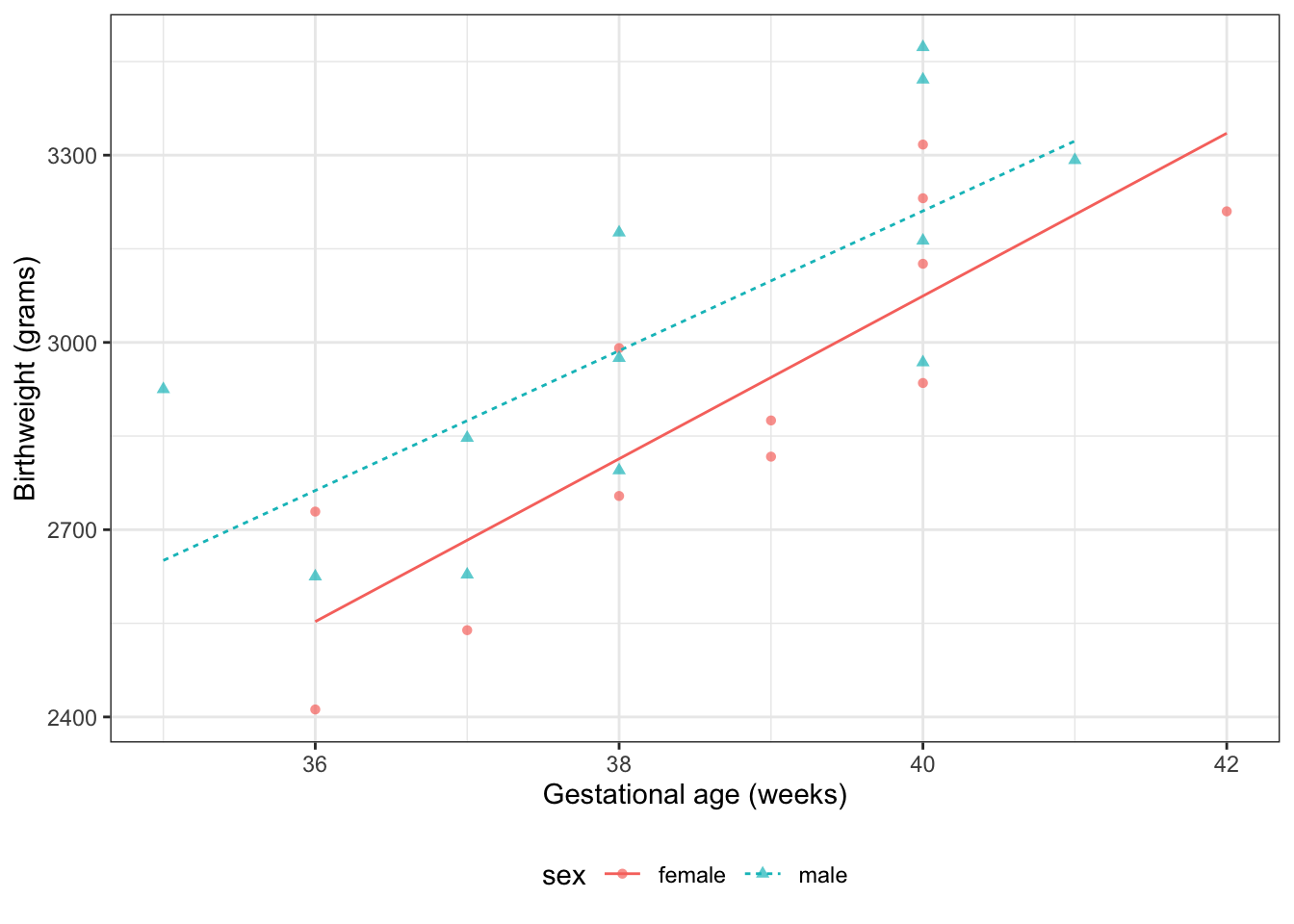
Exercise 10 What is the interpretation of \(\beta_{M}\) in Model 2?
Solution.
Mean birthweight among males with gestational age 0 weeks: \[
\begin{aligned}
\mu(1,0) &= \text{E}{\left[Y|M = 1,A = 0\right]}\\
&= \beta_0 + {\color{red}\beta_M} \cdot 1 + \beta_A \cdot 0 + \beta_{AM}\cdot 1 \cdot 0\\
&= \beta_0 + {\color{red}\beta_M}
\end{aligned}
\] Mean birthweight among females with gestational age 0 weeks: \[
\begin{aligned}
\mu(0,0) &= \text{E}{\left[Y|M = 0,A = 0\right]}\\
&= \beta_0 + {\color{red}\beta_M} \cdot 0 + \beta_A \cdot 0 + \beta_{AM}\cdot 0 \cdot 0\\
&= \beta_0
\end{aligned}
\]
\[
\begin{aligned}
\beta_{M} &= \mu(1,0) - \mu(0,0) \\
&= \text{E}{\left[Y|M = 1,A = 0\right]} - \text{E}{\left[Y|M = 0,A = 0\right]}
\end{aligned}
\]\(\beta_M\) is the difference in mean birthweight between males with gestational age 0 weeks and females with gestational age 0 weeks.
Exercise 11 What is the interpretation of \(\beta_{AM}\) in Model 2?
Let the coefficients of this model be \(\gamma\)s instead of \(\beta\)s.
What are the interpretations of the \(\gamma\)s? How do they relate to the \(\beta\)s in Model 2? Which have the same interpretation? Which are different, and how do they differ? What is the pattern?
Solution. Interpretation of \(\gamma_0\):
From Model 4, \(\gamma_0\) is the mean birthweight among females (\(M = 0\)) with \(A^* = 0\) (i.e., \(A = 32\) weeks):
Since shifting \(A\) by a constant does not change the slope, \(\gamma_{A^*} = \beta_A\): these two coefficients have the same value and interpretation.
Interpretation of \(\gamma_{A^*M}\):
From Model 4, \(\gamma_{A^*M}\) is the difference in slope with respect to \(A^*\) between males and females:
Since shifting \(A\) by a constant does not change slopes, \(\gamma_{A^*M} = \beta_{AM}\): these two coefficients have the same value and interpretation.
The pattern:
Slope coefficients (\(\gamma_{A^*}\) and \(\gamma_{A^*M}\)) are unchanged by rescaling: they have the same values and interpretations as the corresponding \(\beta\)s.
Coefficients change only for variables that have interactions with the rescaled variable \(A\). This includes the intercept (which can be viewed as the main effect of a variable that interacts with \(A\) via \(\beta_A\)), and the main effect of \(M\) (which interacts with \(A\) via \(\beta_{AM}\)). Shifting \(A\) by 32 weeks changes the reference point from \(A = 0\) to \(A = 32\), so these coefficients now represent quantities evaluated at \(A = 32\) weeks rather than at \(A = 0\) weeks.
Exercise 13 Using R, fit the rescaled interaction model with \(A^* = A - 36\) weeks in place of \(A\) in Model 2. Compare the coefficient estimates with those from the original model. Which coefficients change, and which remain the same?
Solution.
[R code]
bw <- bw |>mutate(`age - mean`= age -mean(age),`age - 36wks`= age -36 )lm1_c <-lm(weight ~ sex +`age - 36wks`, data = bw)lm2_c <-lm(weight ~ sex +`age - 36wks`+ sex:`age - 36wks`, data = bw)parameters(lm2_c, ci_method ="wald") |>print_md()
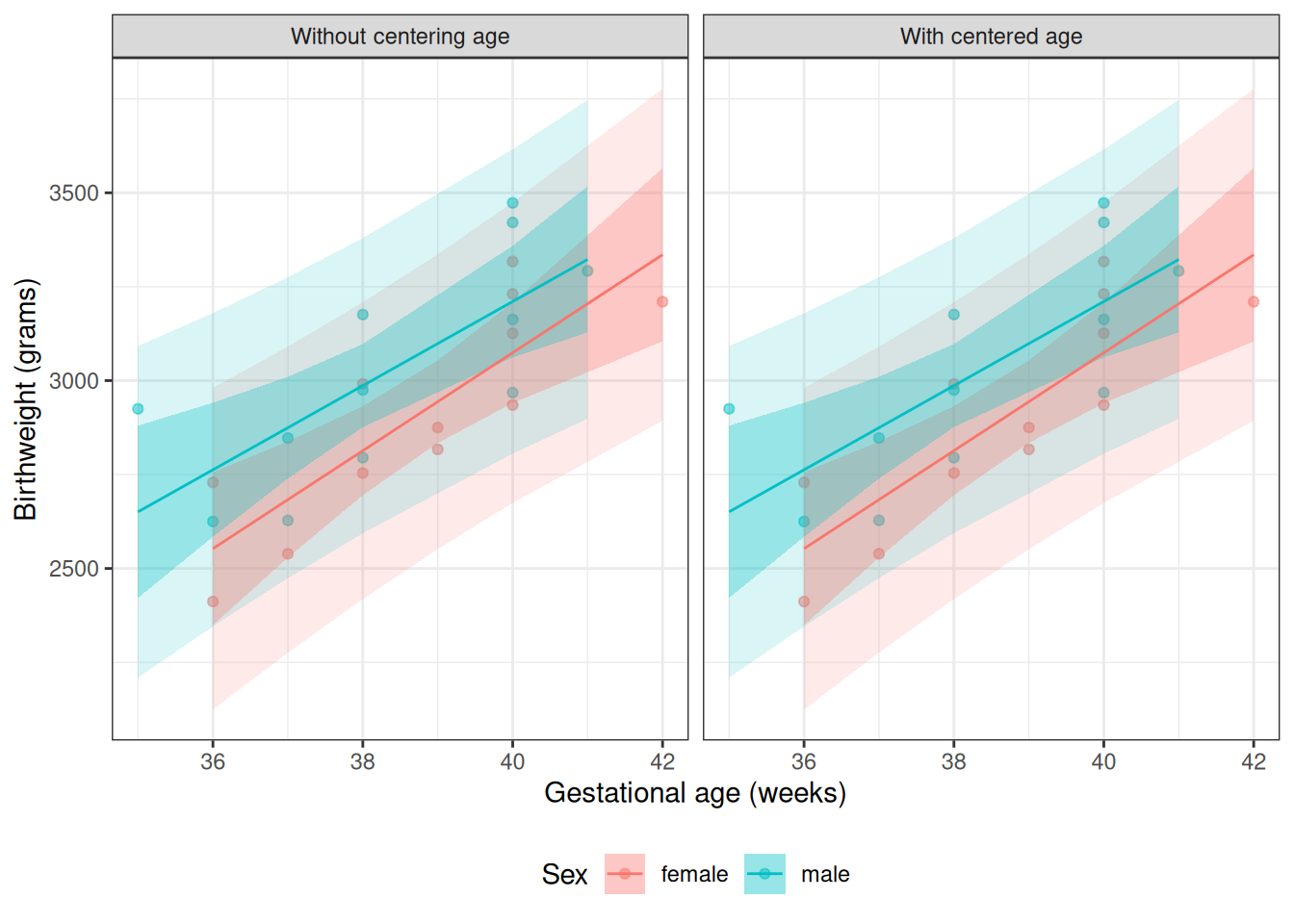
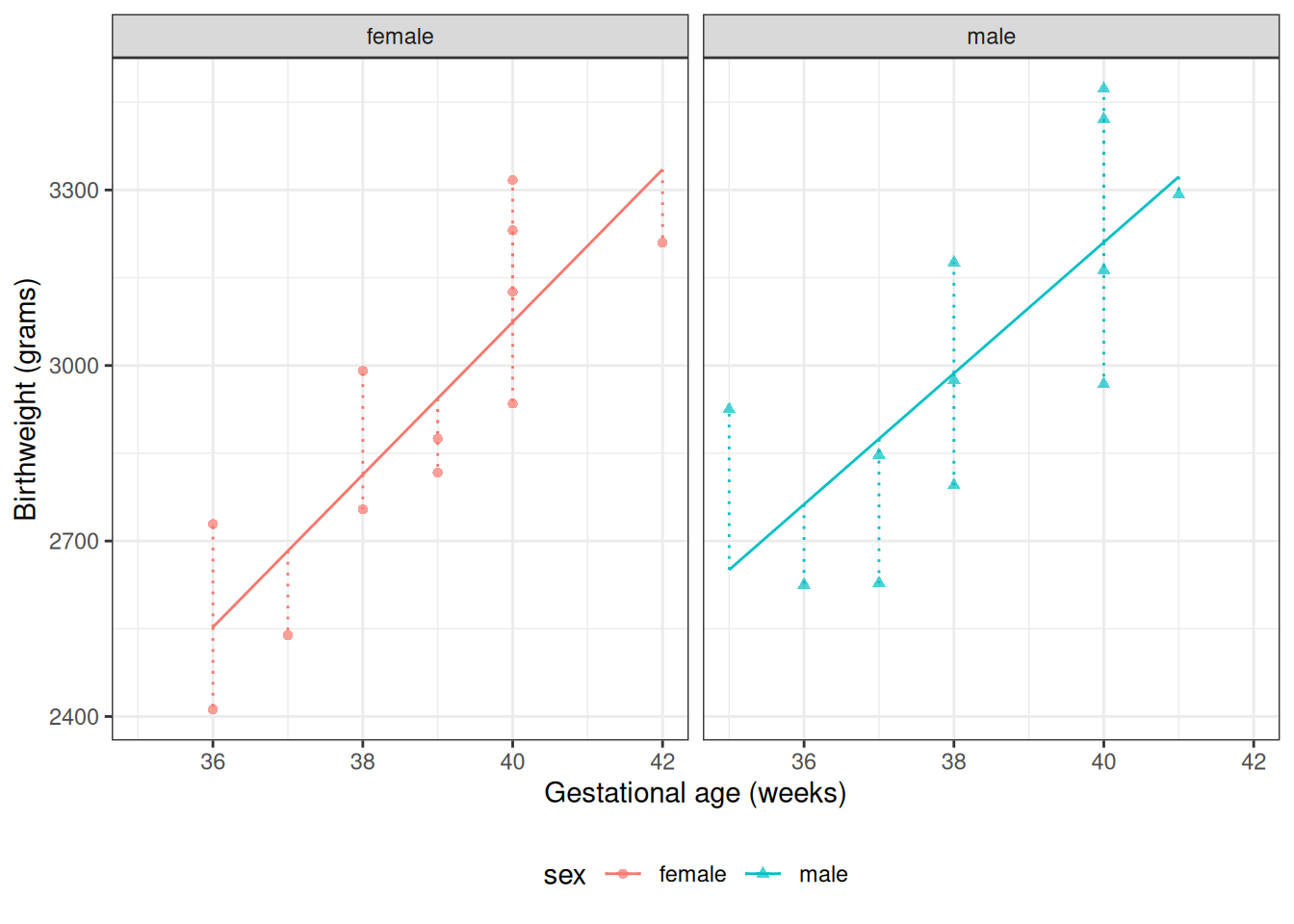
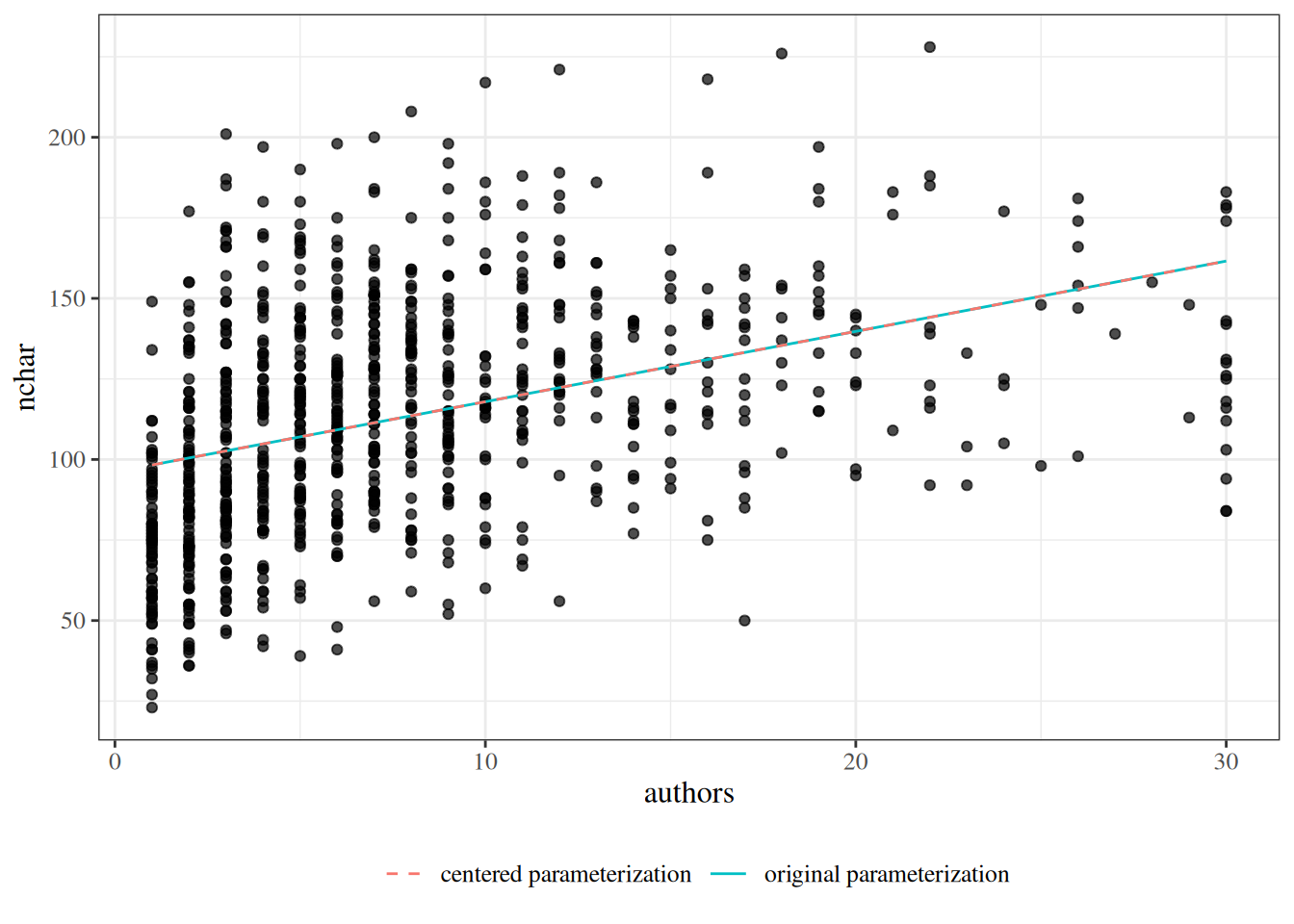
Centering gestational age does not change predictions
Centering gestational age changes the coefficient parameterization, but it does not change fitted values, confidence bands, or prediction bands.
The next output reports maximum absolute differences between the uncentered and centered models. All values should be near zero (up to floating-point rounding), which confirms that centering changes parameterization only.
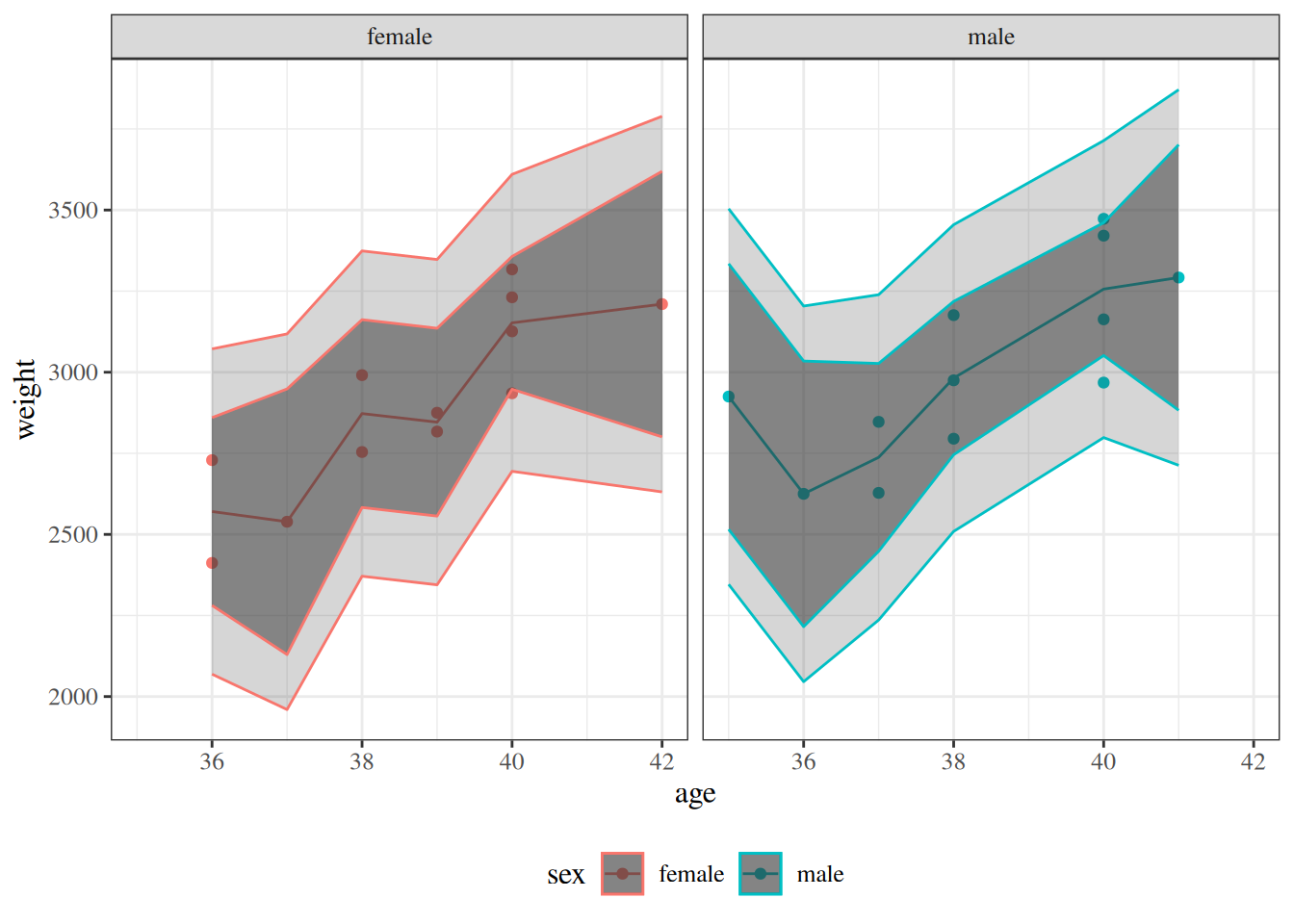
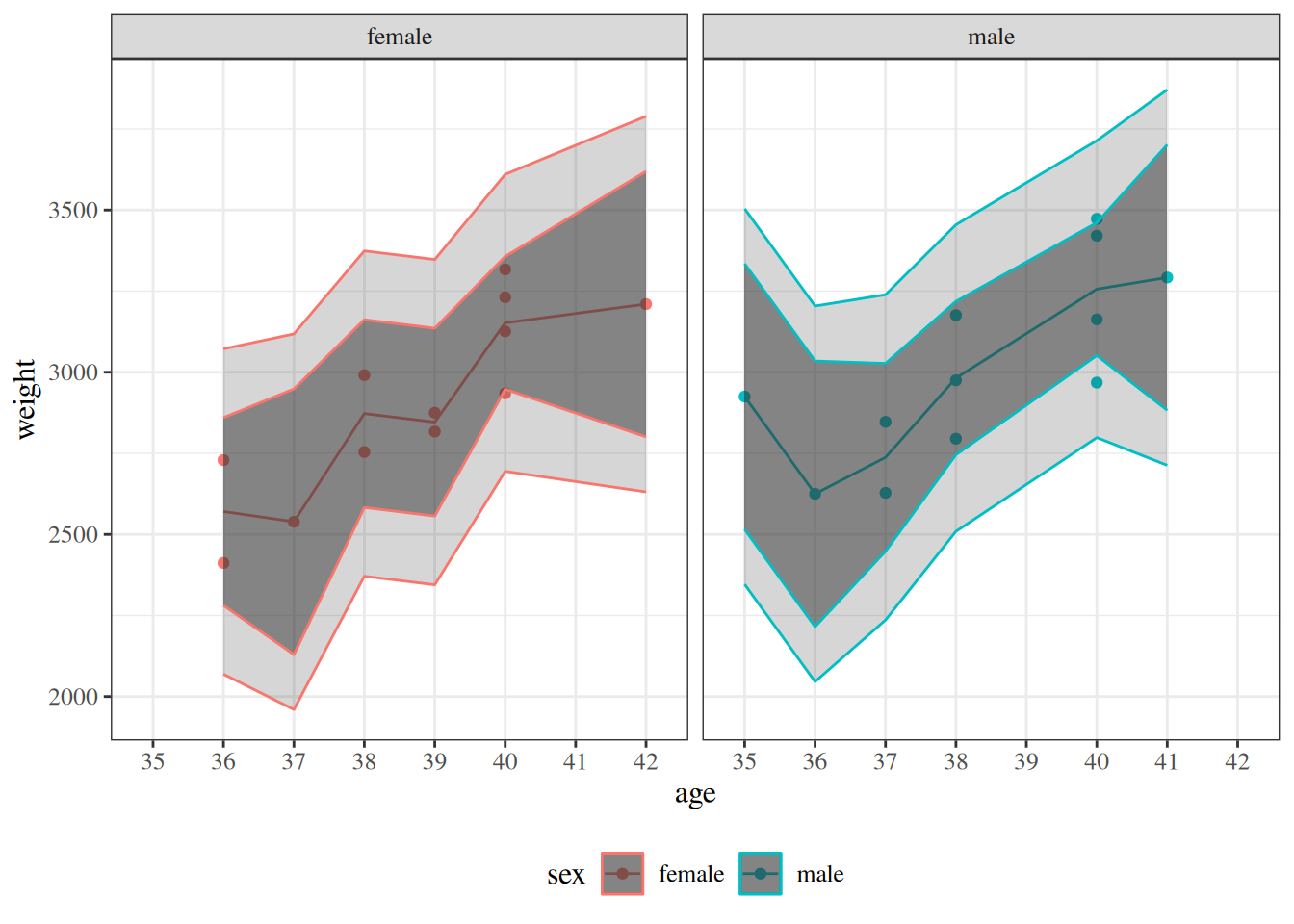
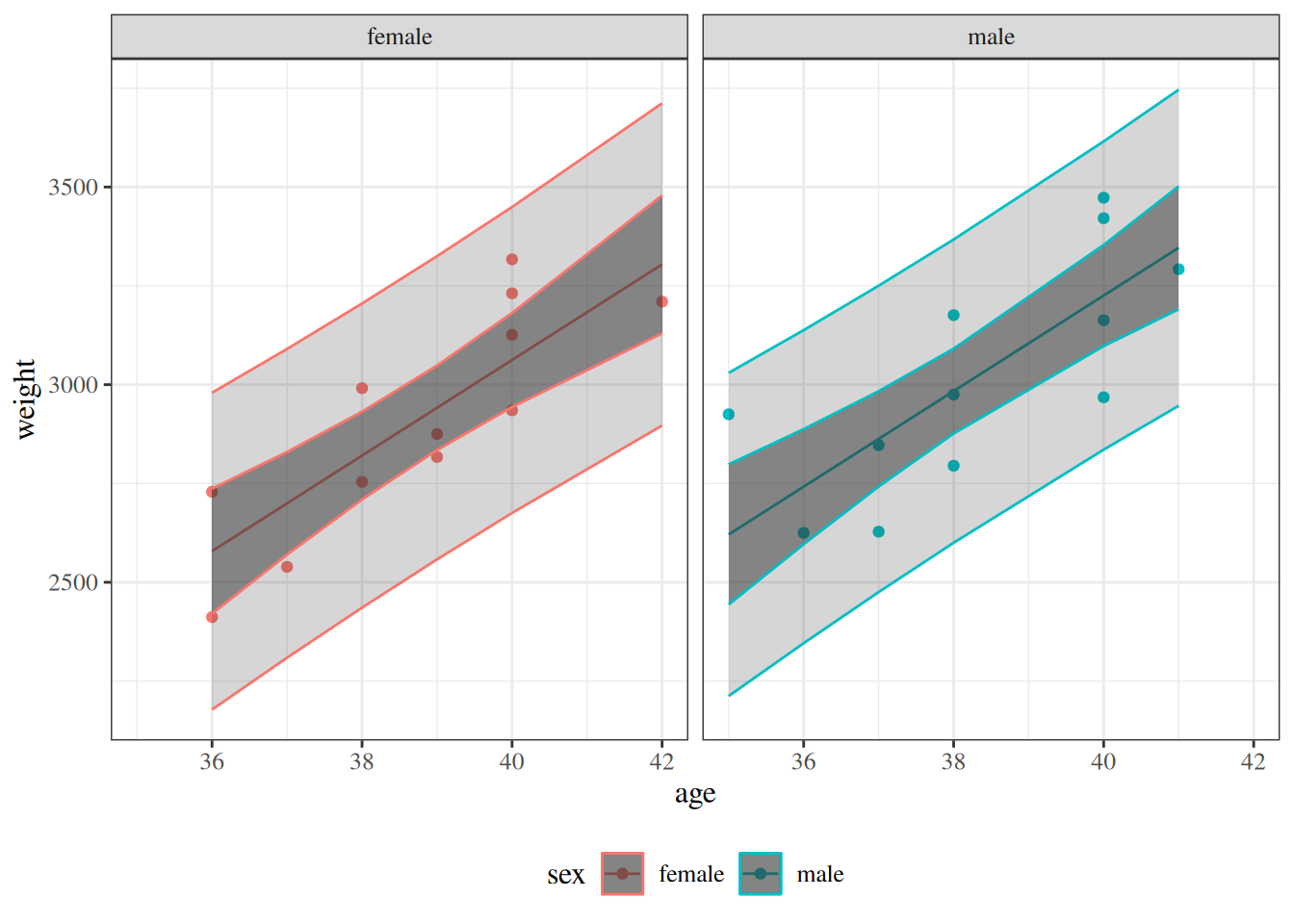
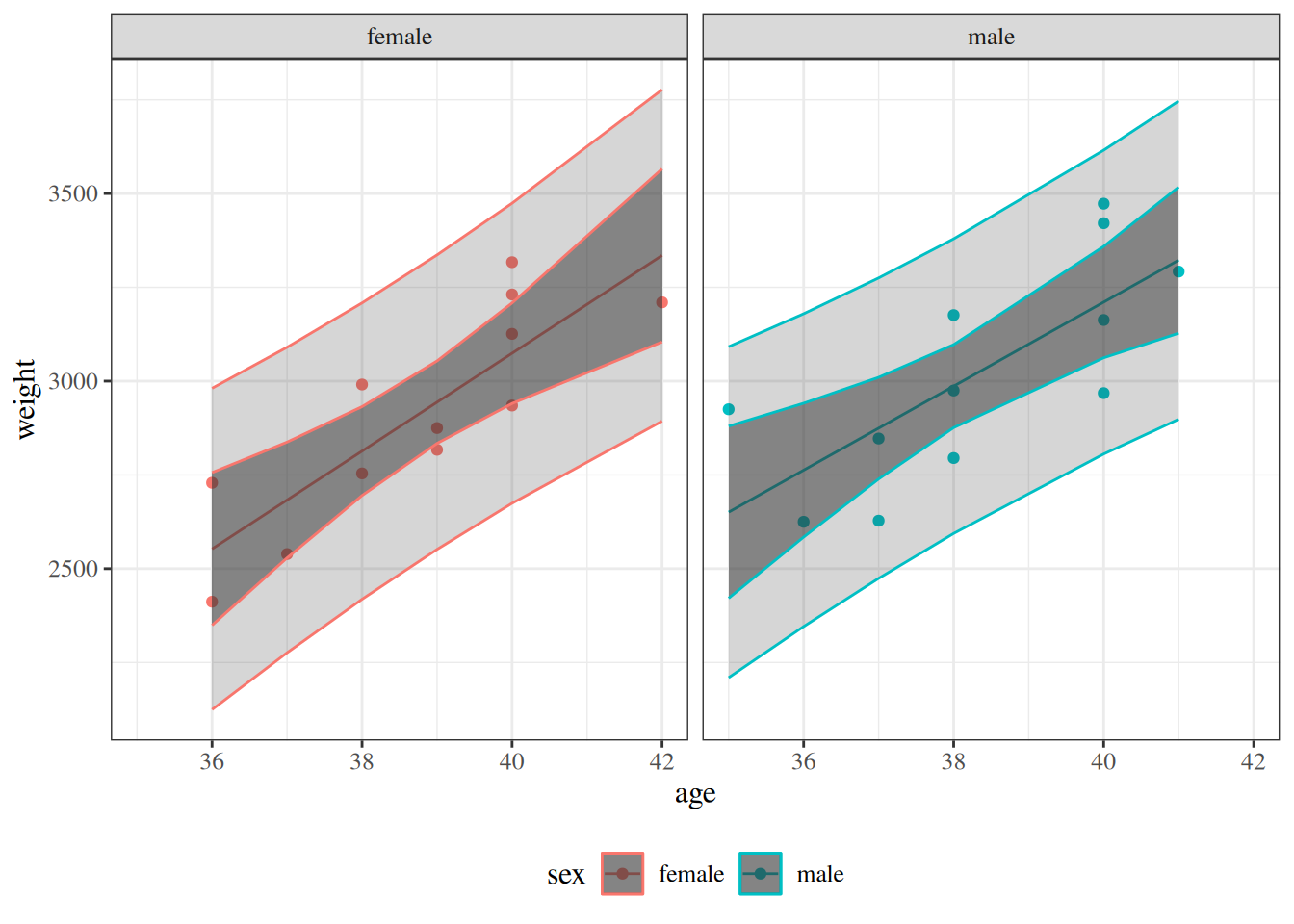
Figure 6: Two-panel comparison of the fitted birthweight model bw_lm2 with and without centering gestational age, showing identical fitted values, confidence bands, and prediction bands in both panels.
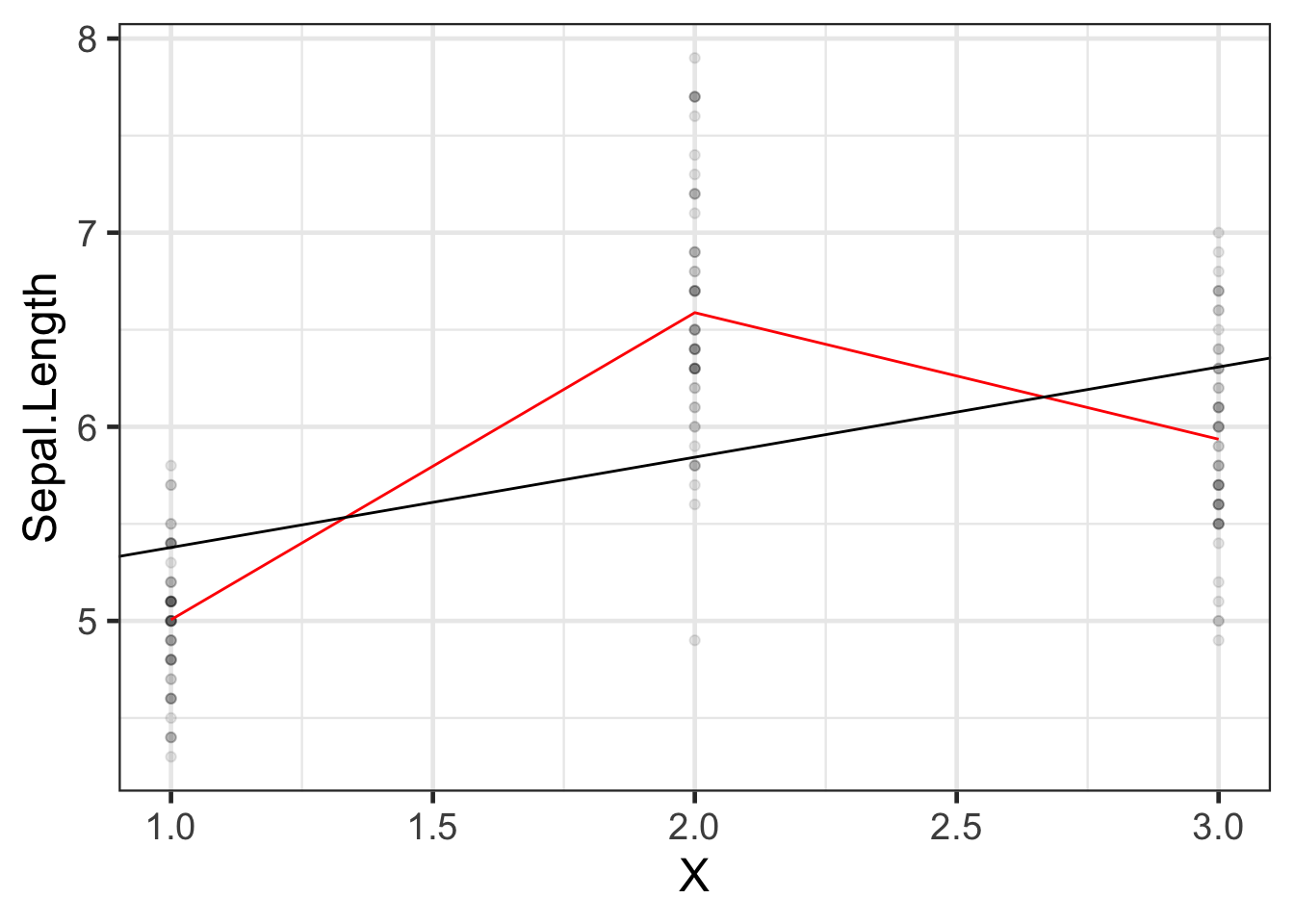
2.9 Categorical covariates with more than two levels
Example: birthweight
In the birthweight example, the variable sex had only two observed values:
[R code]
unique(bw$sex)#> [1] female male #> Levels: female male
If there are more than two observed values, we can’t just use a single variable with 0s and 1s.
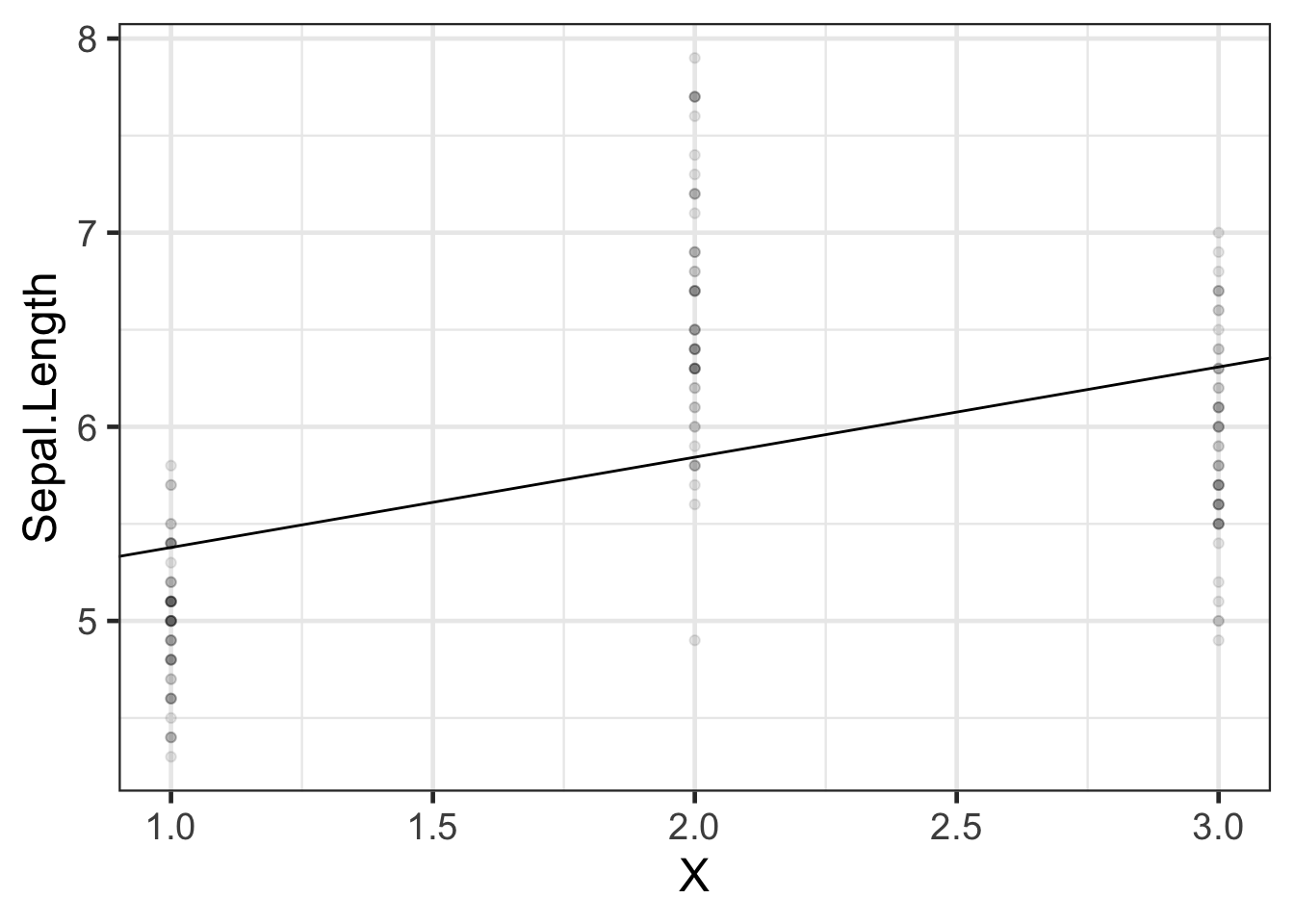
If we want to model Sepal.Length by species, we could create a variable \(X\) that represents “setosa” as \(X=1\), “virginica” as \(X=2\), and “versicolor” as \(X=3\).
[R code]
data(iris) # this step is not always necessary, but ensures you're starting# from the original version of a dataset stored in a loaded packageiris <- iris |>tibble() |>mutate(X =case_when( Species =="setosa"~1, Species =="virginica"~2, Species =="versicolor"~3 ) )iris |>distinct(Species, X)
Table 10: iris data with numeric coding of species
Then we could fit a model like:
[R code]
iris_lm1 <-lm(Sepal.Length ~ X, data = iris)iris_lm1 |>parameters() |>print_md()
Table 11: Model of iris data with numeric coding of Species
Assume the design matrix \(\mathbf{X}\) has full column rank. This implies that \(\sum_{i=1}^n \tilde{x}_i {\tilde{x}_i}^{\top}\) is invertible. To solve for \(\tilde{\beta}\), use \(\tilde{x}_i (\tilde{x}_i \cdot \tilde{\beta}) = (\tilde{x}_i {\tilde{x}_i}^{\top})\tilde{\beta}\):
\(\ell_{\beta, \beta'} ''(\beta, \sigma^2;\mathbf X,\tilde{y})\) is negative definite at \(\beta = (\mathbf{X}'\mathbf{X})^{-1}X'y\), so \(\hat \beta_{ML} = (\mathbf{X}'\mathbf{X})^{-1}X'y\) is the MLE for \(\beta\).
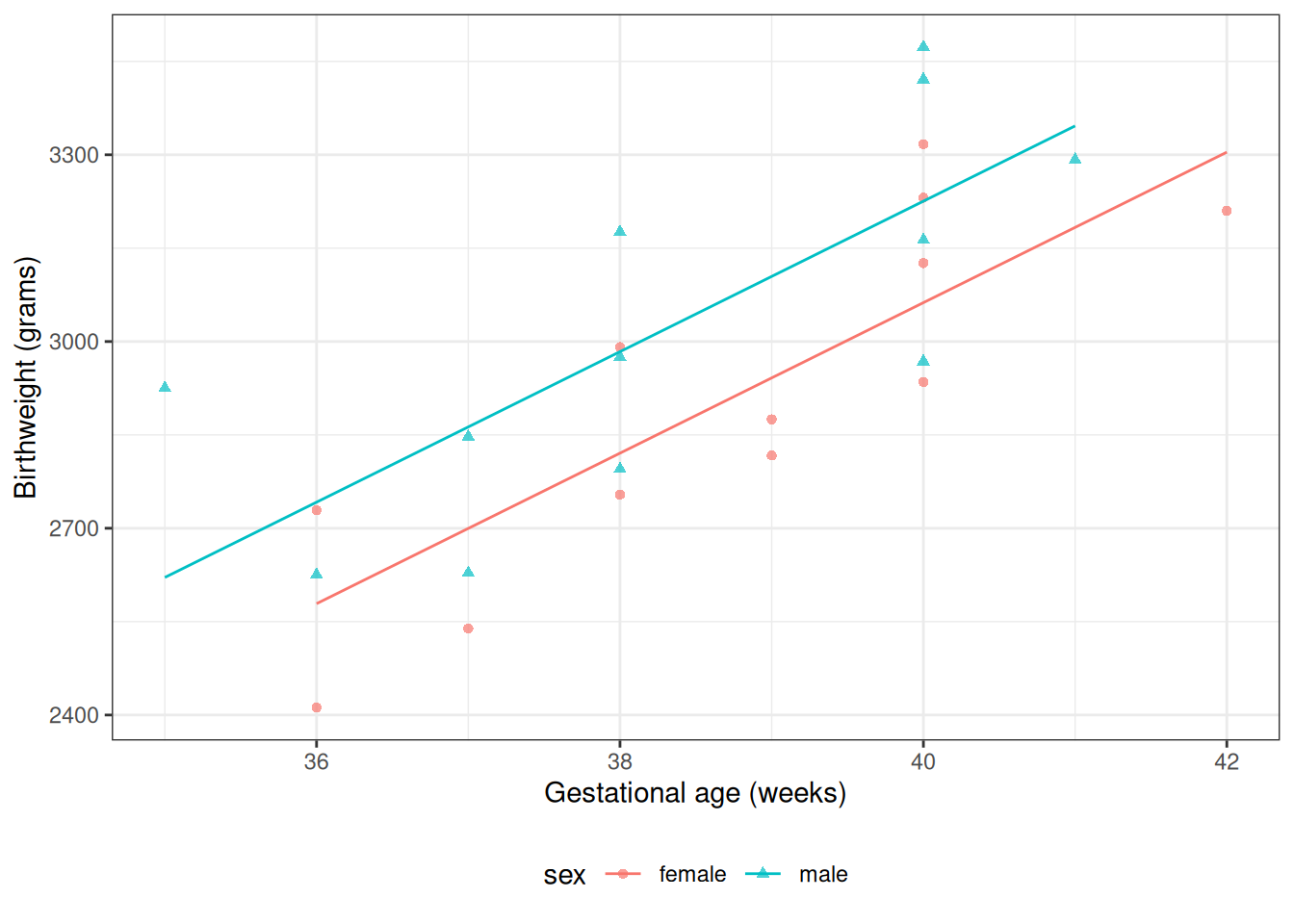
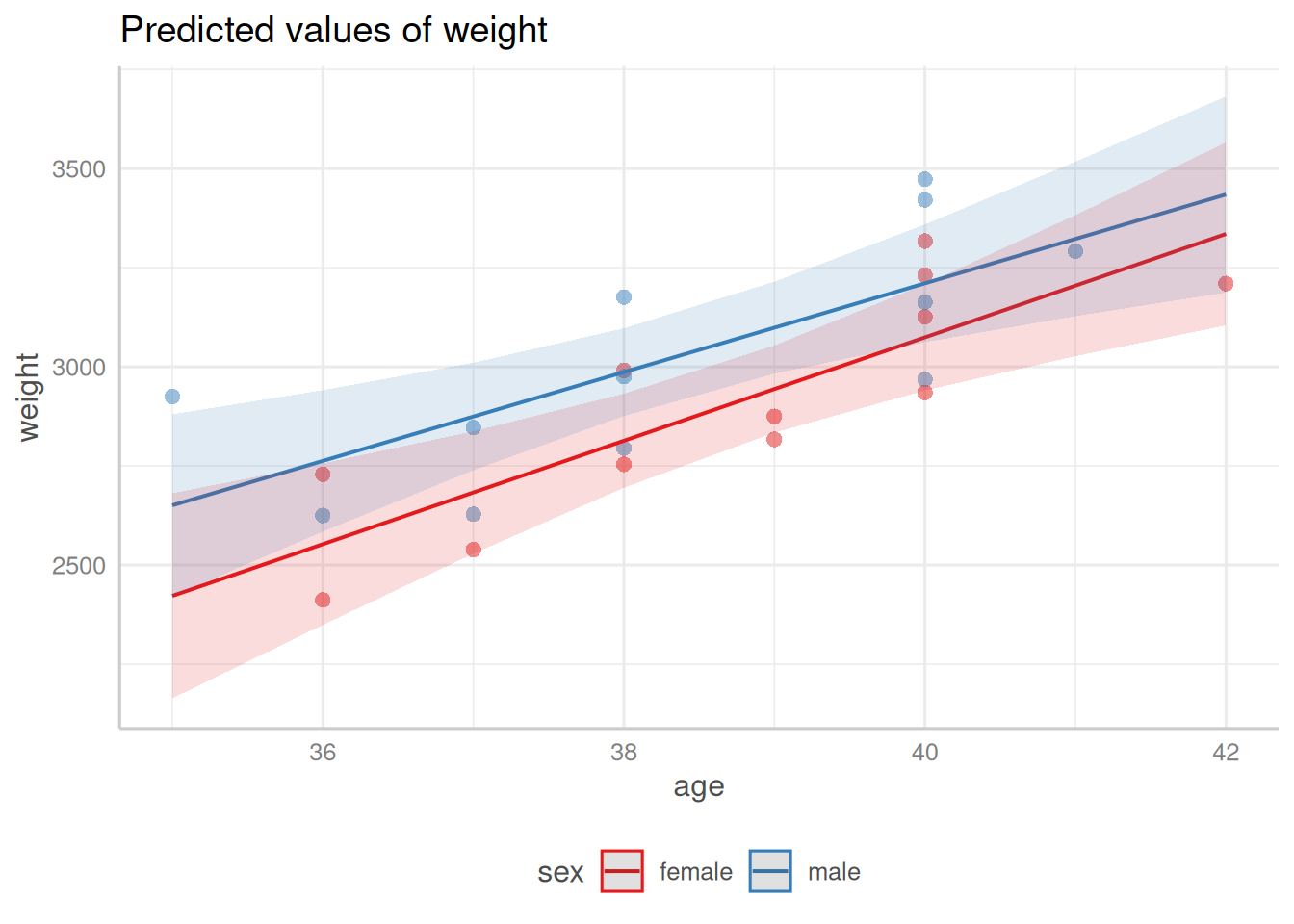
summary(bw_lm2)#> #> Call:#> lm(formula = weight ~ sex + age + sex:age, data = bw)#> #> Residuals:#> Min 1Q Median 3Q Max #> -246.7 -138.1 -39.1 176.6 274.3 #> #> Coefficients:#> Estimate Std. Error t value Pr(>|t|) #> (Intercept) -2141.7 1163.6 -1.84 0.08057 . #> sexmale 873.0 1611.3 0.54 0.59395 #> age 130.4 30.0 4.35 0.00031 ***#> sexmale:age -18.4 41.8 -0.44 0.66389 #> ---#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#> #> Residual standard error: 181 on 20 degrees of freedom#> Multiple R-squared: 0.643, Adjusted R-squared: 0.59 #> F-statistic: 12 on 3 and 20 DF, p-value: 0.000101
3.8 Predicted and fitted values
Definition 2 (Predicted value) In a regression model \(\text{p}(y|\tilde{x})\), the predicted value of \(y\) given \(\tilde{x}\) is the estimated mean of \(Y\) given \(\tilde{X}=\tilde{x}\):
\[\hat y \stackrel{\text{def}}{=}\hat{\text{E}}{\left[Y|\tilde{X}=\tilde{x}\right]}\]
For linear models, the predicted value can be straightforwardly calculated by multiplying each predictor value \(x_j\) by its corresponding coefficient \(\beta_j\) and adding up the results:
Definition 3 (Fitted value) For a given dataset \((\tilde{Y}, \mathbf{X})\) and corresponding fitted model \(\text{p}_{\hat \beta}(\tilde{y}|\mathbf{x})\), the fitted value of \(y_i\) is the predicted value (see Definition 2) of \(y\) when \(\tilde{X}=\tilde{x}_i\) using the estimated parameters \(\hat \beta\):
where \(\ell(\hat\theta)\) is the log-likelihood evaluated at the maximum-likelihood estimates \(\hat\theta\), \(p\) is the number of estimated parameters (including \(\hat\sigma^2\) for Gaussian models), and \(n\) is the number of observations.
Definition 5 (Bayesian Information Criterion (BIC))\[\text{BIC} = -2 \ell(\hat\theta) + p \log(n)\]
where \(\ell(\hat\theta)\), \(p\), and \(n\) are defined as in Definition 4.
Conceptual basis
Each criterion has two components:
Fit term (\(-2\ell(\hat\theta)\)): measures lack of fit — lower is better. A model with more parameters will always achieve a higher (or equal) log-likelihood on the observed data.
Penalty term (\(2 p\) for AIC; \(p \log(n)\) for BIC): penalizes model complexity to guard against overfitting.
Together, they balance goodness of fit against parsimony.
AIC vs. BIC
Criterion
Penalty per parameter
Tends to select
AIC
\(2\)
larger models
BIC
\(\log(n)\)
smaller models
The BIC penalty exceeds the AIC penalty whenever \(\log(n) > 2\), i.e., when \(n > e^2 \approx 7.4\). In practice, BIC almost always penalizes additional parameters more heavily than AIC and therefore tends to select simpler (more parsimonious) models (Vittinghoff et al. 2012; Kleinbaum et al. 2014).
AIC in R
[R code]
-2*logLik(bw_lm2) |>as.numeric() +2* (length(coef(bw_lm2)) +1) # sigma counts as a parameter here#> [1] 323.159AIC(bw_lm2)#> [1] 323.159
Lower values are better. There are no hypothesis tests or p-values associated with these criteria.
To compare models, calculate the criterion for each model and choose the model with the smallest value.
Differences of less than 2 units are generally considered negligible; differences greater than 10 are considered strong evidence in favor of the lower-criterion model.
BIC tends to favor simpler models than AIC, especially when the sample size is large.
(Residual) Deviance
Let \(q\) be the number of distinct covariate combinations in a data set.
For example, in the birthweight data, there are \(q = 12\) unique patterns (Table 17).
[R code]
bw_X_unique
Table 17: Unique covariate combinations in the birthweight data, with replicate counts
Definition 6 (Replicates) If a given covariate pattern has more than one observation in a dataset, those observations are called replicates.
Example 2 (Replicates in the birthweight data) In the birthweight dataset, there are 2 replicates of the combination “female, age 36” (Table 17).
Exercise 14 (Replicates in the birthweight data) Which covariate pattern(s) in the birthweight data has the most replicates?
Solution 1 (Replicates in the birthweight data). Two covariate patterns are tied for most replicates: males at age 40 weeks and females at age 40 weeks. 40 weeks is the usual length for human pregnancy (Polin et al. (2011)), so this result makes sense.
[R code]
bw_X_unique |> dplyr::filter(n ==max(n))
Saturated models
The most complicated model we could fit would have one parameter (a mean) for each covariate pattern, plus a variance parameter:
We can calculate the log-likelihood of this model as usual:
[R code]
logLik(lm_max)#> 'log Lik.' -151.402 (df=13)
We can compare this model to our other models using chi-square tests, as usual:
[R code]
library(lmtest)lrtest(lm_max, bw_lm2)
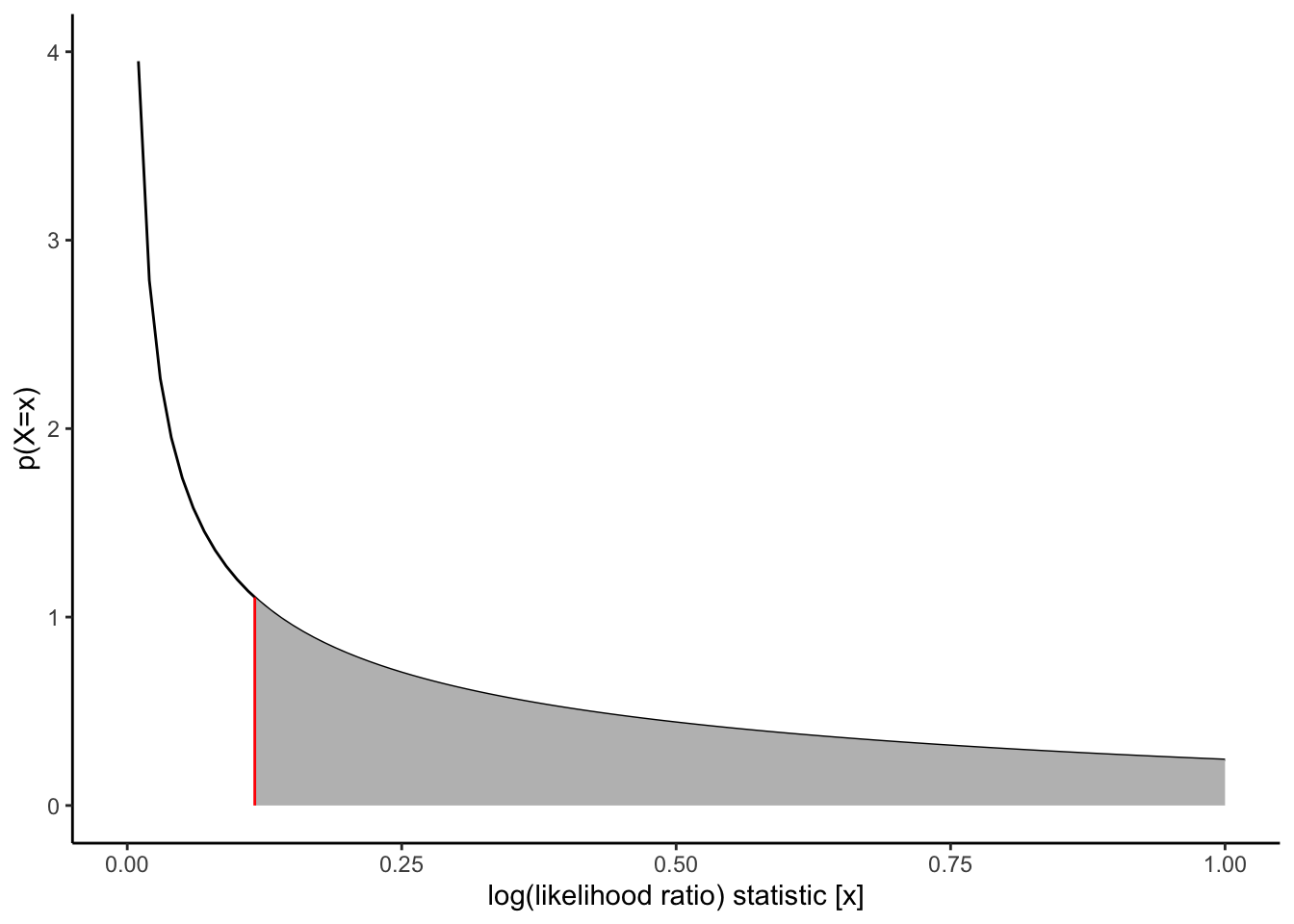
The likelihood ratio statistic for this test is \[\lambda = 2 * (\ell_{\text{full}} - \ell) = 10.355374\] where:
\(\ell_{\text{full}}\) is the log-likelihood of the full model: -151.401601
\(\ell\) is the log-likelihood of our comparison model (two slopes, two intercepts): -156.579288
This statistic is called the deviance or residual deviance for our two-slopes and two-intercepts model; it tells us how much the likelihood of that model deviates from the likelihood of the maximal model.
The corresponding p-value tells us whether there we have enough evidence to detect that our two-slopes, two-intercepts model is a worse fit for the data than the maximal model; in other words, it tells us if there’s evidence that we missed any important patterns. (Remember, a nonsignificant p-value could mean that we didn’t miss anything and a more complicated model is unnecessary, or it could mean we just don’t have enough data to tell the difference between these models.)
Null Deviance
Similarly, the least complicated model we could fit would have only one mean parameter, an intercept:
\[\text{E}{\left[Y|X=x\right]} = \beta_0\]
We can fit this model in R like so:
[R code]
lm0 <-lm(weight ~1, data = bw)lm0 |>parameters() |>print_md()
Parameter
Coefficient
SE
95% CI
t(23)
p
(Intercept)
2967.67
57.58
(2848.56, 3086.77)
51.54
< .001
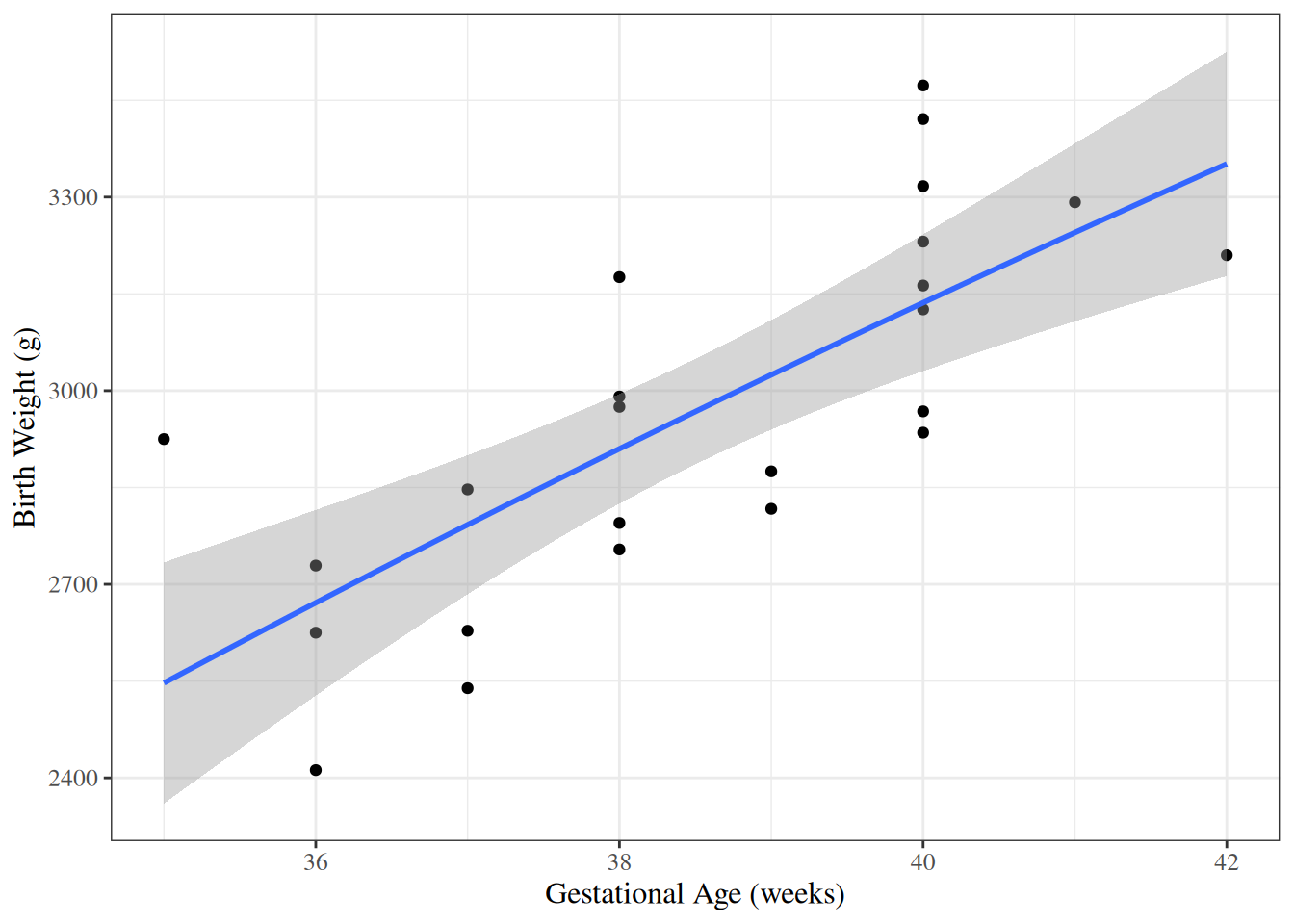
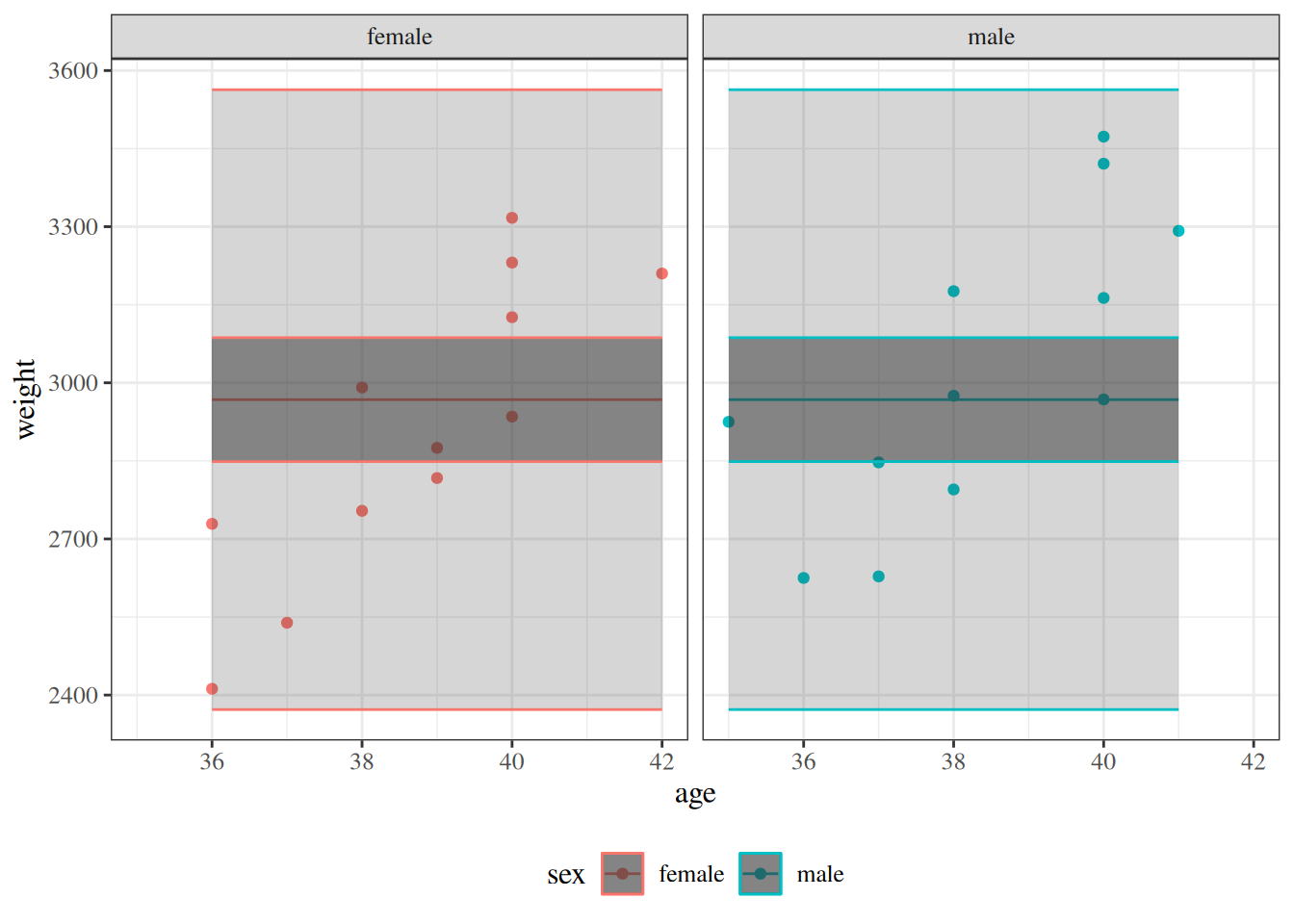
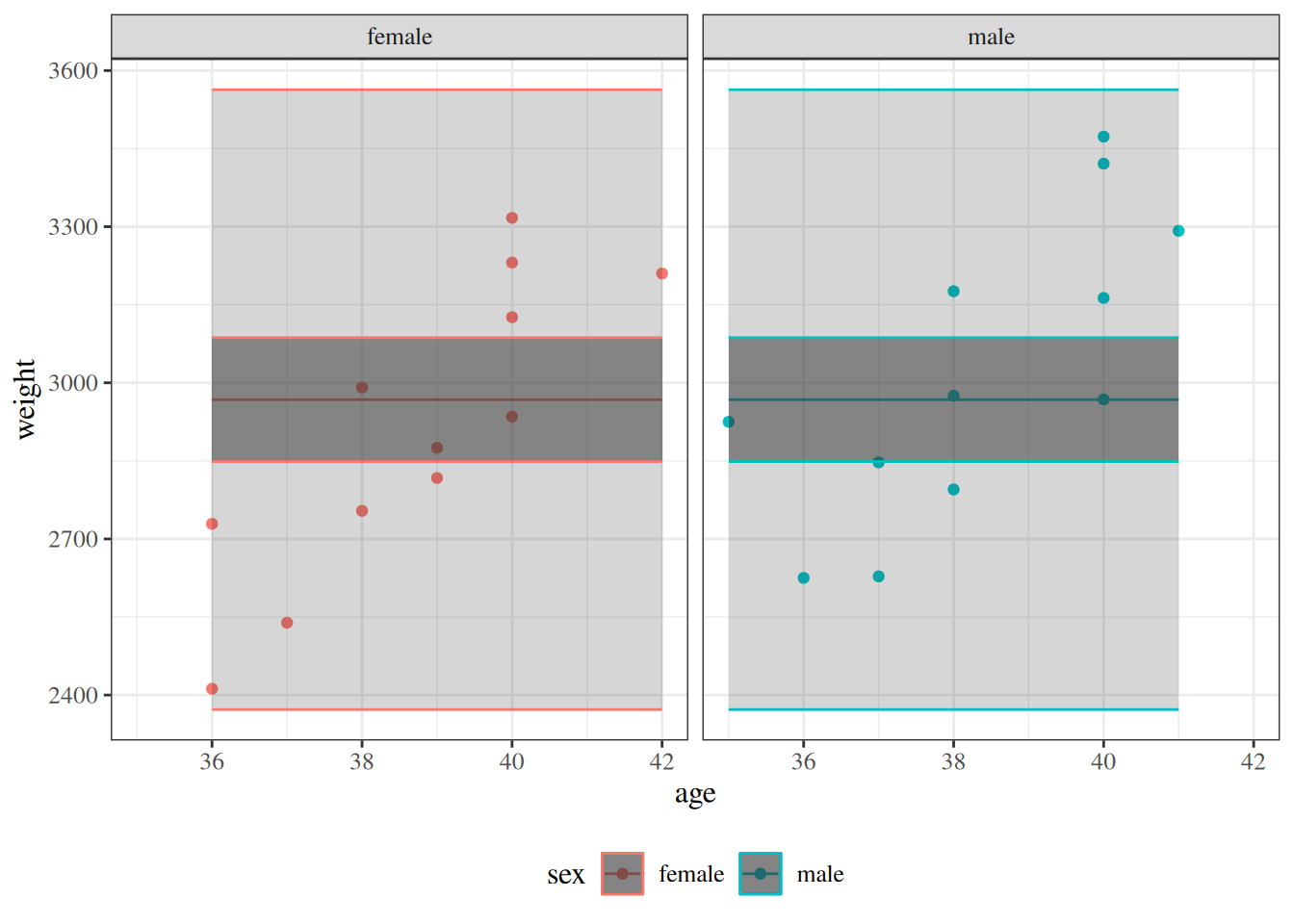
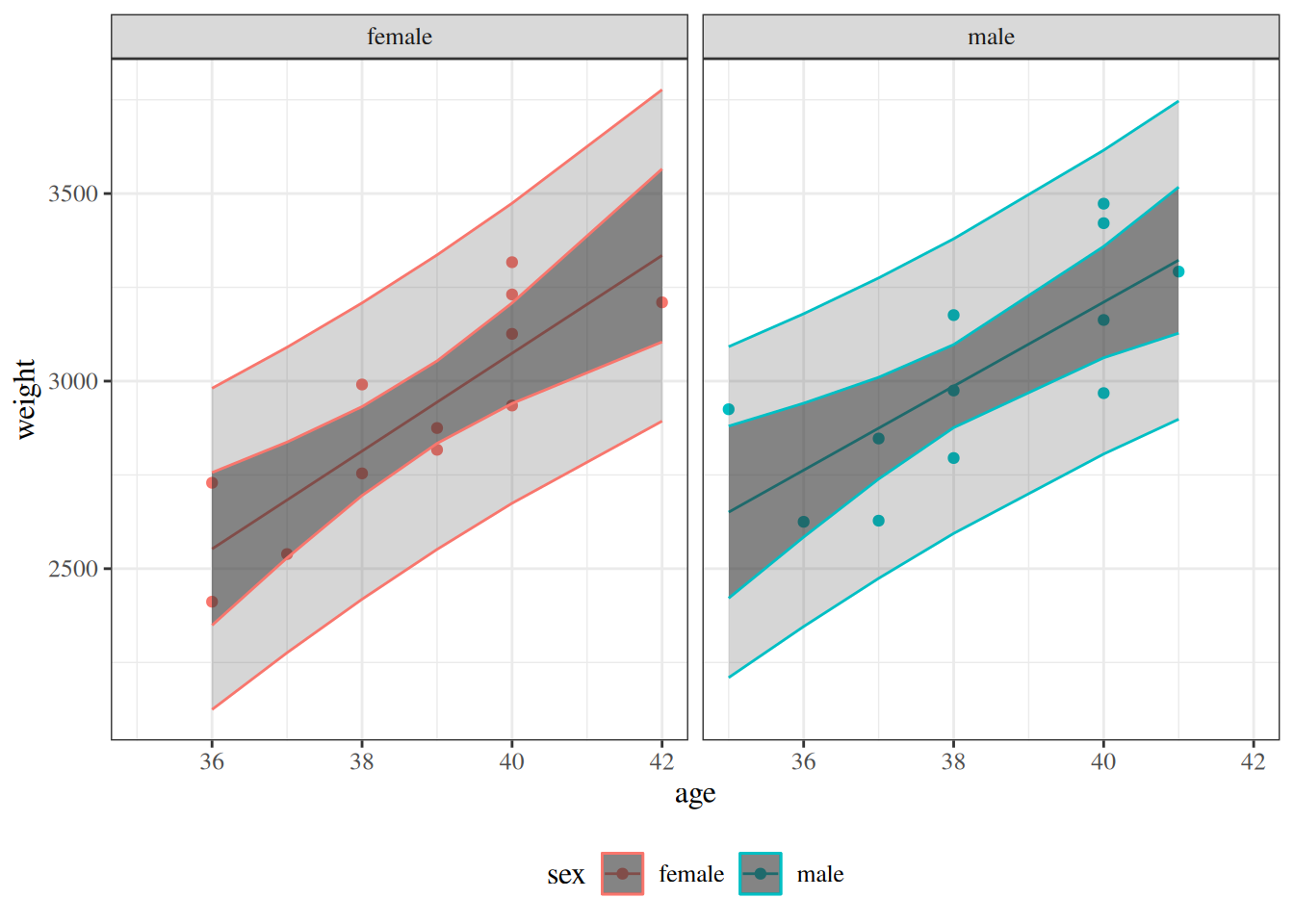
Figure 10: Null model and model 2 for birthweight data, with 95% confidence and prediction intervals.
And we can compare it to more complicated models using a likelihood ratio test:
[R code]
lrtest(bw_lm2, lm0)
The likelihood ratio statistic for the test comparing the null model to the maximal model is \[\lambda = 2 * (\ell_{\text{full}} - \ell_{0}) = 35.106732\] where:
\(\ell_{\text{0}}\) is the log-likelihood of the null model: -168.954967
\(\ell_{\text{full}}\) is the log-likelihood of the maximal model: -151.401601
In R, this test is:
[R code]
lrtest(lm_max, lm0)
This log-likelihood ratio statistic is called the null deviance. It tells us whether we have enough data to detect a difference between the null and full models.
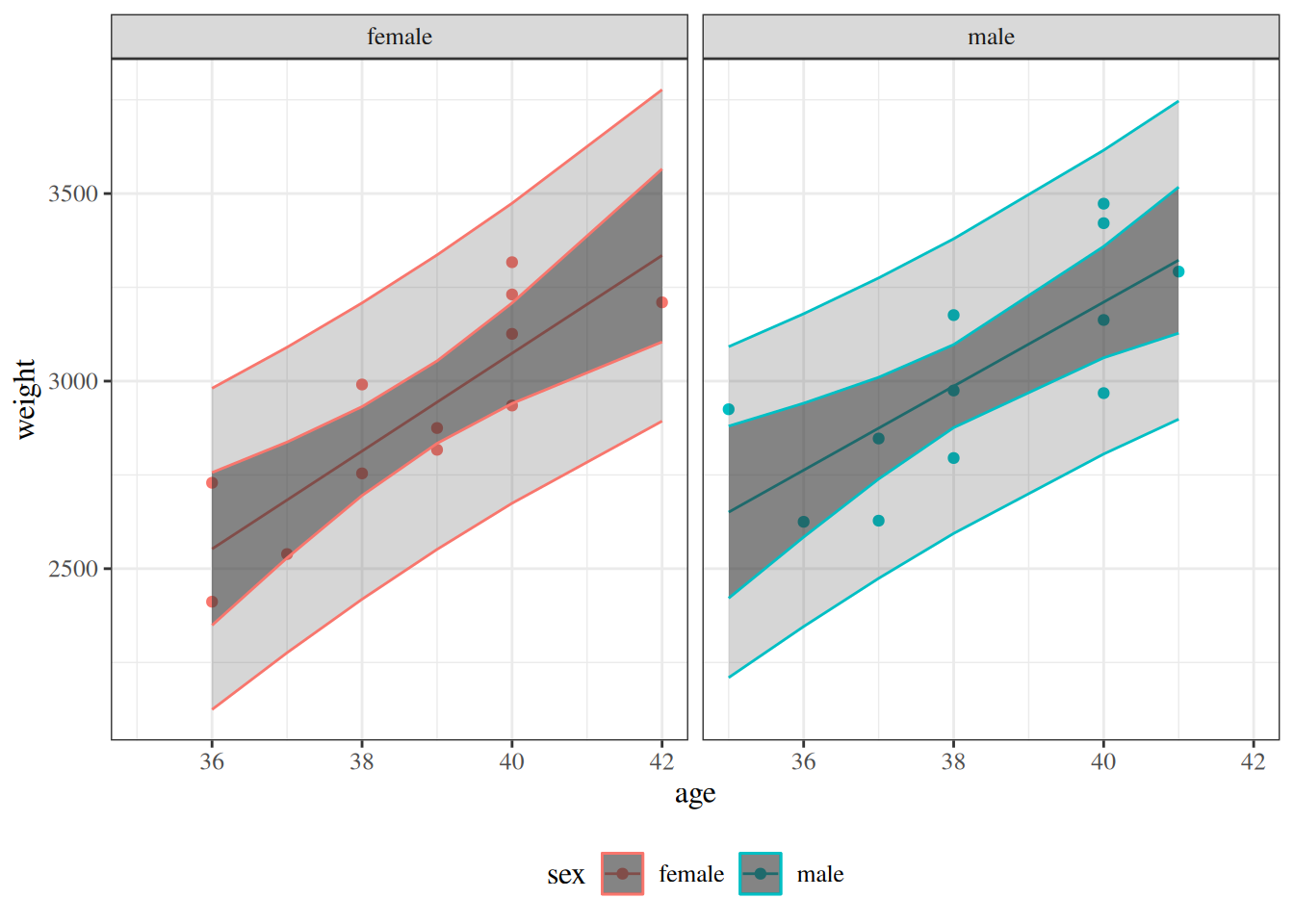
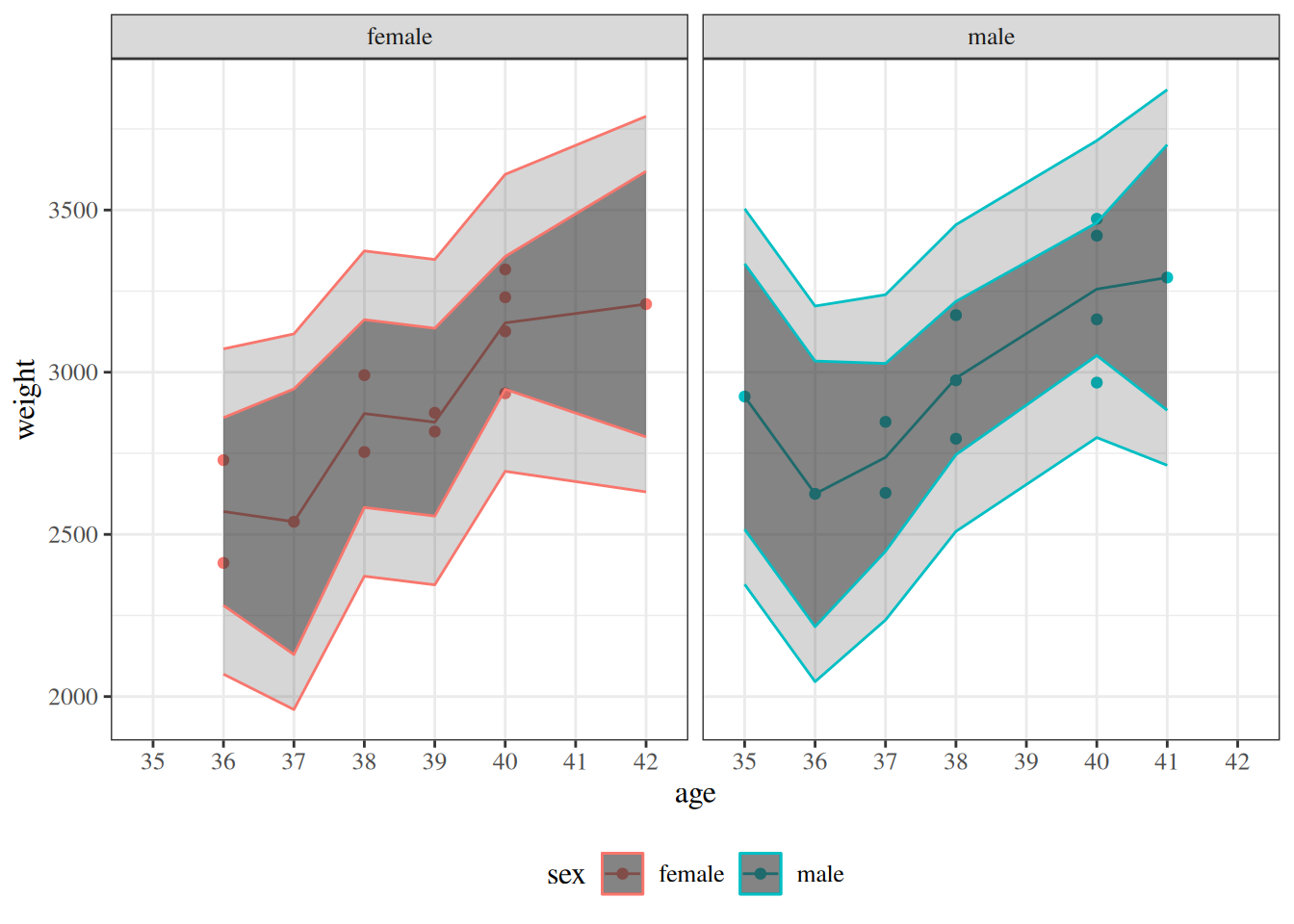
Figure 11: Four models for birthweight data, with 95% confidence and prediction intervals. The spectrum from null to saturated includes many other possible models, such as quadratic polynomial models (with or without interactions) and generalized additive models (GAMs).
where \(\ell_{\text{sat}}\) is the log-likelihood of the saturated model and \(\ell(\hat\beta)\) is the log-likelihood of the fitted model. However, this formula simplifies differently depending on the distribution family, and the resulting test statistics have different null distributions.
The saturated model has one free mean parameter per distinct covariate pattern. When there are no replicates (each covariate pattern appears exactly once), it sets \(\hat\mu_i = y_i\) for every observation, so its residual sum of squares is zero:
Because \(\sigma^2\) is unknown and must be estimated, comparing deviances between two nested Gaussian models uses an F-test, which is exact under Gaussian assumptions. Substituting \(D = \text{RSS}/\hat\sigma^2\), the \(\hat\sigma^2\) factors cancel:
For Poisson and Binomial models, the dispersion parameter \(\phi = 1\) is fixed rather than estimated. Consequently, the difference in deviances between two nested models follows an approximate \(\chi^2\) distribution:
\[D_1 - D_2 \;\dot \sim\; \chi^2_{p_2 - p_1}\]
This asymptotic result replaces the exact F-test used for Gaussian models.
Saturated vs. fully parametrized models with replicates
When some covariate patterns appear more than once (i.e., when there are replicates), it is important to distinguish between two special models:
The saturated model has one free mean parameter per distinct covariate pattern (\(q\) parameters, where \(q \leq n\) is the number of unique patterns).
The fully parametrized model has one free mean parameter per observation (\(n\) parameters).
When there are no replicates (\(q = n\)), these two coincide. When there are replicates (\(q < n\)), the saturated model constrains all observations sharing a covariate pattern to have the same mean, but places no constraint on means across different patterns. See Kleinbaum and Klein (2010) for further discussion of this distinction.
Deviance is always measured relative to the saturated model, not the fully parametrized model.
Gaussian deviance with replicates
When covariate pattern \(k\) has \(n_k\) replicates with sample mean \(\bar{y}_k\), the saturated model fits \(\hat\mu_k = \bar{y}_k\) for each pattern \(k\), so its residual sum of squares equals the within-group (pure error) SS:
This is nonzero whenever any covariate pattern has replicates with different response values. The Gaussian deviance relative to the saturated model is therefore:
R’s deviance() applied to an lm object returns the total fitted-model RSS, not the deviance relative to the saturated model. To compute the deviance relative to the saturated model, subtract the saturated model’s RSS: deviance(lm_fit) - deviance(lm_saturated).
For the birthweight data, we can verify this directly using bw_lm2 (the interaction model) and lm_max (the saturated model):
deviance(bw_lm2) # total RSS of fitted model#> [1] 652425deviance(lm_max) # within-group (pure error) SS#> [1] 423783deviance(bw_lm2) -deviance(lm_max) # lack-of-fit SS (deviance vs. saturated)#> [1] 228642
GLM deviance with replicates
For a Binomial GLM fit to data grouped by covariate pattern (with \(y_k\) events and \(n_k\) observations for pattern \(k\)), the saturated model sets \(\hat\pi_k^{\text{sat}} = y_k / n_k\) for each pattern \(k\). R’s deviance() correctly computes \(2(\ell_{\text{sat}} - \ell(\hat\beta))\) using this grouping:
When binomial data is ungrouped (individual Bernoulli observations, \(n_i = 1\)), R uses the fully parametrized model as its reference — assigning \(\hat\pi_i = y_i \in \{0, 1\}\) to each individual observation. Since each predicted probability is exactly 0 or 1, every Bernoulli likelihood contribution equals 1, and hence \(\ell_{\text{fp}} = 0\). Thus R’s deviance() returns \(-2\ell(\hat\beta)\).
We can verify this directly: observations are ungrouped Bernoulli with repeated covariate patterns (\(x \in \{0, 1\}\) appears three times each).
This reference model is the fully parametrized model (one parameter per observation), not the saturated model (one parameter per distinct covariate pattern). They coincide only when there are no repeated covariate patterns (\(q = n\)). When patterns do repeat (\(q < n\)), the saturated model sets \(\hat\pi_k = y_k/n_k\) per pattern, giving \(\ell_{\text{sat}} < 0\).
deviance() for ungrouped data cannot be used as a goodness-of-fit test against the \(\chi^2\) distribution when \(q < n\). The correct GOF statistic is \(2(\ell_{\text{sat}} - \ell(\hat\beta))\), but R’s deviance() for ungrouped data returns \(-2\ell(\hat\beta)\) (using \(\ell_{\text{fp}} = 0\)). These two quantities differ by \(-2\ell_{\text{sat}} > 0\) whenever \(q < n\). Even if each covariate pattern has many replicates (large \(n_k\)), R’s ungrouped deviance is the wrong statistic to compare against \(\chi^2(q - p)\). To obtain a valid GOF test when patterns repeat, fit the model using grouped data (one row per pattern with \(y_k\) and \(n_k\)), so that R uses the saturated model as its reference.
Definition 7 (Deviation of an observation from its subpopulation mean) The deviation of an observation from its subpopulation mean in a probabilistic model \(p(Y \mid X)\), is the difference between an observed value and its model-implied mean given covariates:
Definition 8 (Signal (statistical sense)) In statistical modeling, the signal is the deterministic part of the model. For mean-based models, the signal is the model-implied mean function, for example \(\text{E}{\left[Y \mid X\right]}\) (or \(\text{E}{\left[Y\right]}\) when there are no covariates).
Theorem 1 (Deviations in Gaussian models) If \(Y\) has a Gaussian distribution, then \(e(Y)\) also has a Gaussian distribution, and vice versa.
Proof. By Definition 7, \(e(Y \mid X = x) = Y - \text{E}{\left[Y \mid X = x\right]}\). Let \(\mu(x) = \text{E}{\left[Y \mid X = x\right]}\). Since \(e(Y \mid X = x) = Y - \mu(x)\) is an affine function of \(Y\), and Gaussian distributions are closed under affine transformations, if \(Y \mid X = x \sim \text{N}(\mu(x), \sigma^2)\), then:
\[
e(Y \mid X = x) = Y - \mu(x) \sim \text{N}(\mu(x) - \mu(x), \sigma^2) = \text{N}(0, \sigma^2)
\]
Conversely, since \(Y = \text{E}{\left[Y \mid X = x\right]} + e(Y \mid X = x) = \mu(x) + e(Y \mid X = x)\), if \(e(Y \mid X = x) \sim \text{N}(0, \sigma^2)\), then \(Y \mid X = x = \mu(x) + e(Y \mid X = x) \sim \text{N}(\mu(x), \sigma^2)\).
Definition 9 (Residuals) A residual is the difference between an observed value and its corresponding fitted value, \(\hat y\): \[
\begin{aligned}
r&\stackrel{\text{def}}{=}y - \hat y
\end{aligned}
\]
For indexed observations, this is equivalently: \[
r_i \stackrel{\text{def}}{=}y_i - \hat y_i
\]
For a particular fitted model, each residual \(r_i\) is tied to its corresponding fitted value \(\hat y_i\). The fitted value \(\hat y_i\) is often a sample mean or fitted conditional mean, but not always.
Different sources are not fully consistent about these terms. For terminology in this course, we use:
deviation for deviation of an observation from its population mean (typically conditional on covariates). This quantity is often called error in other sources, even though it doesn’t directly involve an estimate; cf., https://en.wikipedia.org/wiki/Errors_and_residuals;
estimation error for deviation of an estimate from its estimand;
residual for deviation of an observed value from a fitted value.
General characteristics of residuals
Definition 10 (Hat matrix) For an ordinary least squares linear model with design matrix \(\mathbf{X}\), the hat matrix is
Theorem 2 For an ordinary least squares linear model with fitted values \(\hat y_i = \tilde{x}_i \cdot \tilde{\beta}\) (and fitted-value vector \(\hat{\tilde{Y}}\)), if the conditional mean is correctly specified so that:
and if the errors are homoskedastic so that \(\text{Var}{\left(\tilde{Y}\mid \mathbf{X}\right)} = \sigma^2\mathbb{I}_n\) where \(\mathbb{I}_n\) is the \(n \times n\) identity matrix, then, treating \(\mathbf{X}\) as fixed in this derivation, the residual moments are:
The conditional mean result (Equation 12) uses unbiasedness of fitted values. The conditional variance result (Equation 13) uses the homoskedasticity condition with the OLS hat-matrix representation.
When leverage is roughly uniform, \(h_{ii} \approx k/n\), where \(k = \mathrm{rank}(\mathbf{X})\) (so \(k = p + 1\) for a full-rank model with an intercept and \(p\) predictors), so \(\text{Var}{\left(r_i\right)} \approx \sigma^2\) as \(n\) grows.
Theorem 3 (Conditional distribution of residuals in Gaussian models) In a Gaussian linear regression model, the residuals \(r_i\), conditional on the design matrix \(\mathbf{X}\), are normally distributed:
where \(h_{ii}\) is the \(i\)-th diagonal element of the hat matrix (Definition 10). When leverage is roughly uniform, \(\sigma^2(1-h_{ii}) \approx \sigma^2\) for large \(n\); replacing the unknown \(\sigma^2\) with its estimate \(\hat \sigma^2\) gives:
Proof. Using the hat matrix (Definition 10), the residual vector is \(\tilde{r} = (I-H)\tilde{Y}\), so the \(i\)-th residual is a linear combination of the observations:
where \(\delta_{ij}\) is the Kronecker delta (\(\delta_{ij} = 1\) if \(i = j\), else \(\delta_{ij} = 0\)).
Given \(\mathbf{X}\), the random variables \(Y_1, \ldots, Y_n\) are conditionally independent Gaussians by the Gaussian model assumption. Therefore, conditional on \(\mathbf{X}\), the residual \(r_i\) is a linear combination of independent Gaussians, so \(r_i\) is Gaussian.
In particular, for \(i \neq j\), these covariances are generally nonzero.
Marginal distributions of residuals
To look for problems with our model, we can check whether the residuals \(r_i\) and standardized residuals \(r'_i\) look like they have the distributions that they are supposed to have, according to the model.
Figure 21: Marginal distribution of standardized residuals
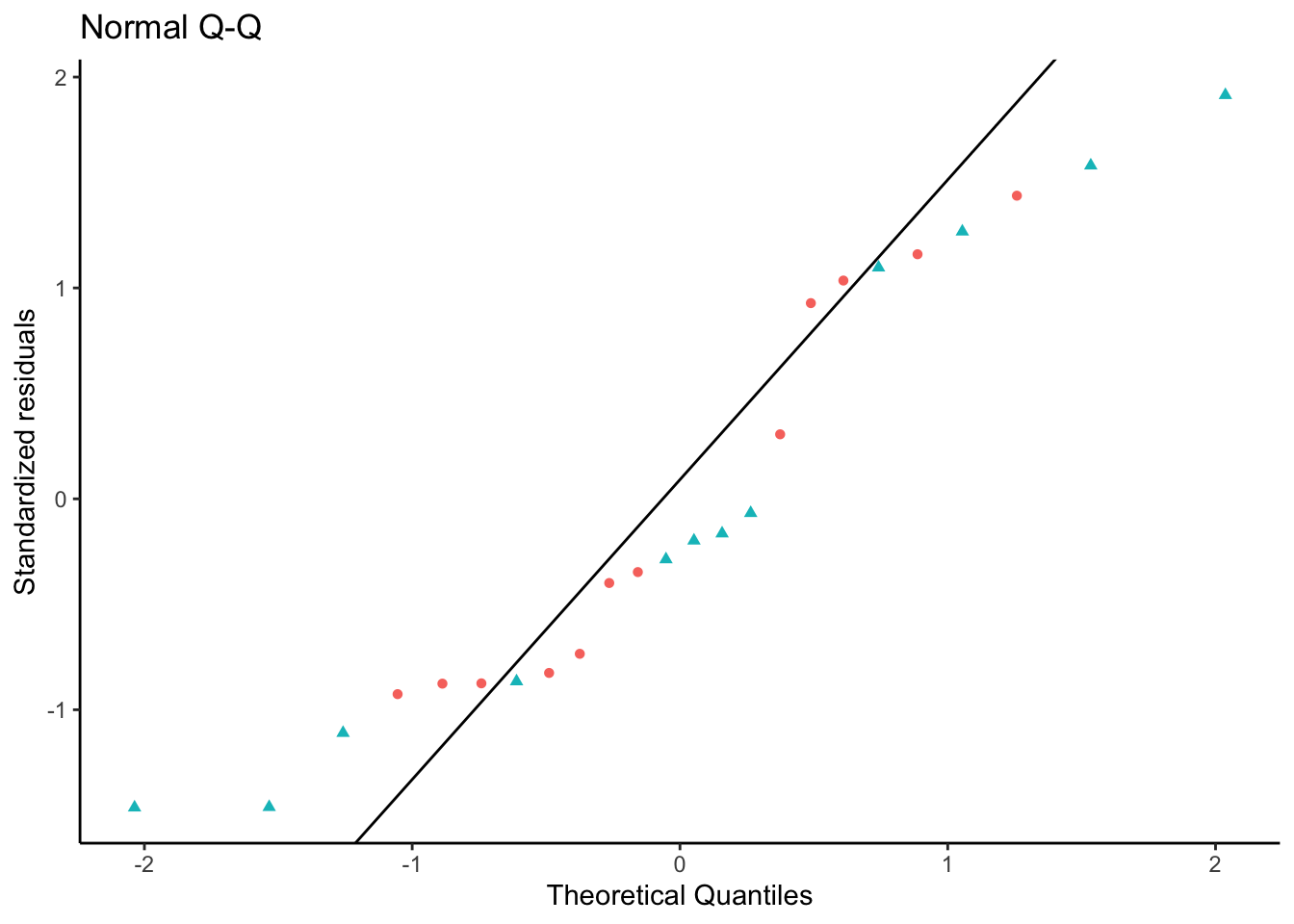
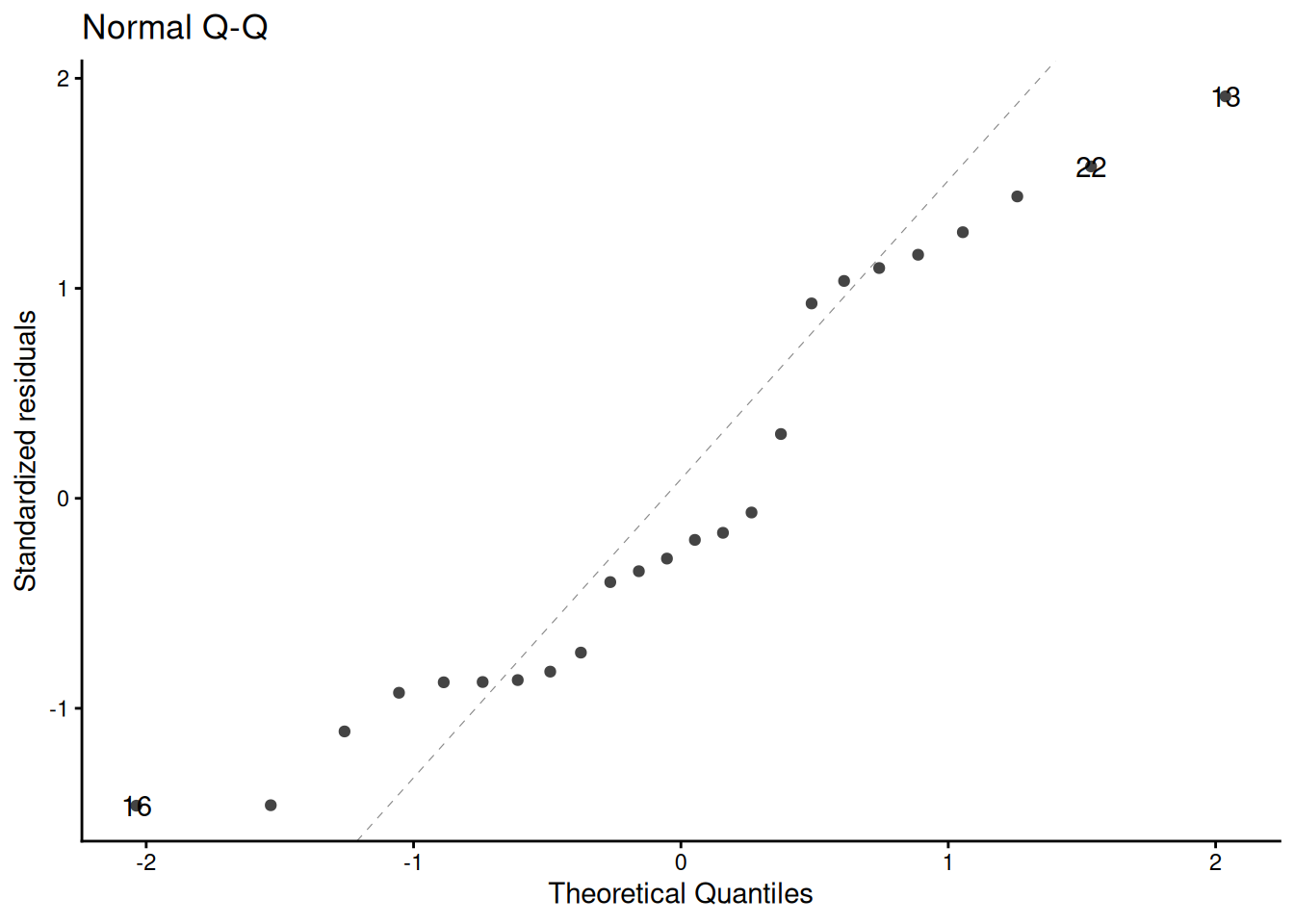
QQ plot of standardized residuals
[R code]
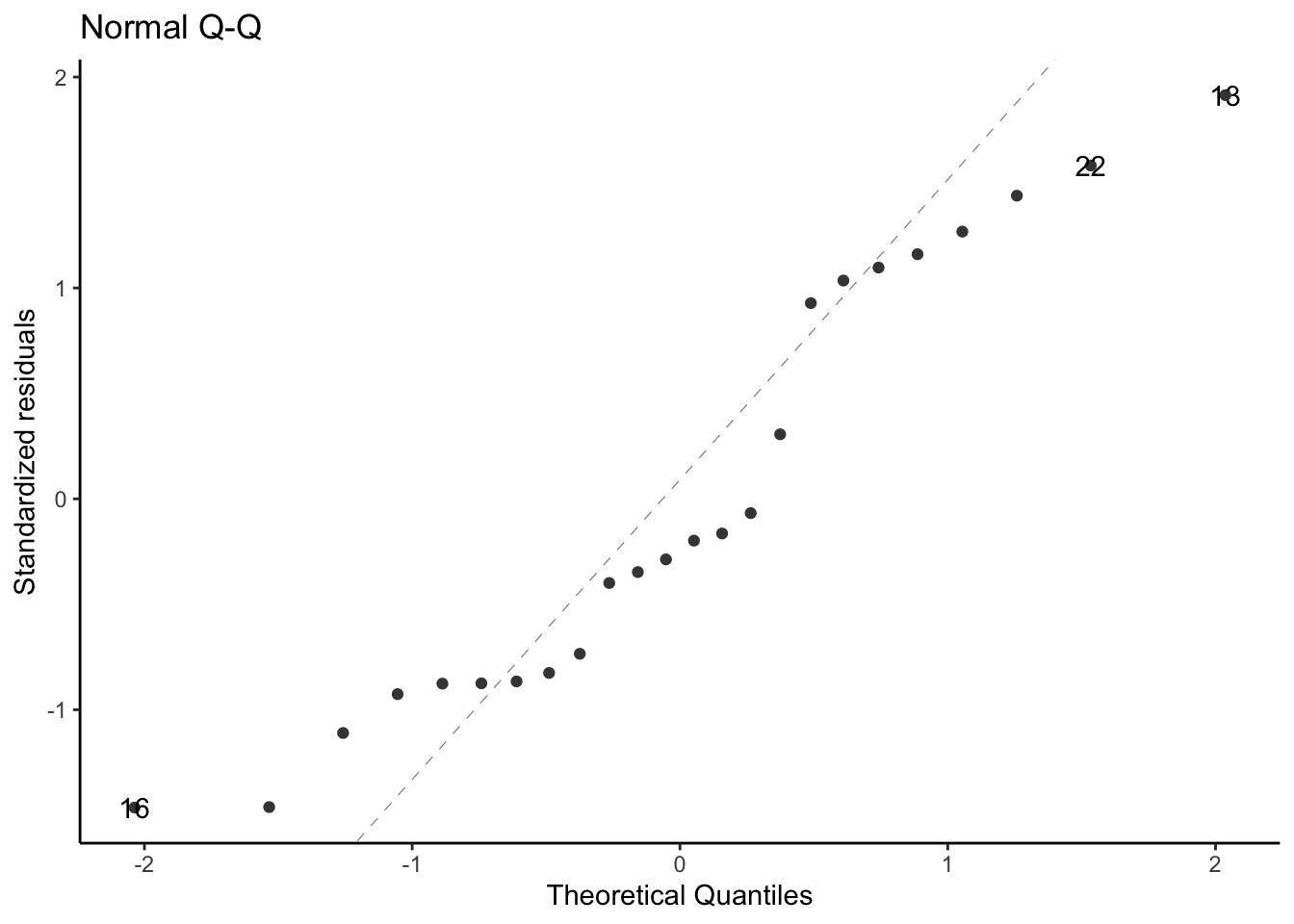
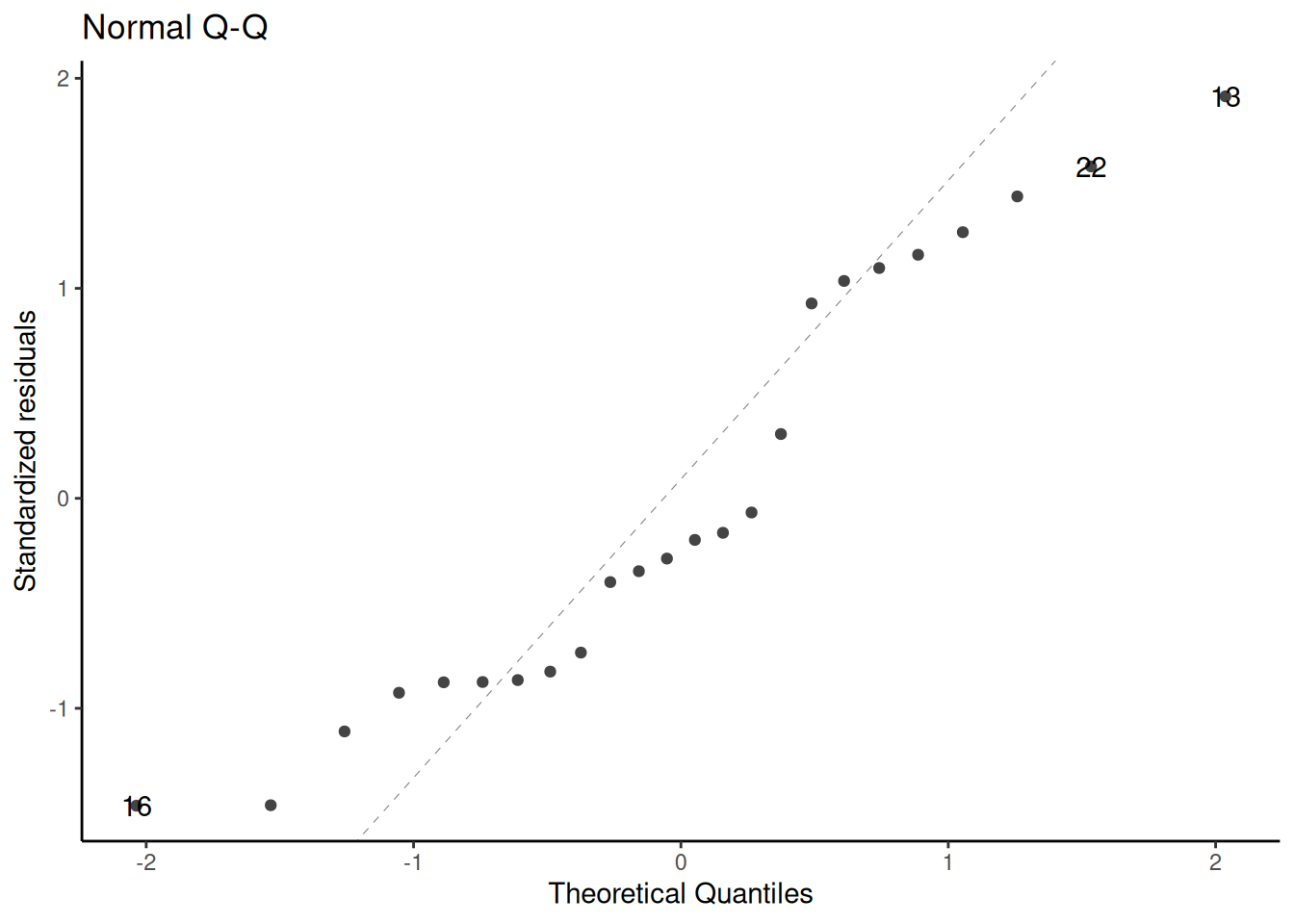
library(ggfortify)# needed to make ggplot2::autoplot() work for `lm` objectsqqplot_lm2_auto <- bw_lm2 |>autoplot(which =2, # options are 1:6; can do multiple at oncencol =1 ) +theme_classic()print(qqplot_lm2_auto)
Figure 22: Typical QQ-plot patterns for six types of residual distribution. Adapted from Dunn and Smyth (2018, fig. 3.6), with thanks to the authors; reproduced here using simulated data (\(n = 150\)). Each column shows one distribution scenario: a QQ plot (top) paired with a histogram of the simulated data (bottom).
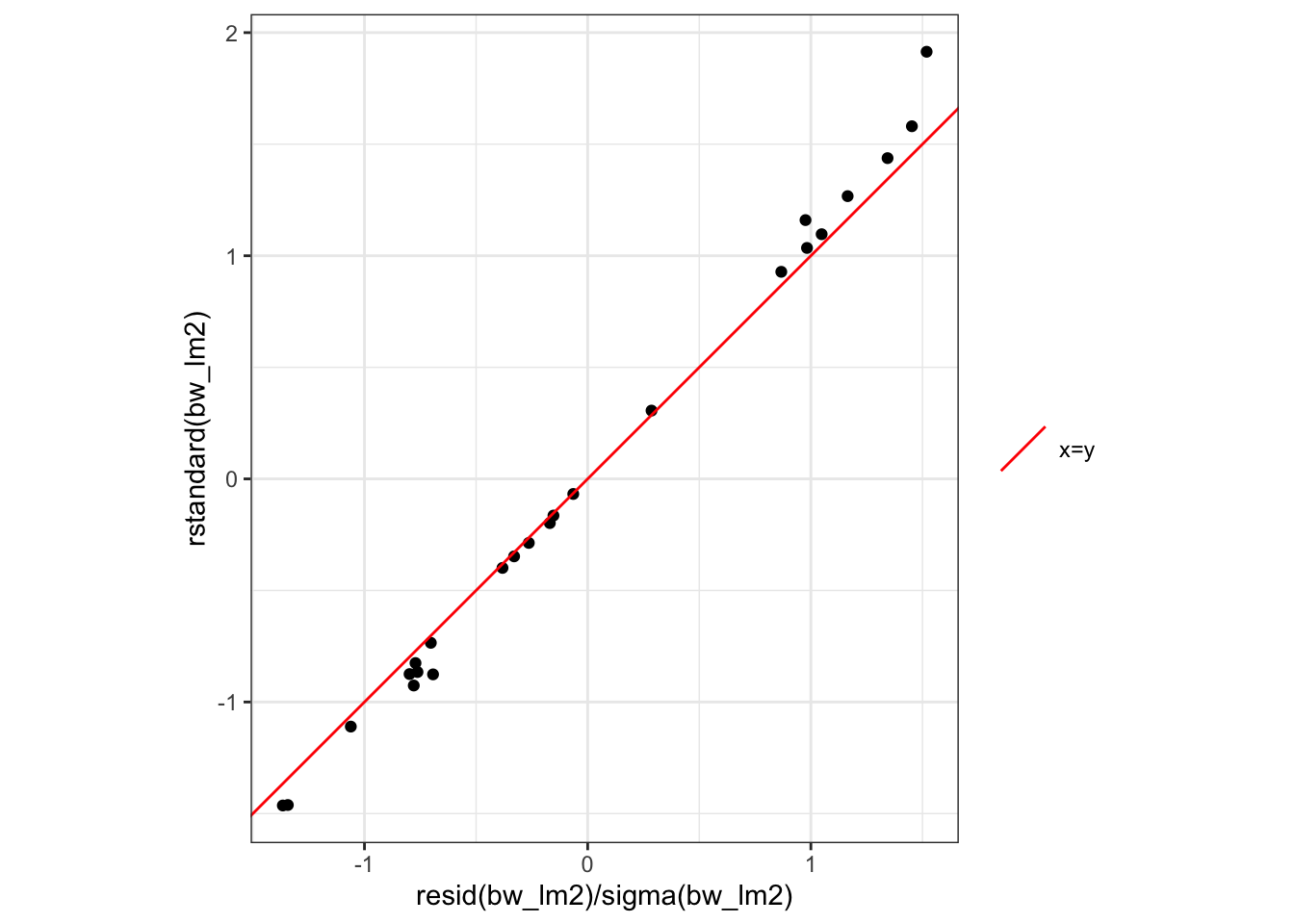
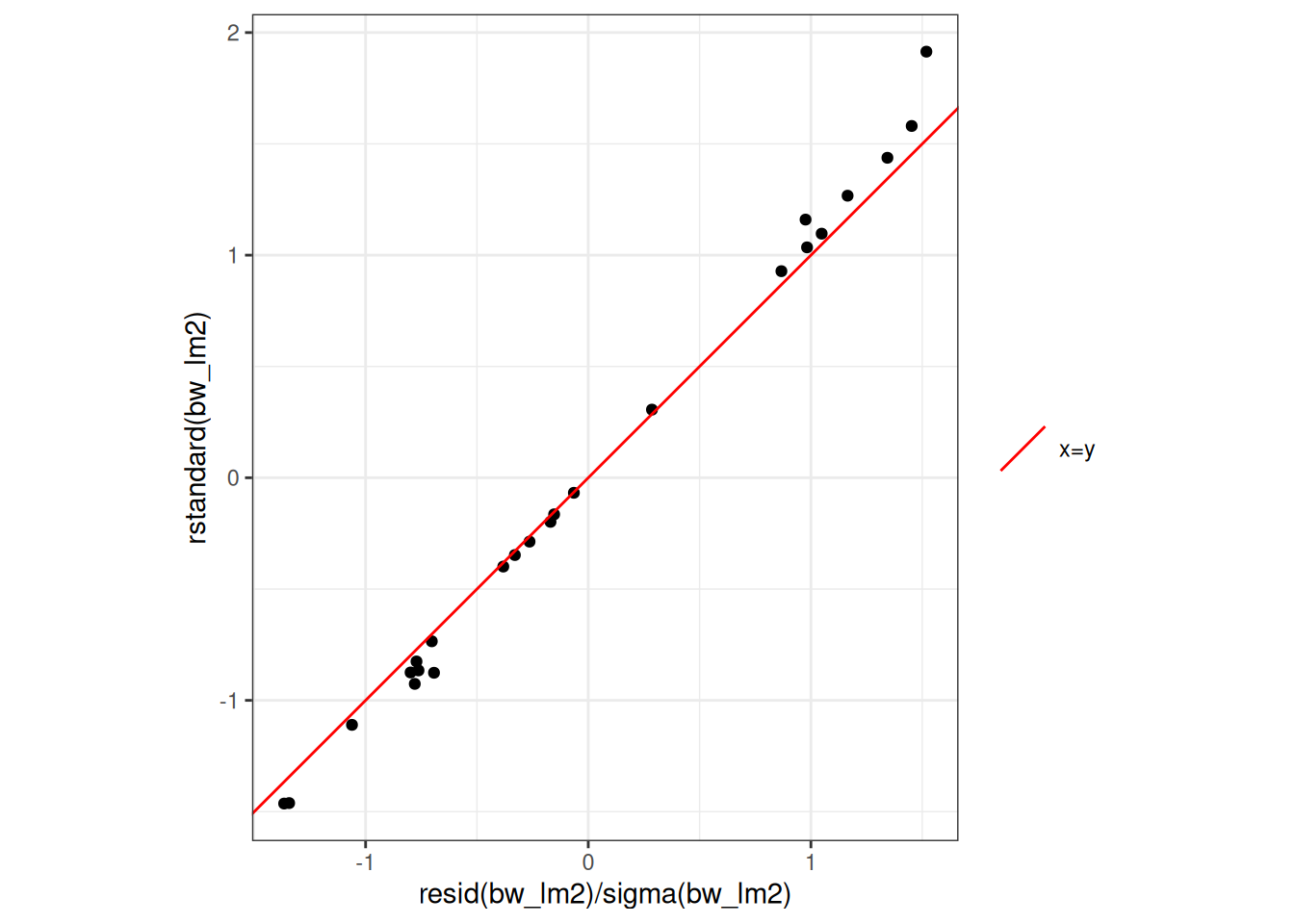
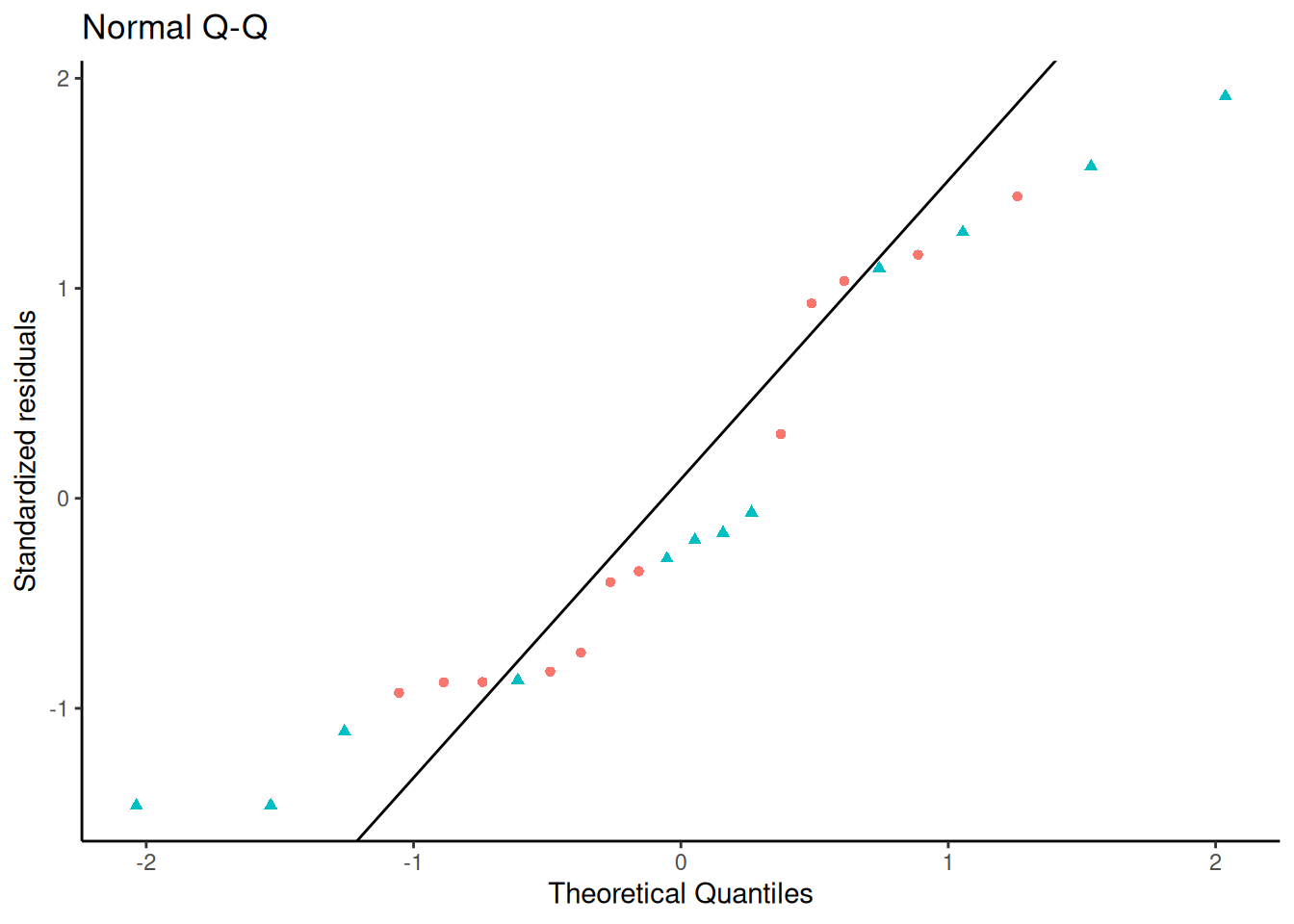
Figure 23: Three equivalent ways to produce a QQ plot of the standardized residuals for the birthweight model (Equation 2). All three plots show the same data and reference line.
Formal diagnostic tests for linear regression assumptions
Graphical diagnostics are usually the first step, but formal tests can provide numerical summaries.
For linear regression residuals, three common tests are:
fligner.test() for equal variances across groups (the Fligner–Killeen test).
Levene / Brown–Forsythe test (a median-centered Levene variant, where standard Levene centers on group means, and Brown–Forsythe centers on group medians for more robustness; e.g., via car::leveneTest(..., center = median) or equivalent code).
Fligner–Killeen test (homoskedasticity across groups)
Suppose residuals are split into groups (\(g = 1, \ldots, G\)), for example by a categorical predictor.
The test starts from absolute deviations from each group median: \[
d_{gi} = |e_{gi} - \text{median}(e_{g1}, \ldots, e_{g,n_g})|.
\]
After ranking the pooled \(d_{gi}\) values, the Fligner–Killeen statistic is built from normal scores of those ranks.
Under the null hypothesis of equal variances, the test statistic is approximately \(\chi^2_{G-1}\). Small p-values suggest heteroskedasticity.
Levene / Brown–Forsythe test (homoskedasticity across groups)
Levene’s test transforms residuals to within-group absolute deviations: \[
z_{gi} = |e_{gi} - c_g|,
\] where \(c_g\) is the group center.
Classical Levene uses the group mean for \(c_g\). Brown–Forsythe uses the group median, which is more robust.
Then run a one-way ANOVA on \(z_{gi}\) by group: \[
F = \frac{\text{MS}_{\text{between}}}{\text{MS}_{\text{within}}}
\sim F_{G-1, N-G}
\quad\text{under }H_0.
\]
Small p-values suggest unequal residual variance.
For simple linear regression, Kutner et al. (2005, 116–17) describes the Brown–Forsythe test by splitting observations into two \(X\)-level groups (low versus high), computing absolute deviations from each group median, and applying a two-sample pooled-variance t test: let \[
z_{ij} = |e_{ij} - \tilde e_i|,
\] where \(j\) indexes observations within group \(i\), and \(\tilde e_i\) is the median residual in group \(i\). Then: \[
t_{\text{BF}} =
\frac{\bar z_{1} - \bar z_{2}}
{s_p \sqrt{1/n_{1} + 1/n_{2}}},
\quad
t_{\text{BF}} \approx t_{n_{1}+n_{2}-2}
\text{ under }H_0.
\] Here, \(\bar z_{1}\) and \(\bar z_{2}\) are the means of the \(z_{ij}\) values in groups \(i=1\) and \(i=2\), \(s_p\) is their pooled standard deviation, and \(n_{1}, n_{2}\) are the two group sample sizes. Large \(|t_{\text{BF}}|\) indicates nonconstant residual variance.
Shapiro–Wilk test (normality of standardized residuals)
For ordered standardized residuals \(r_{(1)} \le \cdots \le r_{(n)}\), the Shapiro–Wilk statistic is: \[
W =
\frac{\left(\sum_{i=1}^n a_i r_{(i)}\right)^2}
{\sum_{i=1}^n (r_i - \bar r)^2},
\] where \(a_i\) are constants from normal-order-statistic moments. The numerator uses ordered residuals \(r_{(i)}\), while the denominator uses the original (unordered) residuals.
If residuals are Gaussian, \(W\) tends to be close to 1. Small \(W\) (and small p-value) indicates departure from normality.
Interpretation rule: for all three tests, a small p-value is evidence against the corresponding model assumption.
Compared with visual diagnostics:
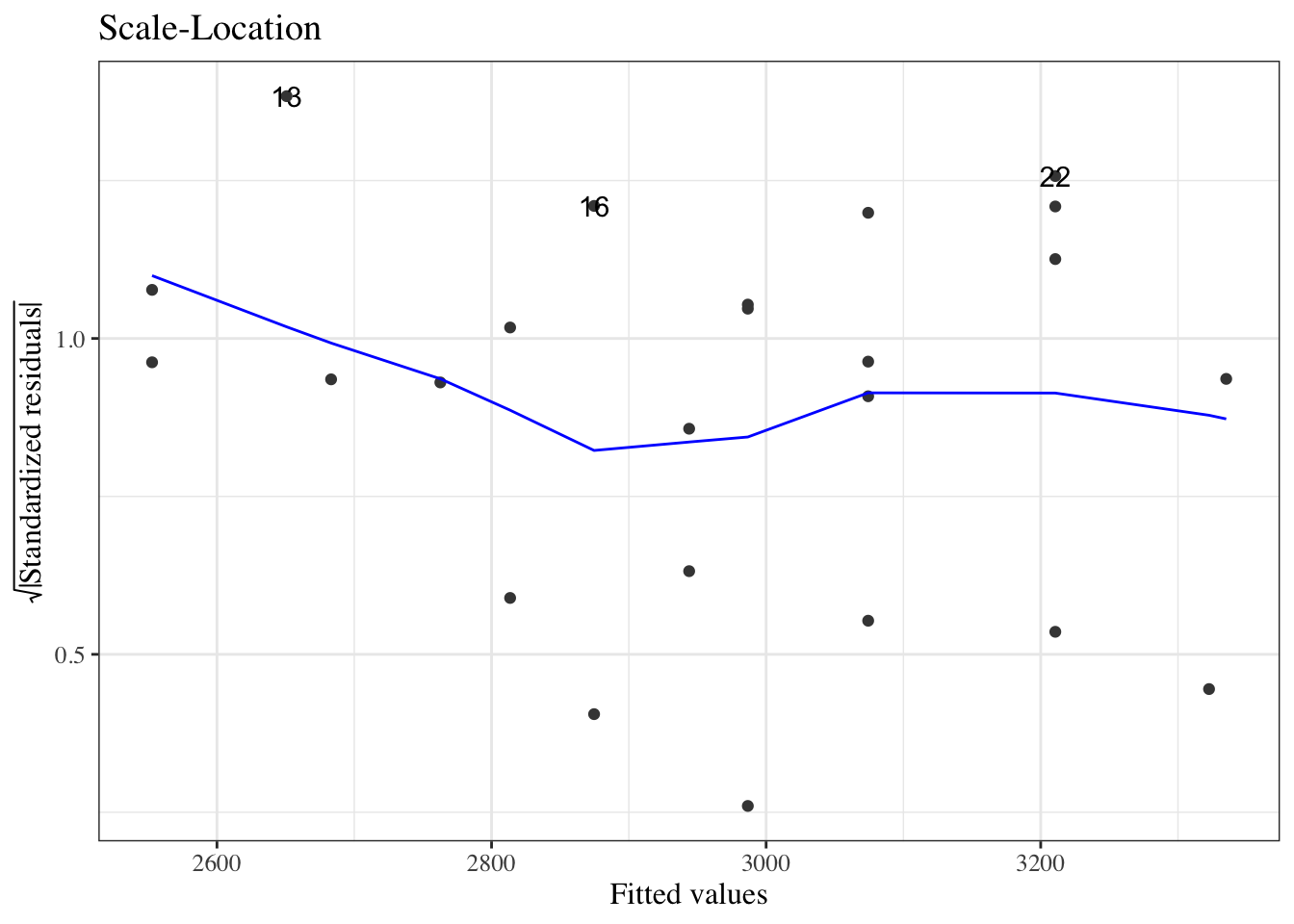
Fligner–Killeen / Levene summarizes the same heteroskedasticity signal that we inspect in residuals-vs-fitted (Figure 24) and scale-location (Figure 32) plots.
Shapiro–Wilk summarizes the same normality signal that we inspect in QQ plots (Figure 23 (c)) and standardized-residual histograms (Figure 21).
Use tests and plots together: the tests provide a single numerical summary, while the plots show the shape and practical size of departures.
Conditional distributions of residuals
If our Gaussian linear regression model is correct, the residuals \(r_i\) and standardized residuals \(r'_i\) should have:
an approximately Gaussian distribution, with:
a mean of 0
a constant variance
This should be true for every value of \(x\).
If we didn’t correctly guess the functional form of the linear component of the mean, for covariate vector \(x = (x_1,\ldots,x_p)\), \[\text{E}{\left[Y \mid X=x\right]} = \beta_0 + \beta_1 x_1 + \cdots + \beta_p x_p\]
Then the residuals might have nonzero mean.
Regardless of whether we guessed the mean function correctly, the variance of the residuals might differ between values of \(x\).
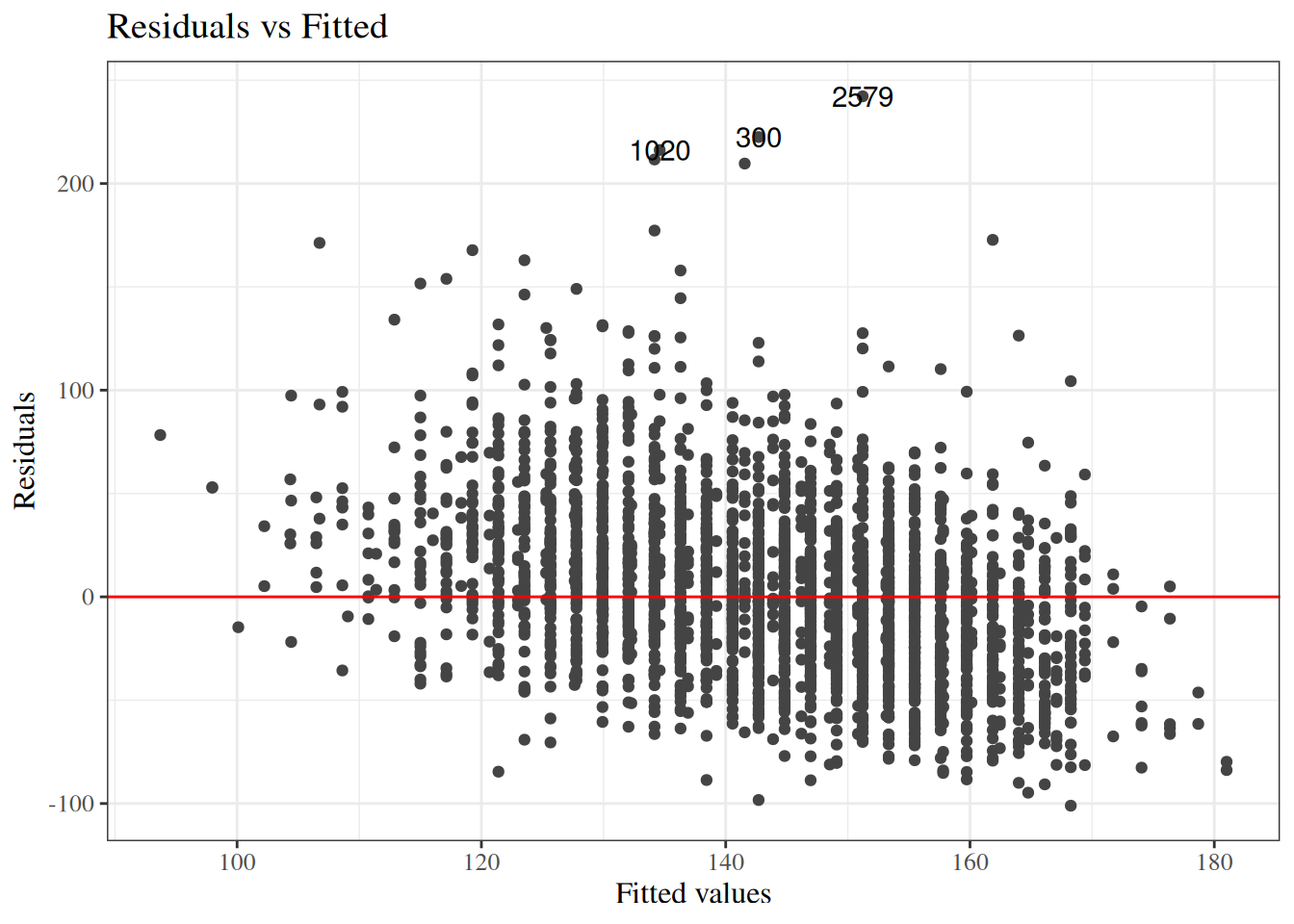
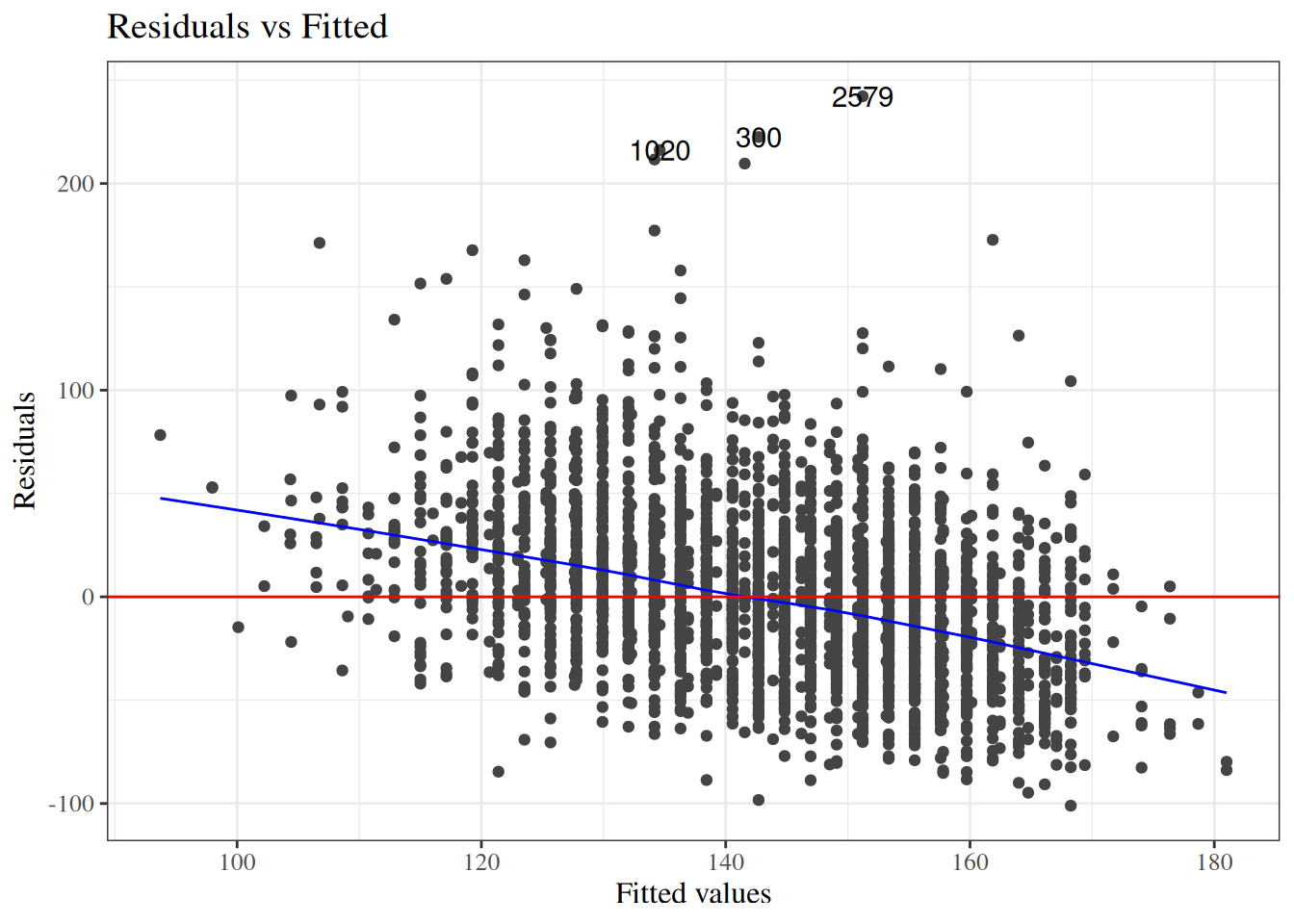
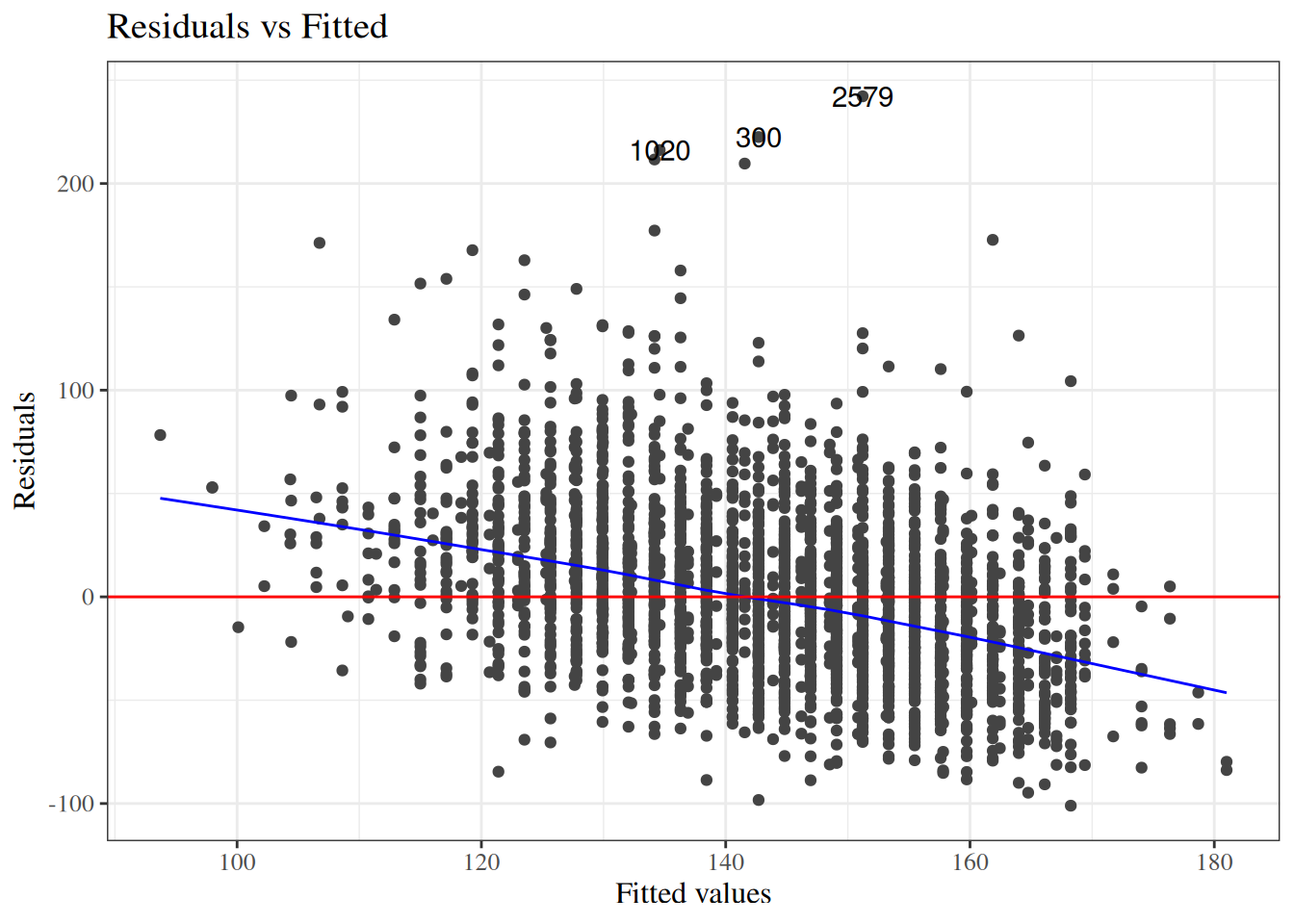
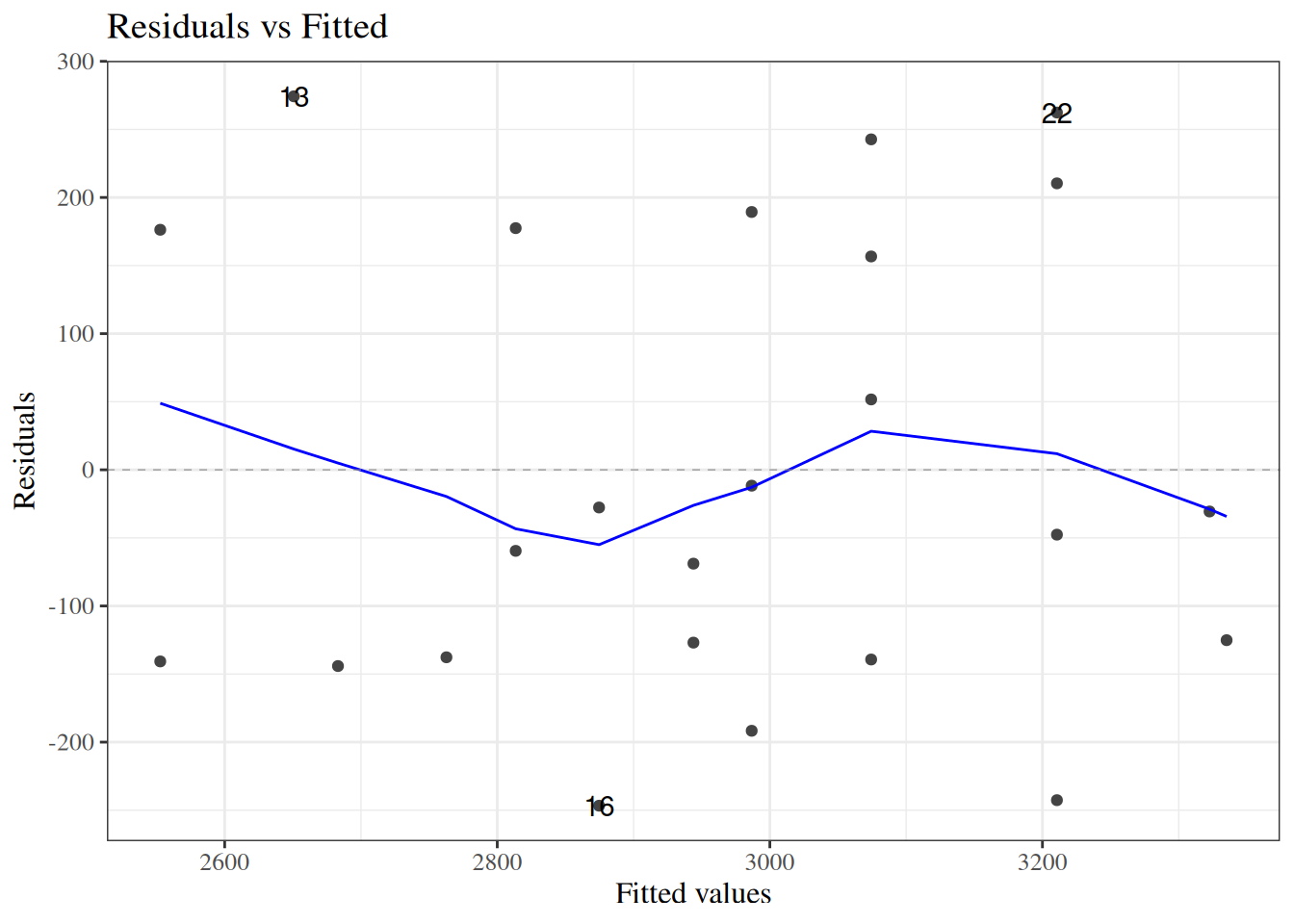
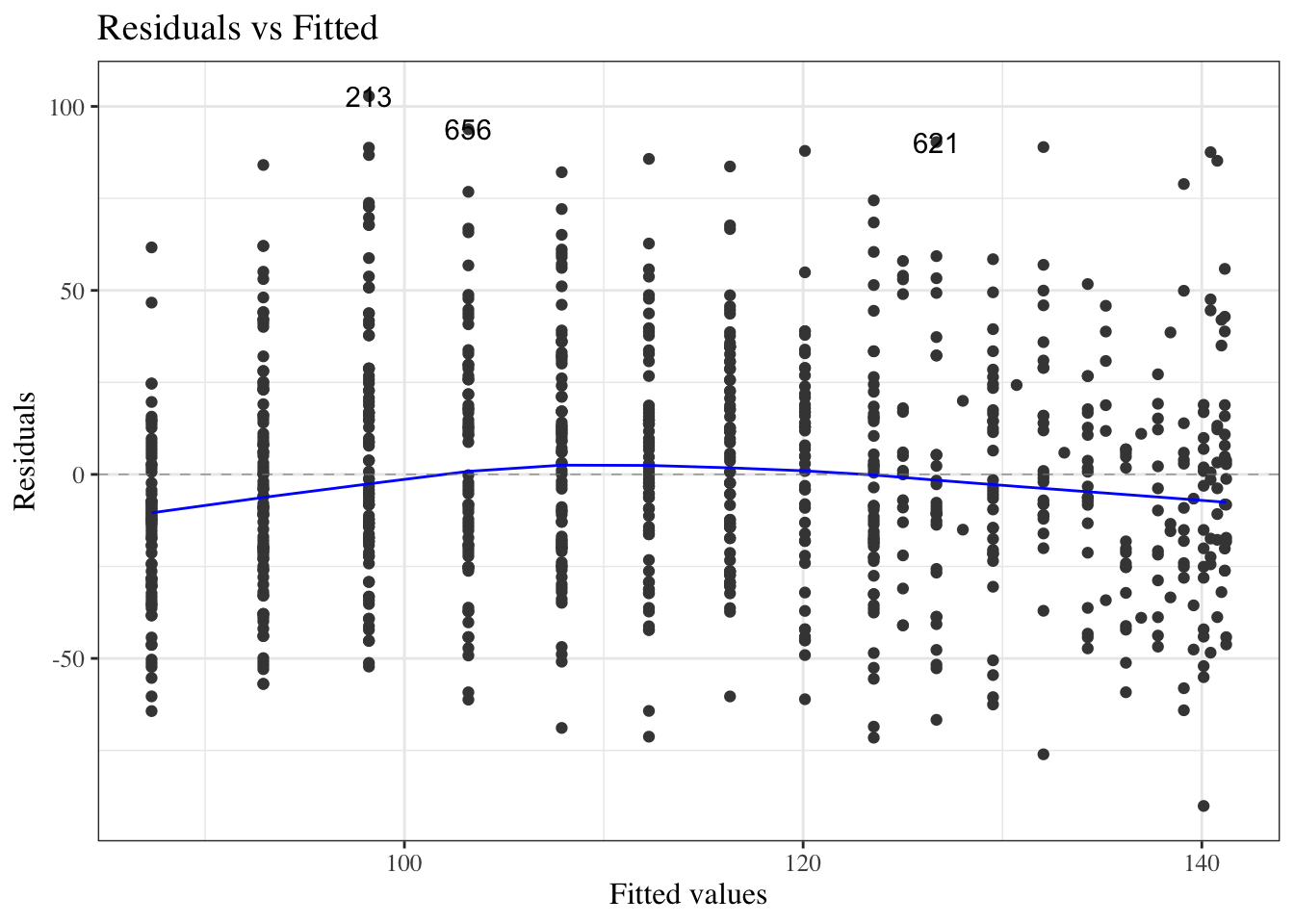
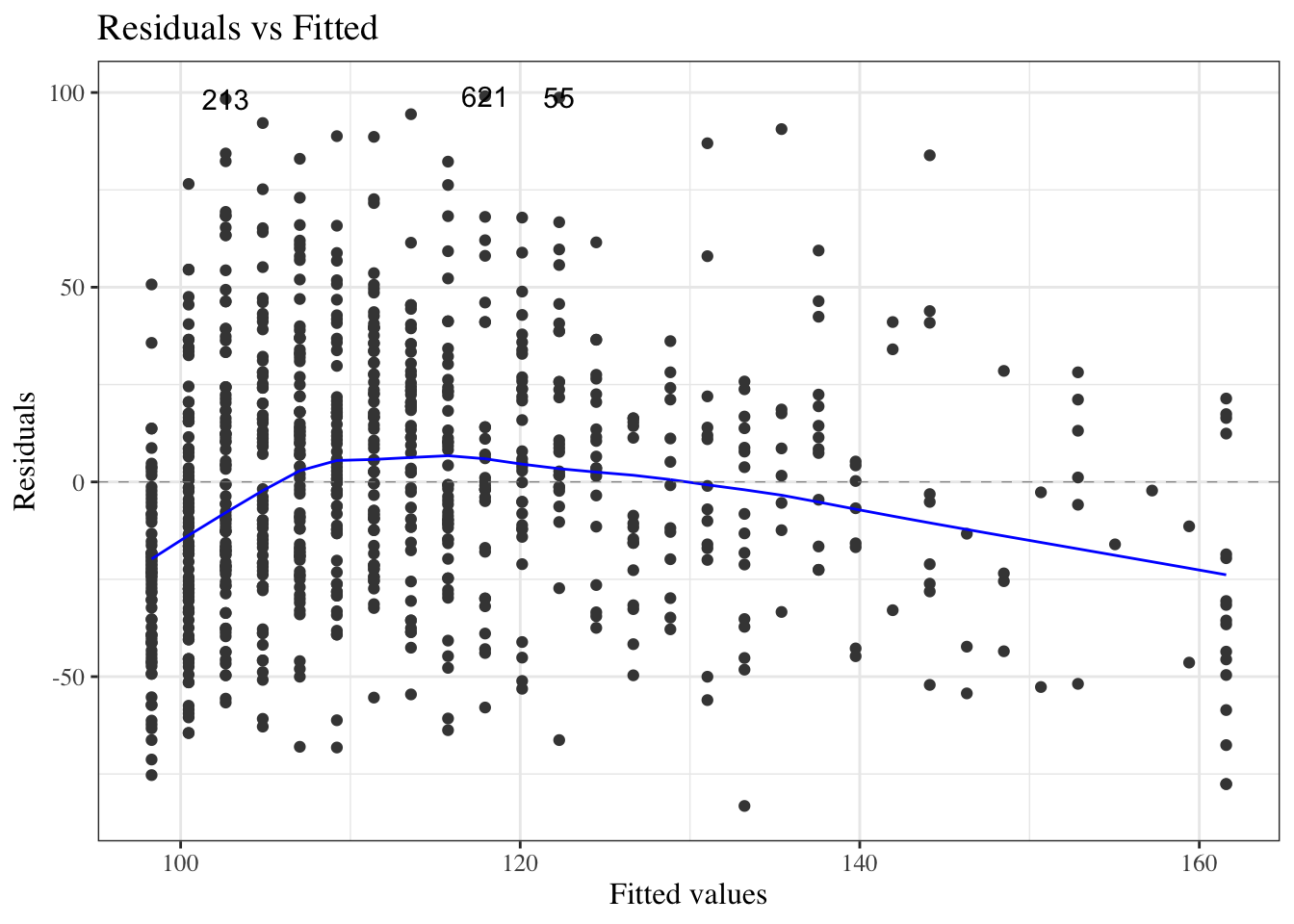
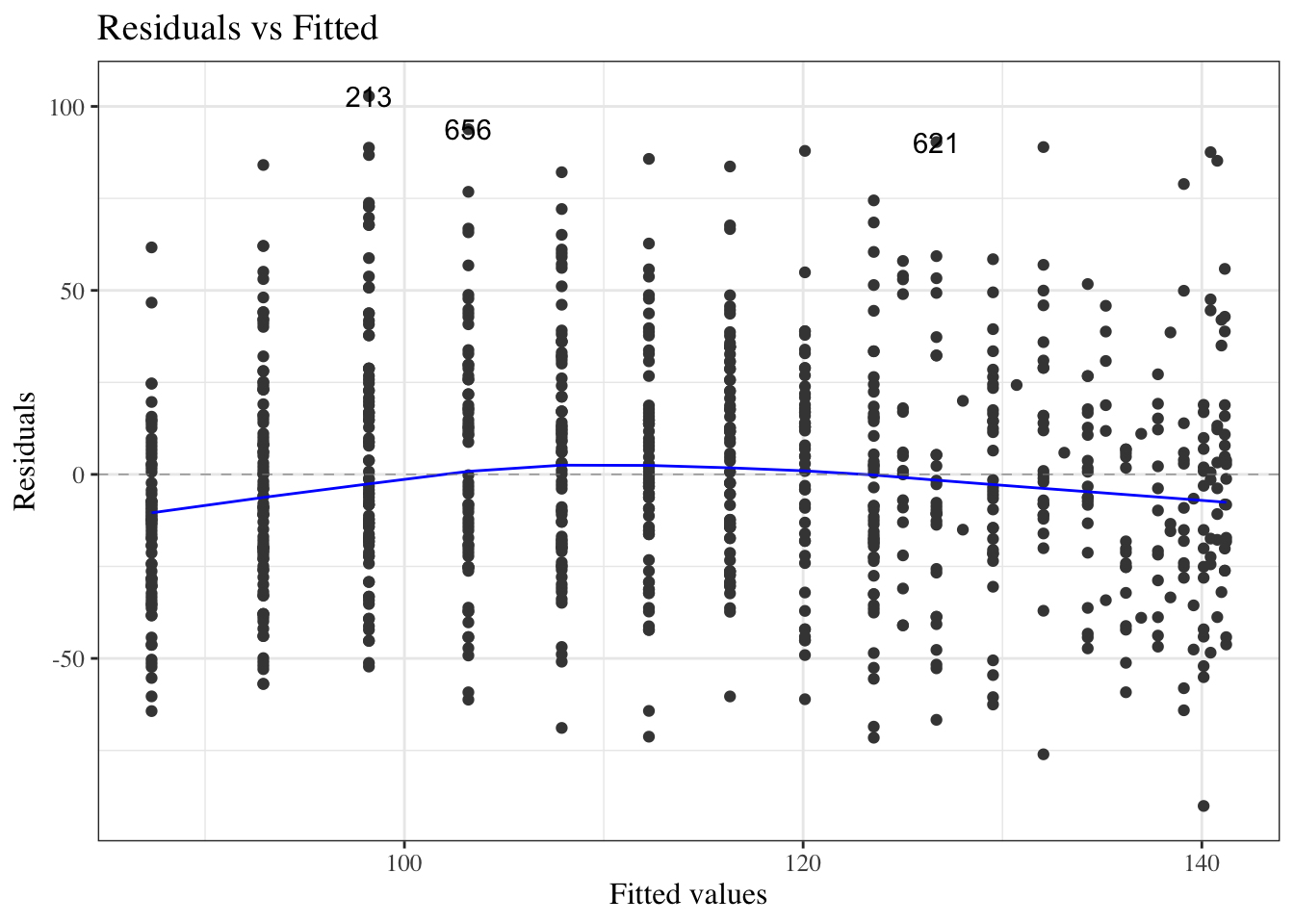
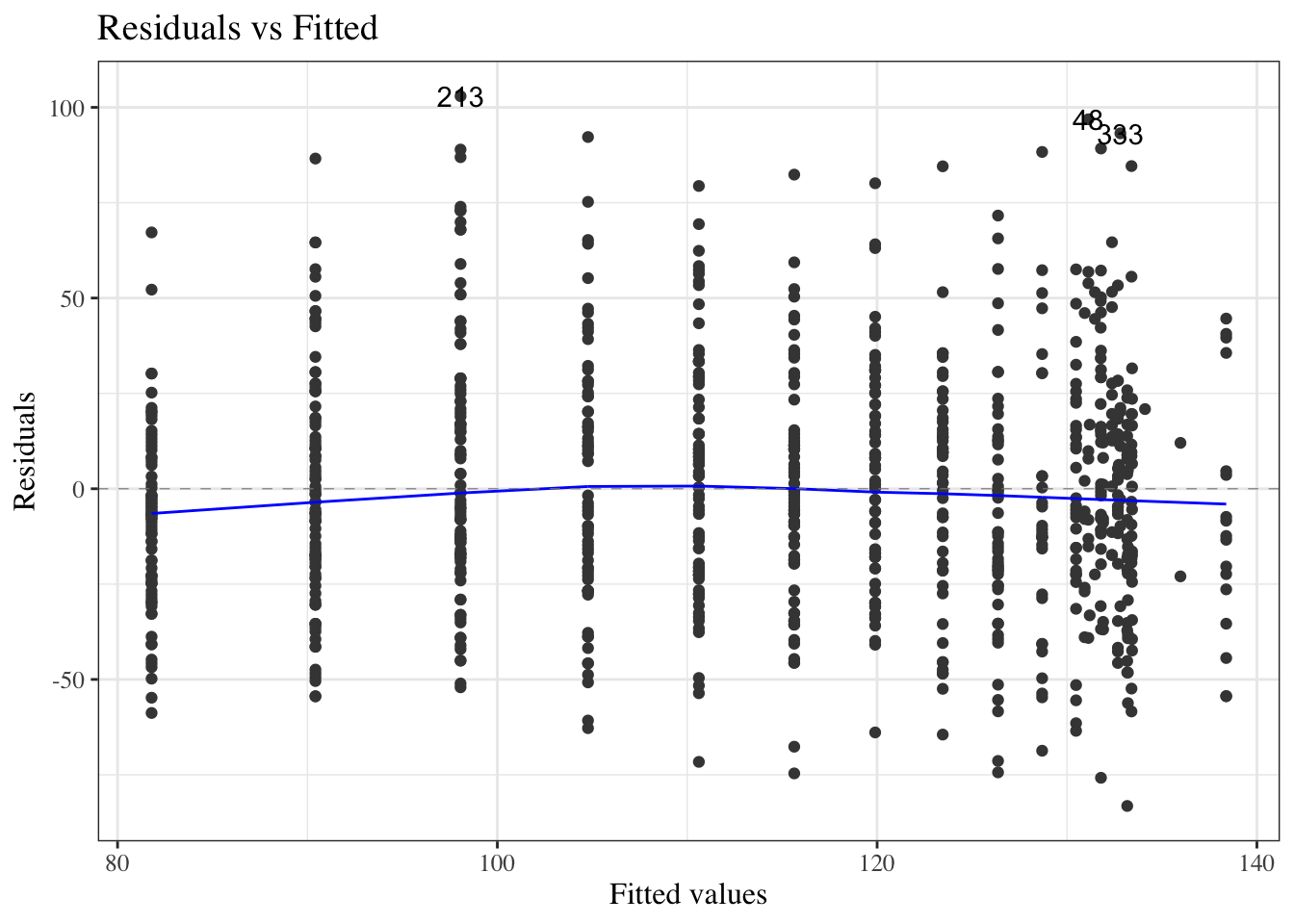
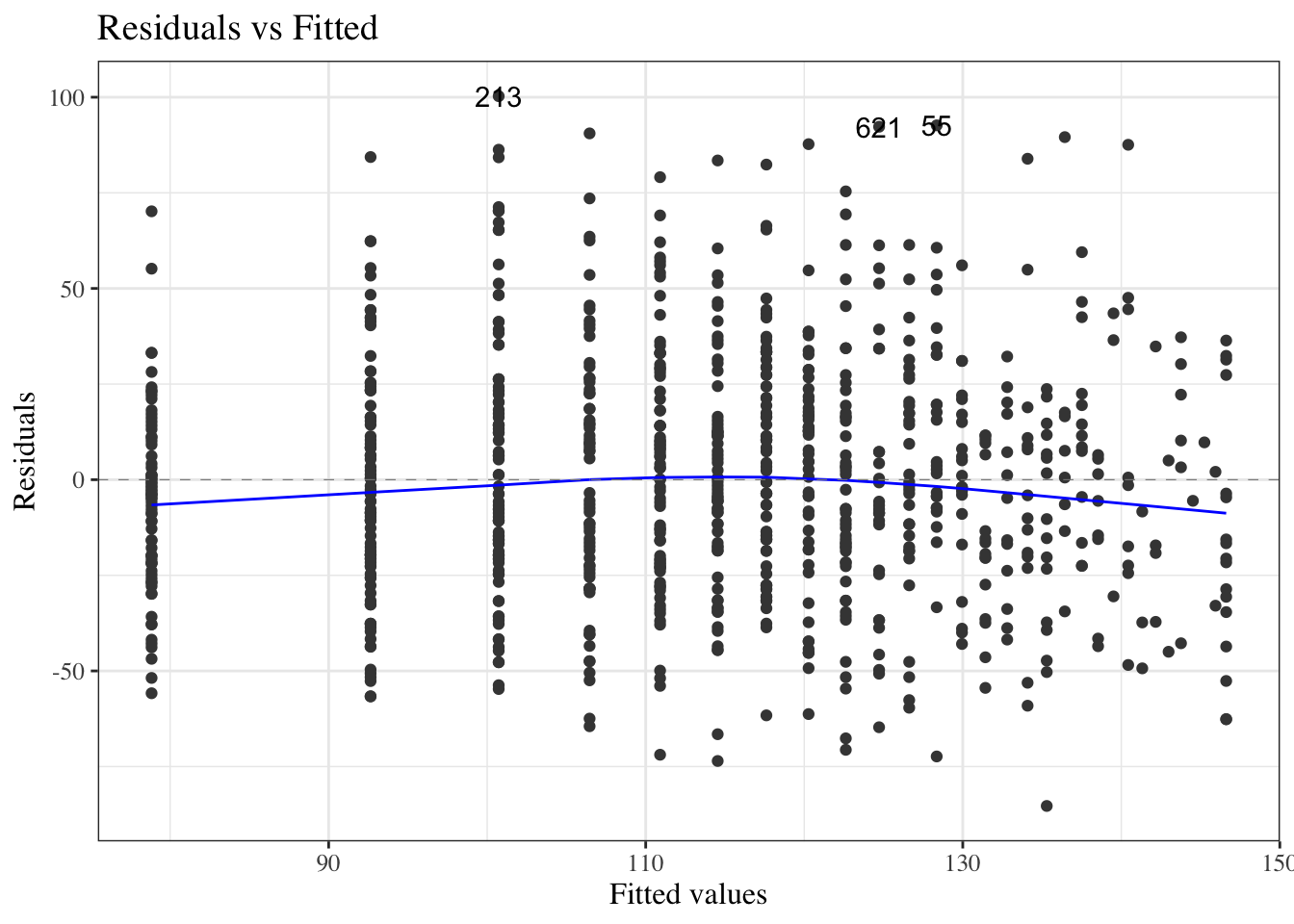
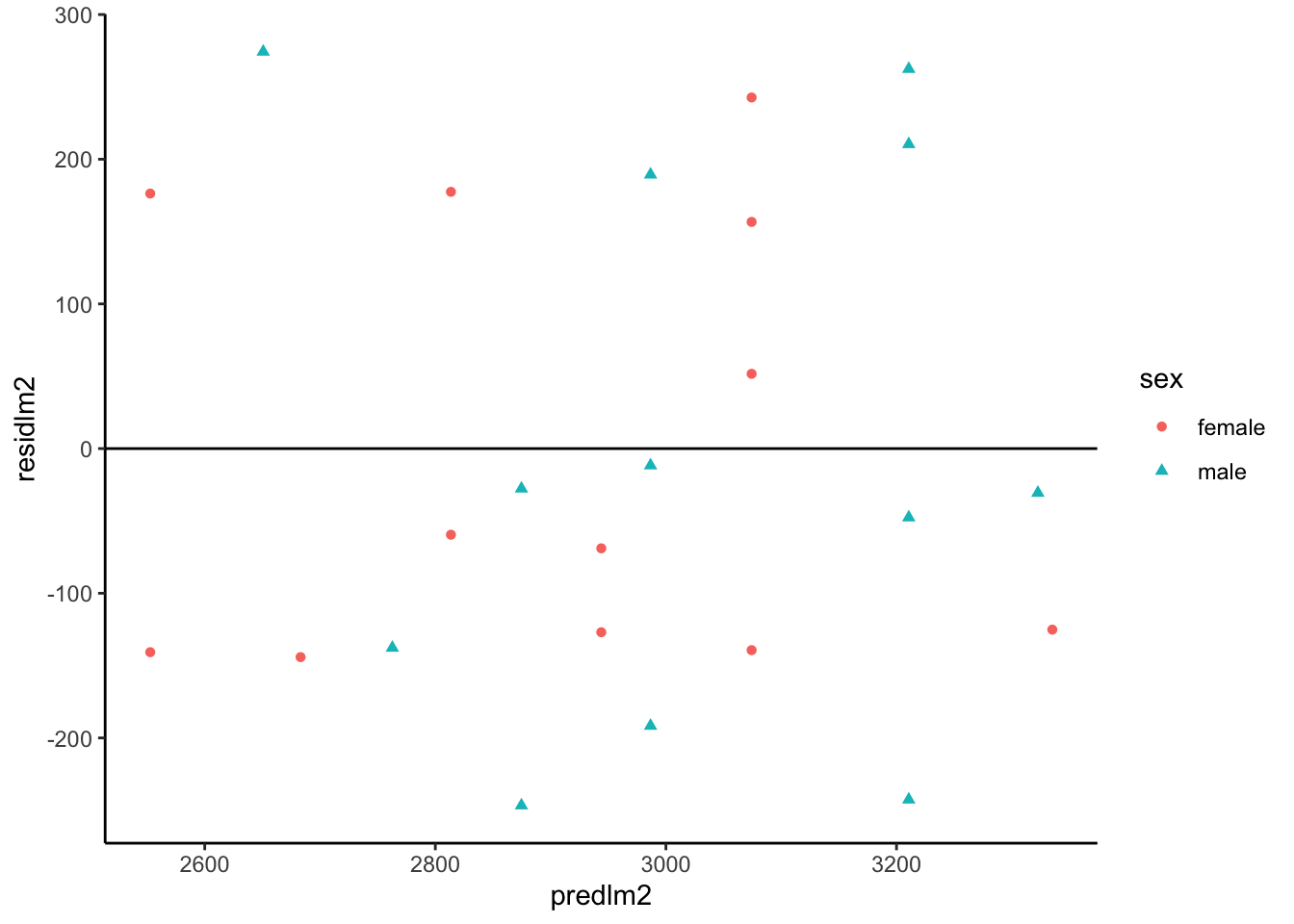
Residuals versus fitted values
[R code]
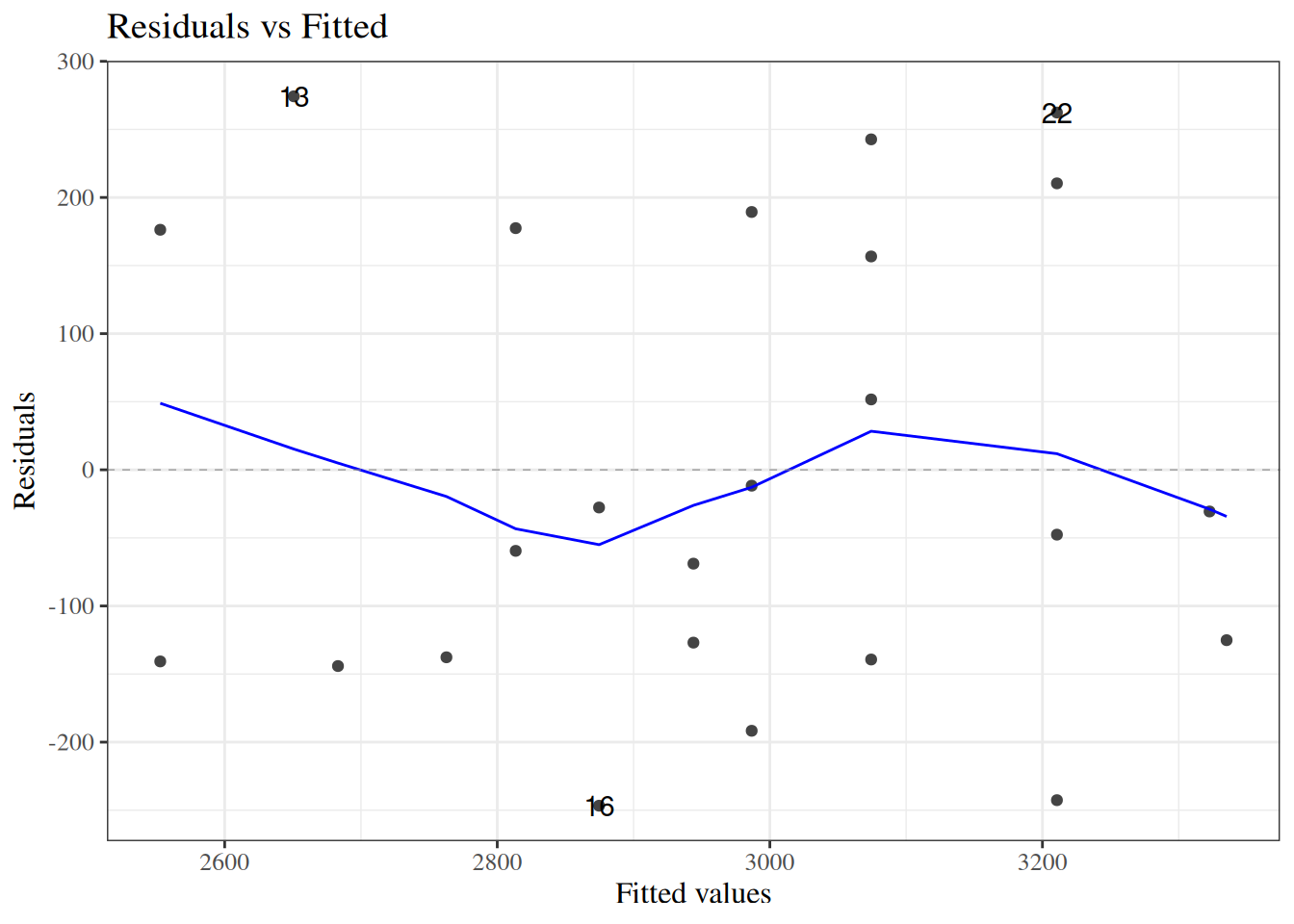
autoplot(bw_lm2, which =1, ncol =1) |>print()
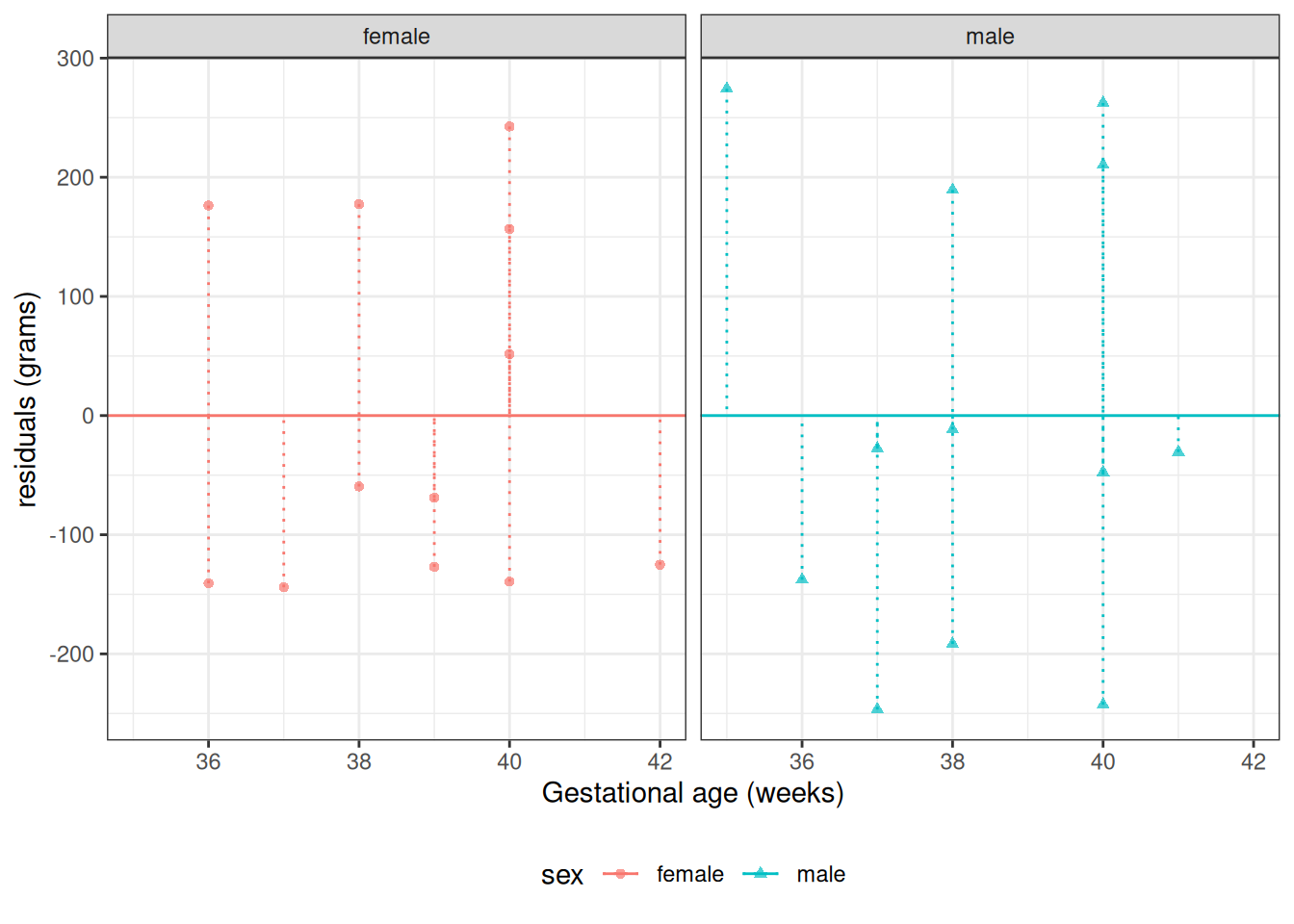
Figure 24: birthweight model (Equation 2): residuals versus fitted values
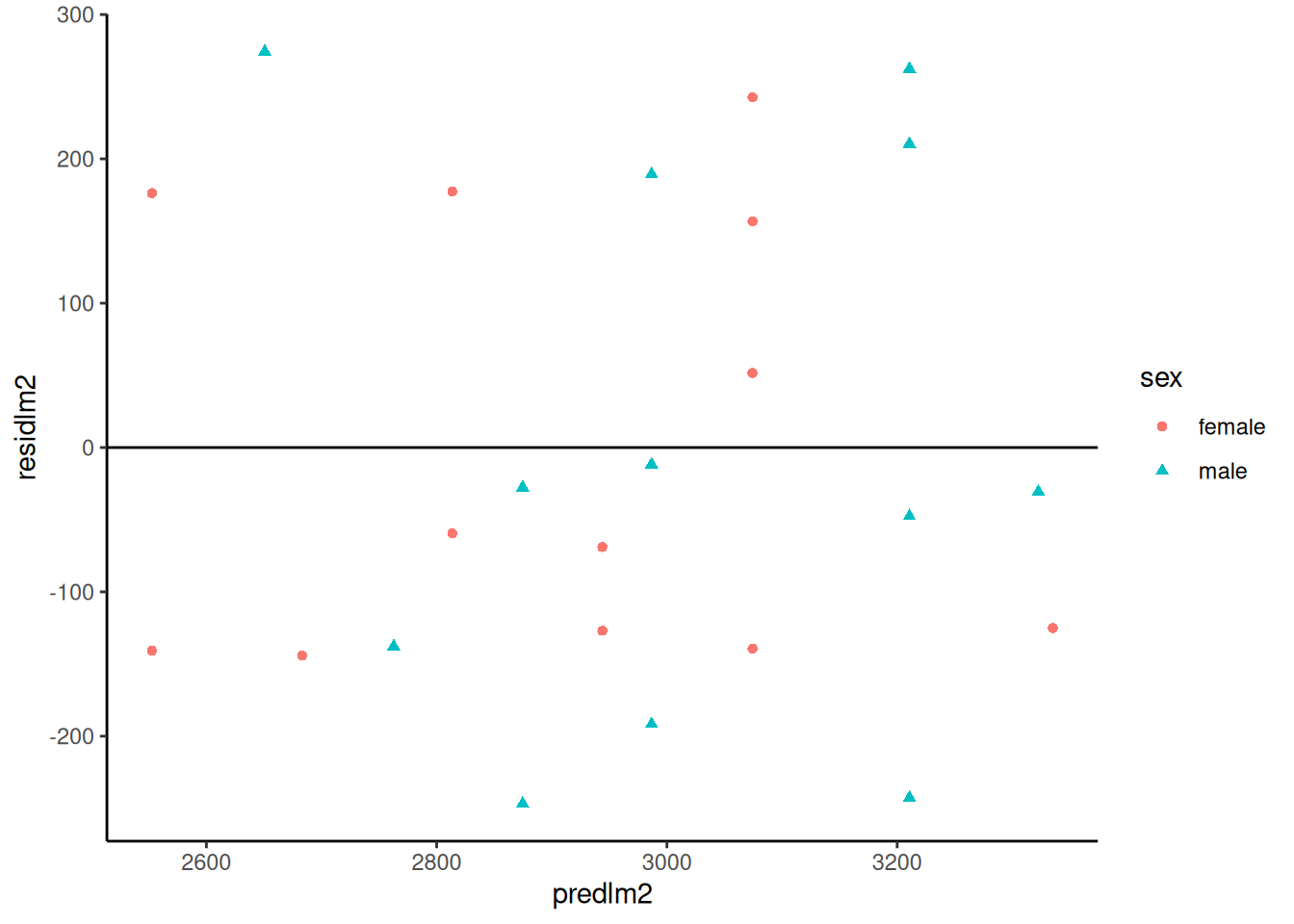
resid_vs_fit <- bw |>ggplot(aes(x = predlm2, y = residlm2, col = sex, shape = sex) ) +geom_point() +theme_classic() +geom_hline(yintercept =0)print(resid_vs_fit)
Standardized residuals vs fitted
[R code]
bw |>ggplot(aes(x = predlm2, y = std_resid, col = sex, shape = sex) ) +geom_point() +theme_classic() +geom_hline(yintercept =0)
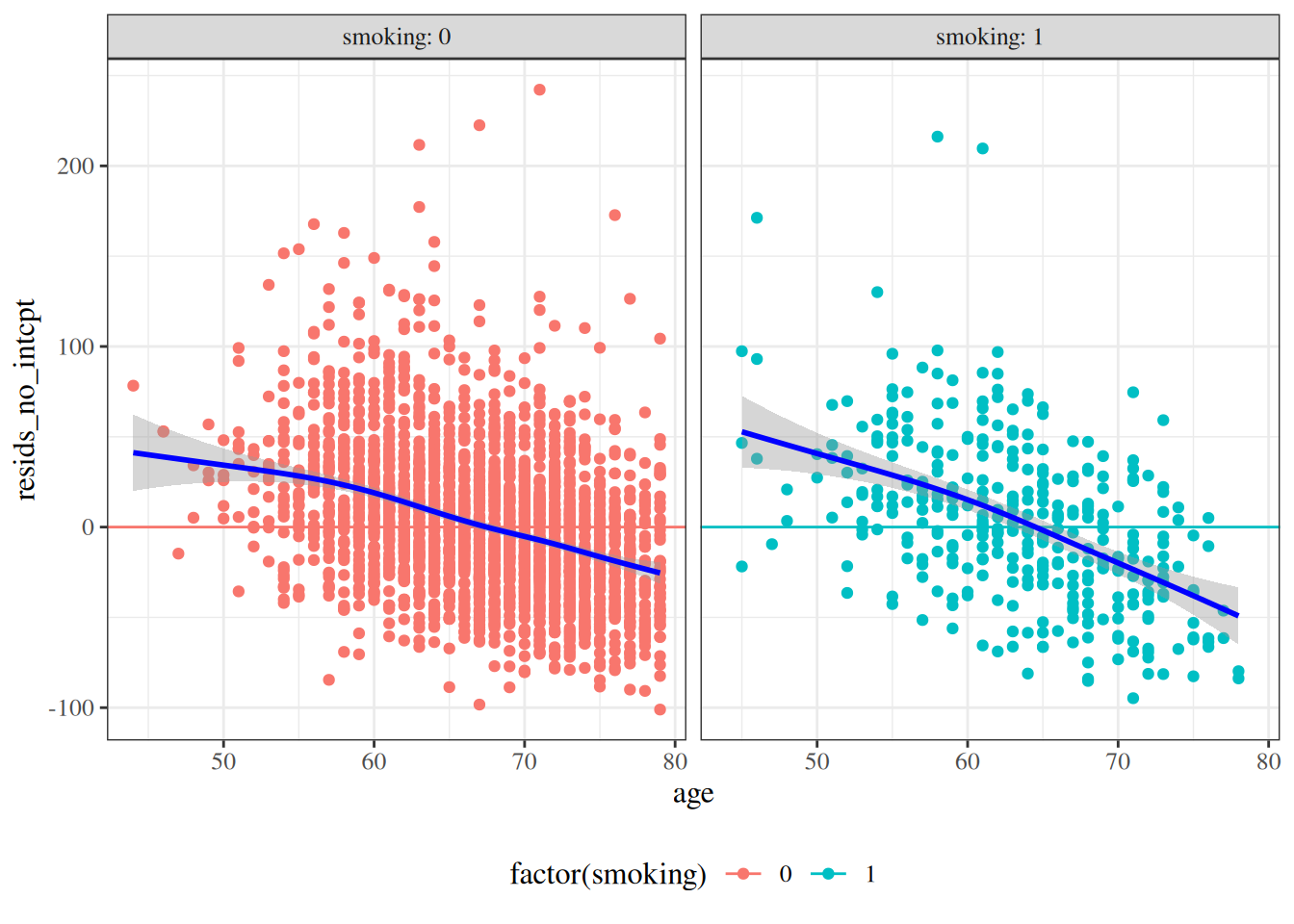
Standardized residuals vs gestational age
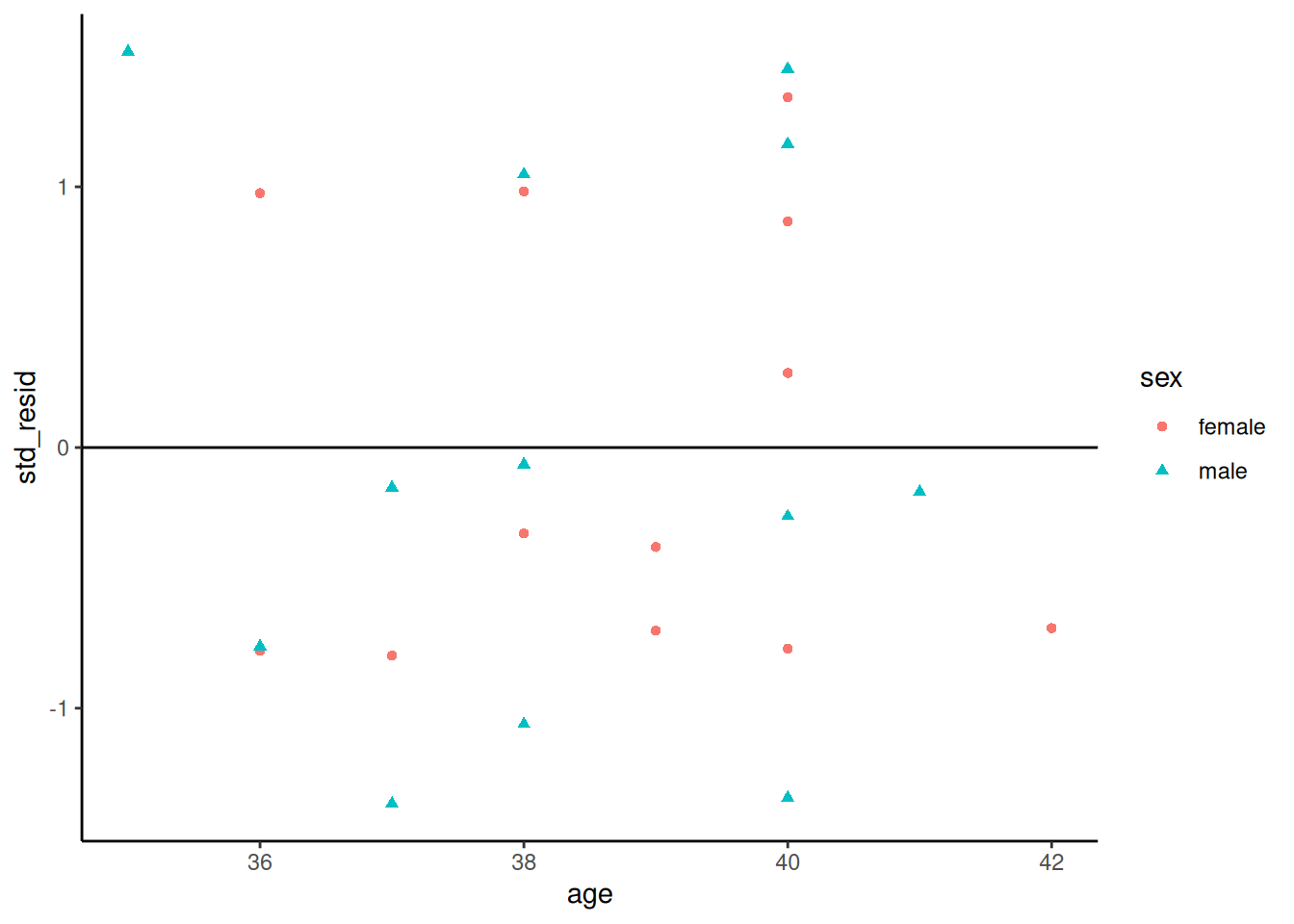
[R code]
bw |>ggplot(aes(x = age, y = std_resid, col = sex, shape = sex) ) +geom_point() +theme_classic() +geom_hline(yintercept =0)
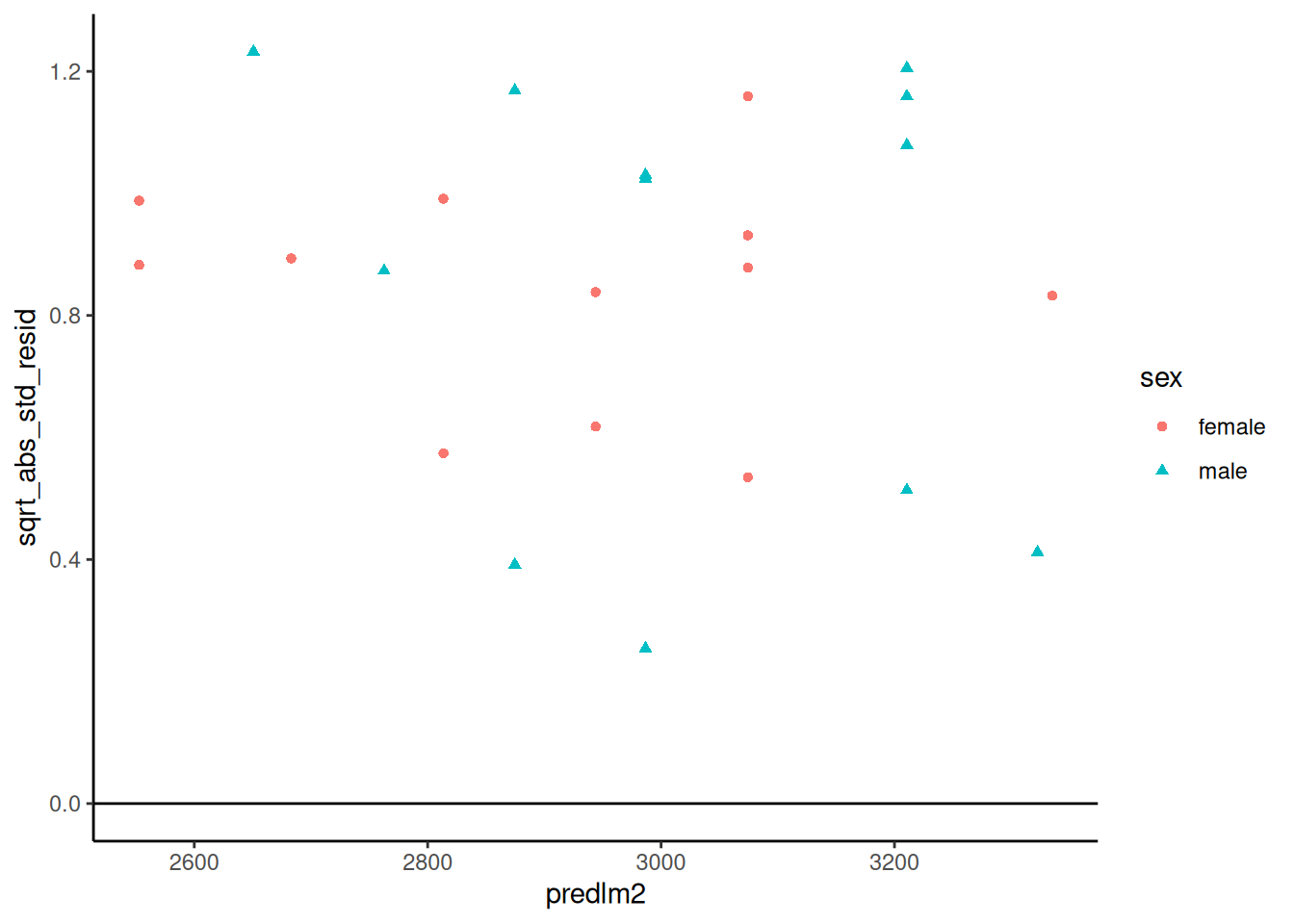
sqrt(abs(std_resid)) vs fitted
Compare with autoplot(bw_lm2, 3) (note: autoplot uses leverage-adjusted rstandard())
[R code]
bw |>ggplot(aes(x = predlm2, y = sqrt_abs_std_resid, col = sex, shape = sex) ) +geom_point() +theme_classic() +geom_hline(yintercept =0)
Diagnostics for the independence assumption
The independence assumption means that the model errors are independent, or at least uncorrelated, across observations after conditioning on the predictors in the model. Because those errors are unobserved, we usually assess this assumption using residual-based plots and formal tests.
Definition 12 (Common diagnostics for independence)
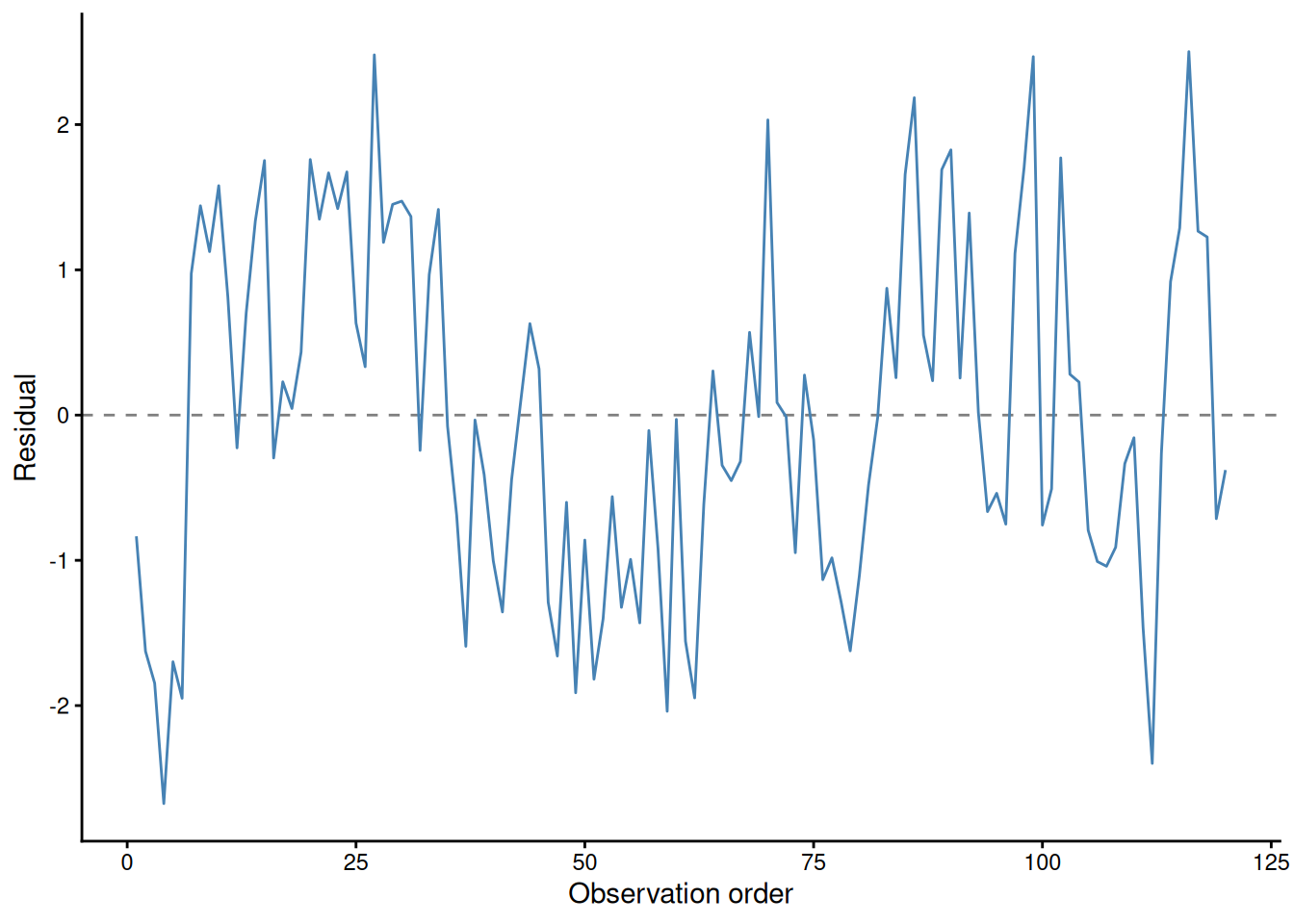
Residuals versus observation order (or time) plots: patterns, runs, or drifts can indicate dependence (Kutner et al. 2005, chap. 12).
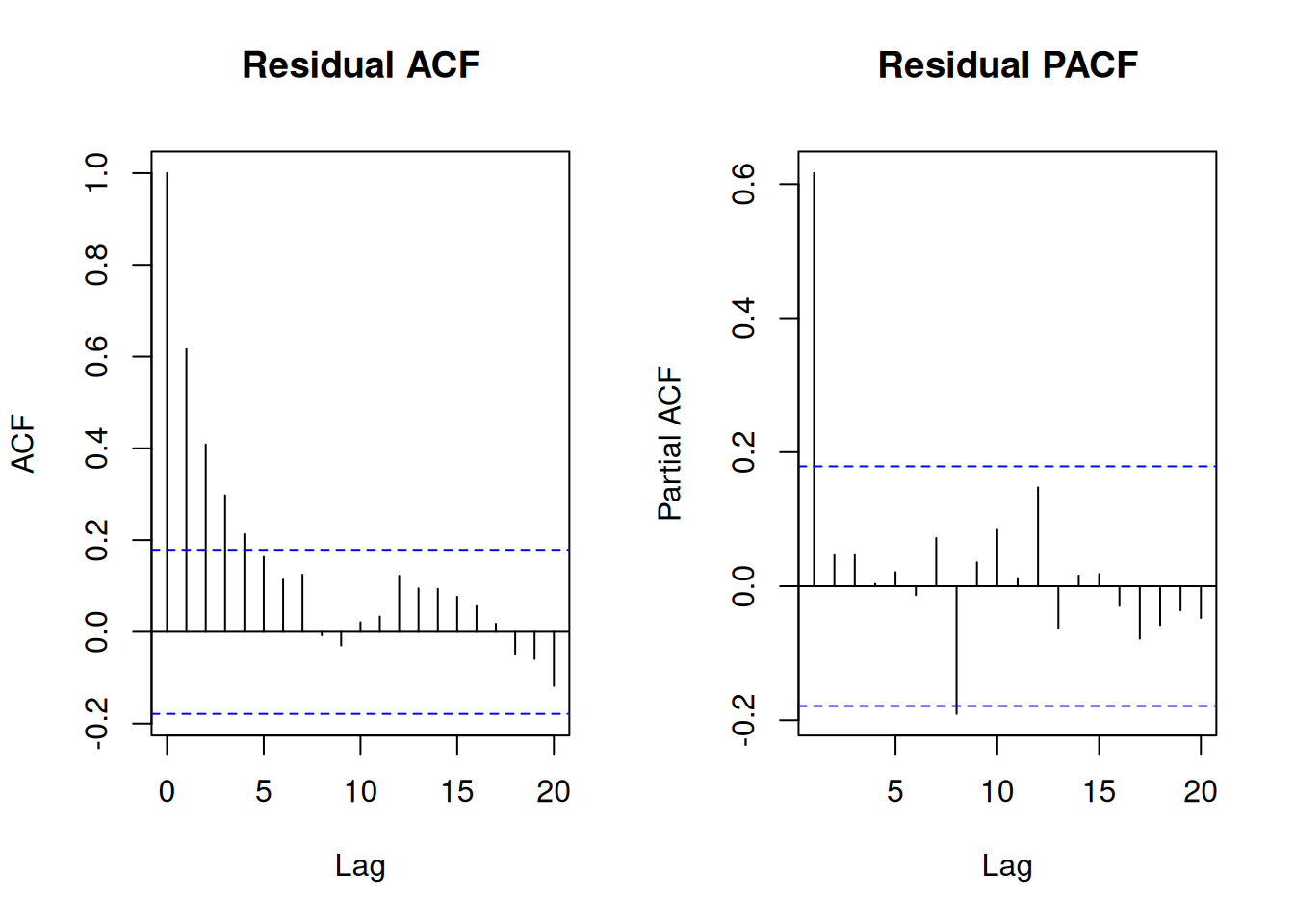
Correlograms: plot the sample autocorrelation function (ACF), and often the partial autocorrelation function (PACF), to look for serial structure (Chatterjee and Hadi 2015, chap. 6).
Mathematical details for Durbin-Watson and Breusch-Godfrey
Suppose the observations have a meaningful order, indexed by \(t = 1, \ldots, n\). Let \(e_t\) denote the OLS residual from a fitted regression model.
Definition 13 (Durbin-Watson diagnostic) The test statistic is \[
\begin{aligned}
d
&= \frac{\sum_{t = 2}^{n} (e_t - e_{t-1})^2}
{\sum_{t = 1}^{n} e_t^2}
\end{aligned}
\] which is approximately \(2(1 - \hat r_1)\), where \(\hat r_1\) is the sample lag-1 residual autocorrelation (Kutner et al. 2005, chap. 12; Chatterjee and Hadi 2015, chap. 6). This approximation is most useful in standard large-sample linear-model settings, and is less straightforward in models with lagged outcomes (Kutner et al. 2005, chap. 12).
The null and alternatives are typically framed through an AR(1) error model: \[
\varepsilon_t = \rho \varepsilon_{t-1} + u_t.
\] Here, \(\varepsilon_t\) is the autocorrelated regression error process, and \(u_t\) is a white-noise innovation term. The null is \(H_0: \rho = 0\), and alternatives can be one-sided or two-sided, depending on whether we suspect positive, negative, or any serial correlation (Kutner et al. 2005, chap. 12).
Definition 14 (Breusch-Godfrey diagnostic) For a test of order \(p\), we run an auxiliary regression of residuals on: the original regressors, and lagged residuals \(e_{t-1}, \ldots, e_{t-p}\). If \(R^2_{\text{aux}}\) is from that auxiliary model, the LM statistic is \[
\text{LM} = (n - p)R^2_{\text{aux}},
\] and under \(H_0: \rho_1 = \cdots = \rho_p = 0\), it is asymptotically \(\chi^2_p\)(Chatterjee and Hadi 2015, chap. 6; Draper and Smith 2014, chap. 11).
Example 4 (Simulated example for independence diagnostics) The example below simulates ordered data with positively autocorrelated errors. That creates a setting where independence should fail. We generate the error term from an AR(1) process with coefficient 0.7, matching the notation in the mathematical details section.
set.seed(204)n_obs <-120x <-seq(-1, 1, length.out = n_obs)ar_errors <-as.numeric(arima.sim(model =list(ar =0.7), n = n_obs, sd =1))y <-2+1.5* x + ar_errorsserial_dep_exm <- tibble::tibble(time_index =seq_len(n_obs),x = x,y = y)serial_dep_exm_lm <-lm(y ~ x, data = serial_dep_exm)summary(serial_dep_exm_lm)#> #> Call:#> lm(formula = y ~ x, data = serial_dep_exm)#> #> Residuals:#> Min 1Q Median 3Q Max #> -2.6747 -0.9128 -0.0552 1.0087 2.5022 #> #> Coefficients:#> Estimate Std. Error t value Pr(>|t|) #> (Intercept) 1.998 0.110 18.13 < 2e-16 ***#> x 1.773 0.189 9.37 6.4e-16 ***#> ---#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#> #> Residual standard error: 1.21 on 118 degrees of freedom#> Multiple R-squared: 0.426, Adjusted R-squared: 0.422 #> F-statistic: 87.7 on 1 and 118 DF, p-value: 6.36e-16
Figure 35: Residual ACF and PACF for simulated data
Durbin-Watson and Breusch-Godfrey tests:
lmtest::dwtest(serial_dep_exm_lm, alternative ="two.sided")#> #> Durbin-Watson test#> #> data: serial_dep_exm_lm#> DW = 0.7623, p-value = 4.16e-12#> alternative hypothesis: true autocorrelation is not 0lmtest::bgtest(serial_dep_exm_lm, order =4)#> #> Breusch-Godfrey test for serial correlation of order up to 4#> #> data: serial_dep_exm_lm#> LM test = 45.94, df = 4, p-value = 2.53e-09
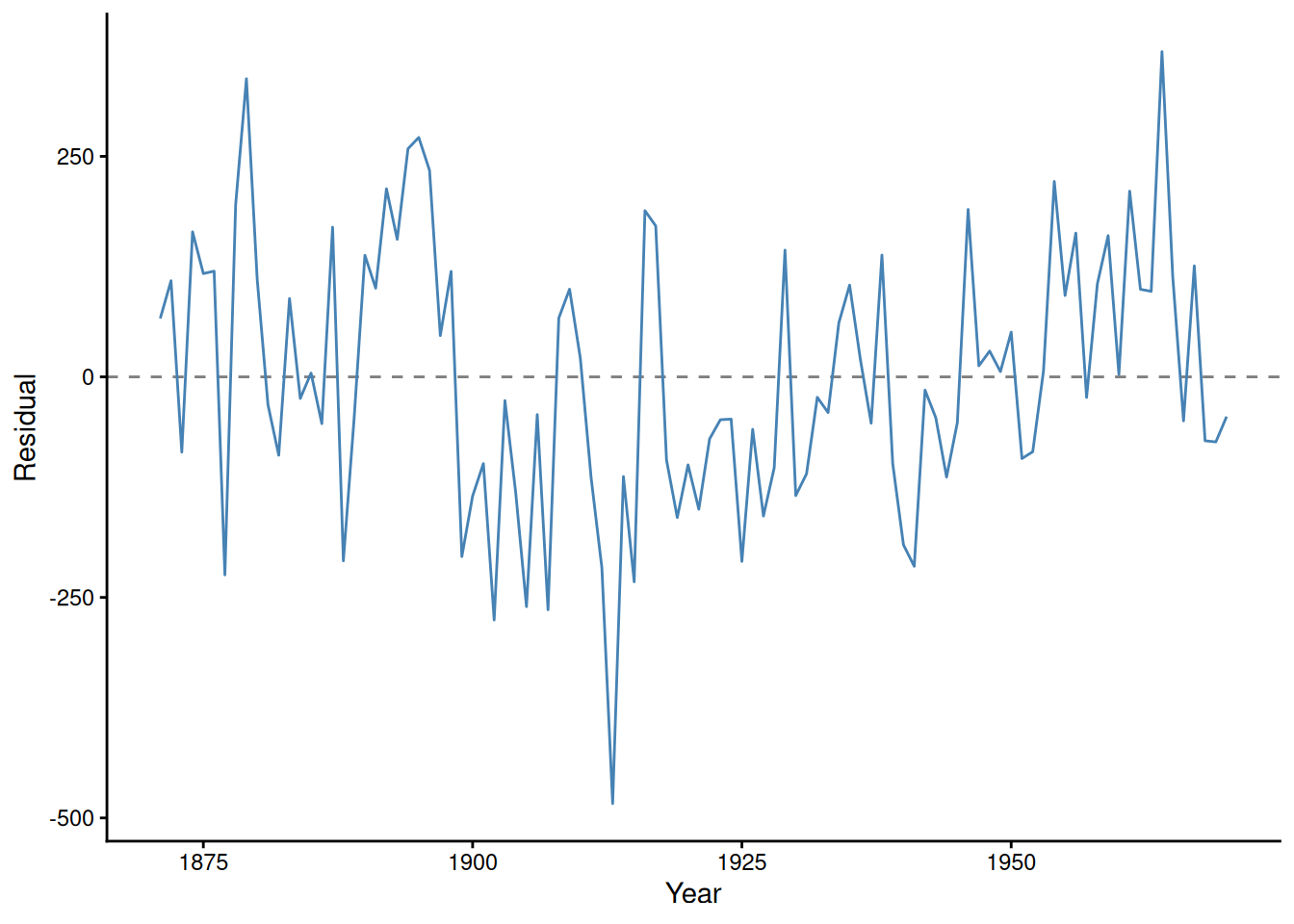
In this example, the residual-order plot and correlogram suggest serial dependence, and both formal tests reject independence.
Example 5 (Real-data examples for independence diagnostics) We can also run the same diagnostics on real ordered data sets.
Nile annual river flow
nile_df <- tibble::tibble(year =as.numeric(time(datasets::Nile)),flow =as.numeric(datasets::Nile))nile_lm <-lm(flow ~ year, data = nile_df)summary(nile_lm)#> #> Call:#> lm(formula = flow ~ year, data = nile_df)#> #> Residuals:#> Min 1Q Median 3Q Max #> -483.7 -98.2 -23.2 111.4 368.7 #> #> Coefficients:#> Estimate Std. Error t value Pr(>|t|) #> (Intercept) 6132.174 1001.758 6.12 1.9e-08 ***#> year -2.714 0.522 -5.20 1.1e-06 ***#> ---#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#> #> Residual standard error: 151 on 98 degrees of freedom#> Multiple R-squared: 0.217, Adjusted R-squared: 0.209 #> F-statistic: 27.1 on 1 and 98 DF, p-value: 1.07e-06lmtest::dwtest(nile_lm, alternative ="two.sided")#> #> Durbin-Watson test#> #> data: nile_lm#> DW = 1.247, p-value = 9.37e-05#> alternative hypothesis: true autocorrelation is not 0lmtest::bgtest(nile_lm, order =4)#> #> Breusch-Godfrey test for serial correlation of order up to 4#> #> data: nile_lm#> LM test = 15.94, df = 4, p-value = 0.0031
(adapted from Dobson and Barnett (2018) §6.3.3; for more information on prediction, see James et al. (2013) and Harrell (2015)).
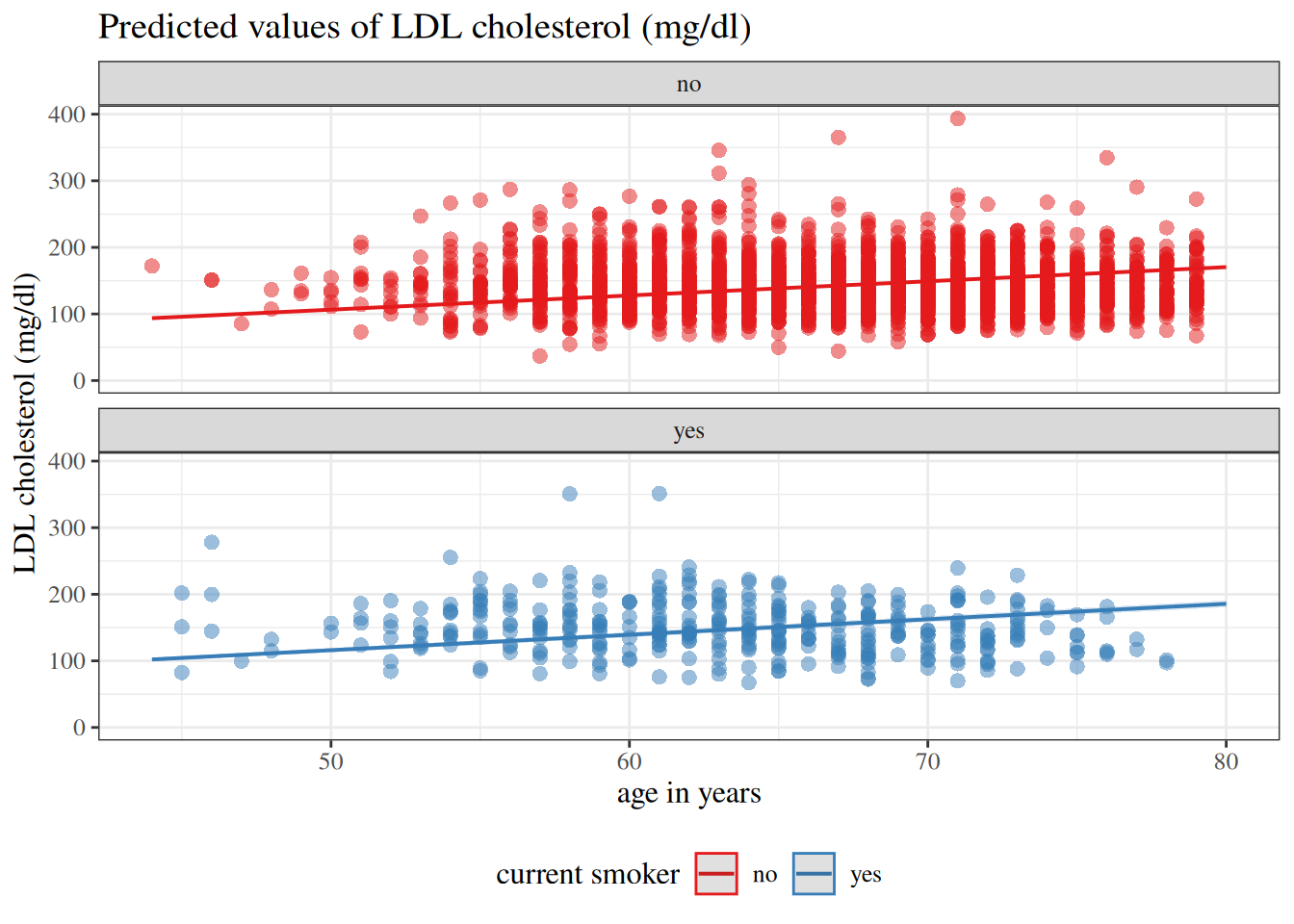
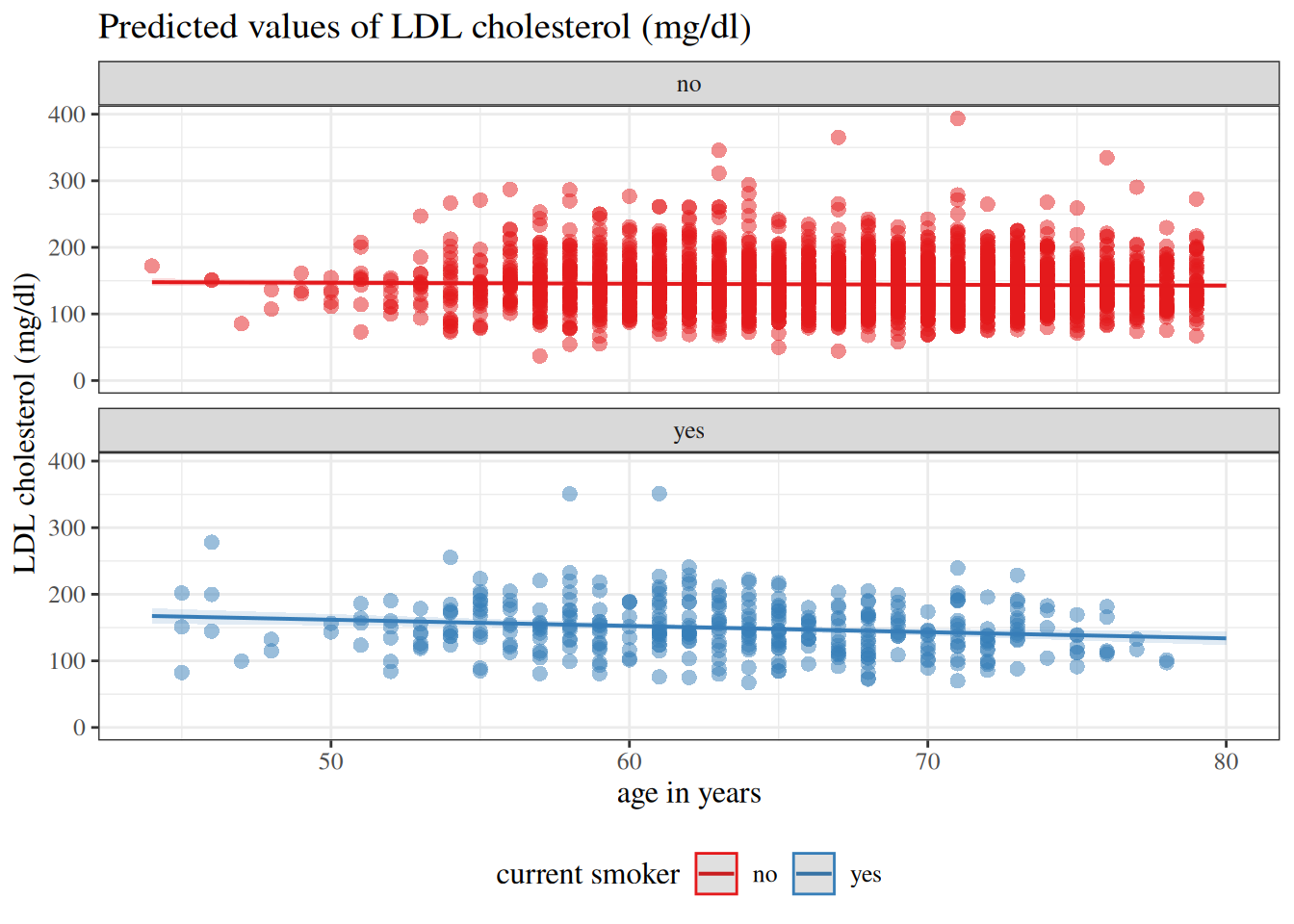
DAGs for variable selection
For explanatory models, variable inclusion should not rely on automated algorithms alone. Directed acyclic graphs (DAGs) can help us encode substantive assumptions about which variables are confounders, mediators, or colliders.
In a Dobson-style workflow, we use the DAG first to decide a defensible adjustment set, then compare candidate regression models within that set using predictive or likelihood-based criteria. This keeps model selection aligned with study design, rather than only with numerical fit.
In this workflow, the DAG encodes hypothesized time ordering and causal pathways. That helps us decide which variables belong in the candidate model set before we run stepwise, subset, or penalized selection methods. The key point is that a variable can improve apparent fit while still distorting the effect we care about if it sits on a causal pathway or induces collider bias (Dobson and Barnett 2018, sec. 6.3.3).
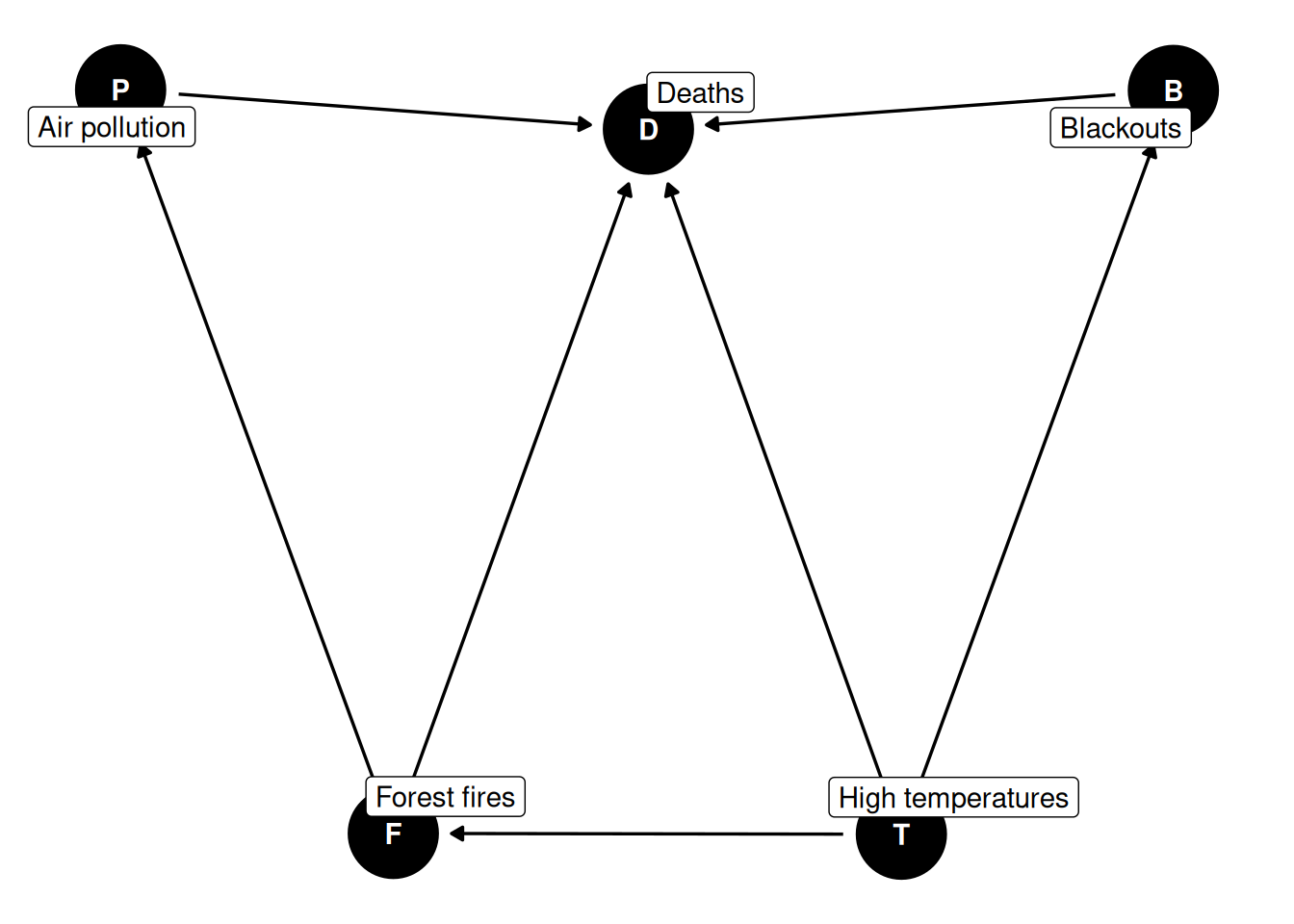
Example 6 (high temperatures and mortality) Suppose the research question is: “What is the effect of high temperatures on deaths?”
A plausible DAG includes: high temperatures \(\rightarrow\) deaths, high temperatures \(\rightarrow\) blackouts, high temperatures \(\rightarrow\) forest fires, blackouts \(\rightarrow\) deaths, forest fires \(\rightarrow\) air pollution, and both forest fires and air pollution \(\rightarrow\) deaths (Dobson and Barnett 2018, sec. 6.3.3).
[R code]
dag_heat_deaths <- ggdag::dagify( D ~ T + B + F + P, B ~ T, F ~ T, P ~ F,exposure ="T",outcome ="D",labels =c(T ="High temperatures",D ="Deaths",B ="Blackouts",F ="Forest fires",P ="Air pollution" ))dag_heat_deaths |> ggdag::ggdag(use_labels ="label") + ggdag::theme_dag()
Figure 37: DAG for the high temperatures and mortality example.
If our estimand is the total effect of high temperatures on deaths, then blackouts, forest fires, and air pollution are mediators on downstream pathways. Adjusting for them would remove part of the effect we are trying to estimate.
But if the estimand changes to the effect of blackouts on deaths, then high temperatures become a confounder because they are a common cause of both blackouts and deaths. So the same variable can be “adjust for” or “do not adjust for” depending on the causal question.
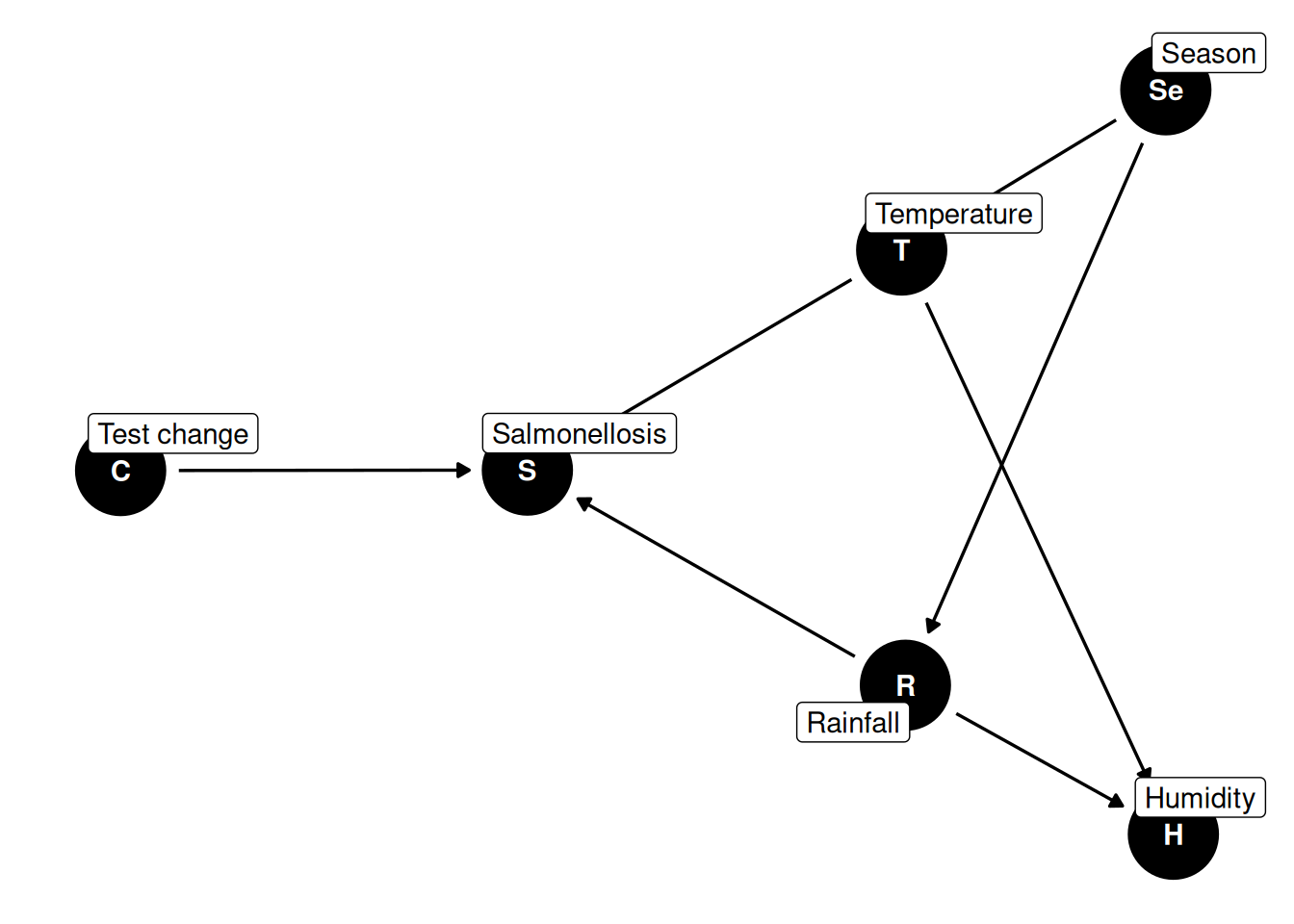
Example 7 (salmonellosis and weather) For daily salmonellosis counts, a plausible DAG has temperature and rainfall as direct causes of risk, with both variables also affecting humidity. If humidity has no direct arrow to salmonellosis, then humidity is not a causal driver; it mainly reflects shared variation from temperature and rainfall. Including humidity in the regression is therefore usually unnecessary for estimating the weather effects, and it may reduce interpretability because humidity is a collider of temperature and rainfall. Conditioning on humidity can induce misleading associations and bias weather-effect estimates when that conditioning opens a path between temperature and rainfall that is not otherwise blocked (Dobson and Barnett 2018, sec. 6.3.3).
[R code]
dag_salmonellosis_weather <- ggdag::dagify( S ~ T + R + C, H ~ T + R, T ~ Se, R ~ Se,labels =c(S ="Salmonellosis",T ="Temperature",R ="Rainfall",H ="Humidity",C ="Test change",Se ="Season" ))dag_salmonellosis_weather |> ggdag::ggdag(use_labels ="label") + ggdag::theme_dag()
Figure 38: DAG for the salmonellosis and weather example.
The same DAG can include a “change in test” indicator when surveillance switched to a more sensitive diagnostic test. That variable can improve predictive accuracy and face validity, but omitting it does not invalidate causal interpretation for temperature and rainfall effects if it is not on their causal paths (Dobson and Barnett 2018, sec. 6.3.3).
Likewise, season may cause both temperature and rainfall, but if season has no direct path to salmonellosis beyond those weather variables, including season can obscure interpretation of the proximal weather effects (Dobson and Barnett 2018, sec. 6.3.3).
Finally, DAG-informed variable definitions matter. In one intensive-care example, a “nutrition score” looked highly predictive of mortality until investigators clarified that people near death were often coded as zero because no assessment was completed. So the recorded variable combined nutrition with prognosis, and naive selection would overstate its scientific meaning (Dobson and Barnett 2018, sec. 6.3.3).
Mean squared error
We might want to minimize the mean squared error, \(\text{E}{\left[(y-\hat y)^2\right]}\), for new observations that weren’t in our data set when we fit the model.
Unfortunately, \[\frac{1}{n}\sum_{i=1}^n (y_i-\hat y_i)^2\] gives a biased estimate of \(\text{E}{\left[(y-\hat y)^2\right]}\) for new data. If we want an unbiased estimate, we will have to be clever.
This is one reason that \(R^2\) is not enough for model selection. \(R^2\) does not decrease as we add explanatory variables, even when those variables do not improve out-of-sample prediction. That can lead to overfitting.
With a training/test split, we estimate coefficients in the training data and compute prediction error in held-out data:
In many applications, we split the data into training, validation, and test sets. This extends the basic train/test split by separating model tuning from final model assessment. This framework follows (James et al. 2021, 198–201).
Use the training set to estimate model parameters.
Use the validation set to compare candidate models, choose transformations, or tune hyperparameters.
Use the test set once at the end to estimate final out-of-sample performance.
Keeping the test set untouched during model building helps avoid optimistic bias from repeatedly trying many models. If data are limited, \(k\)-fold cross-validation can replace a single validation split for more stable tuning.
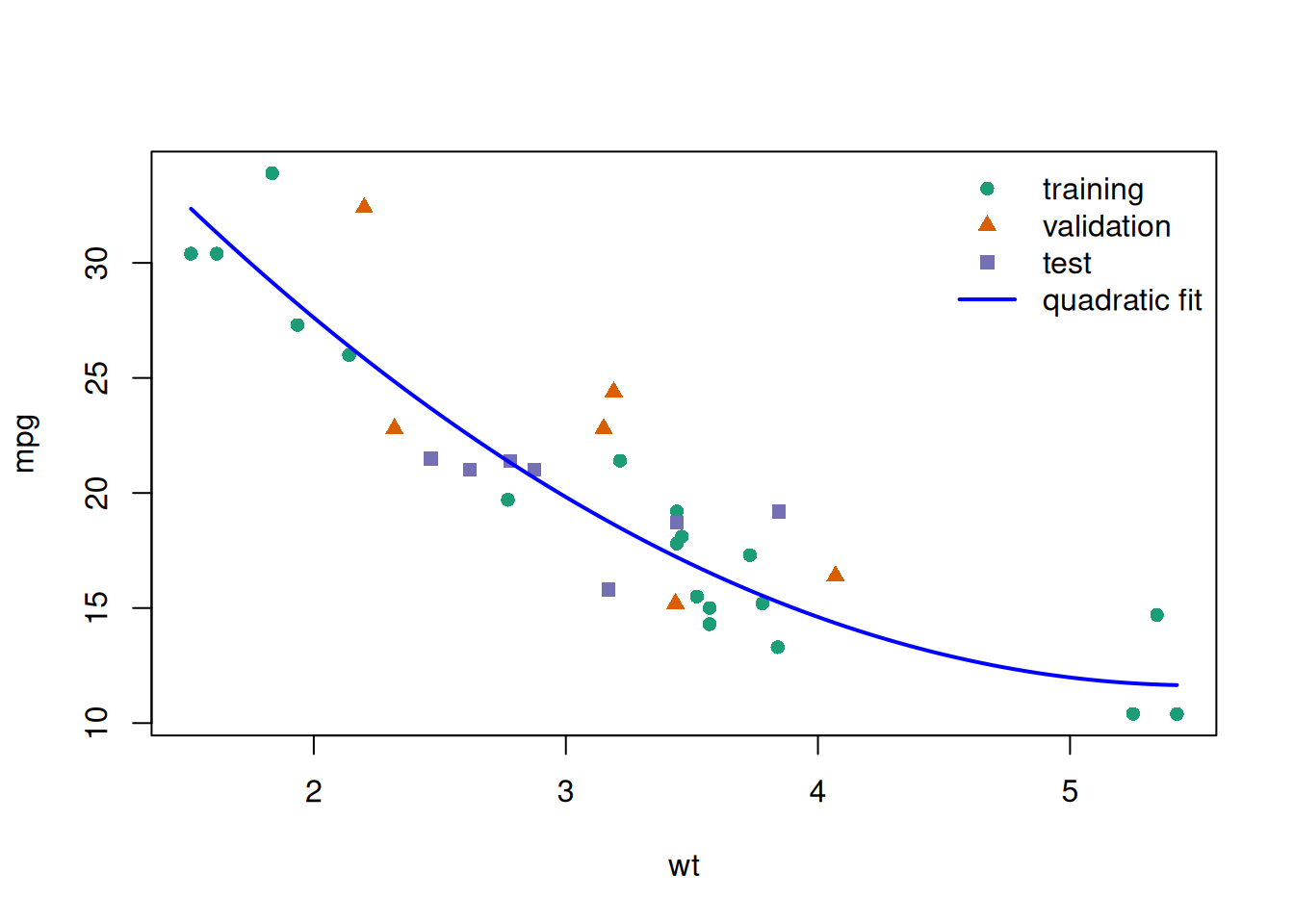
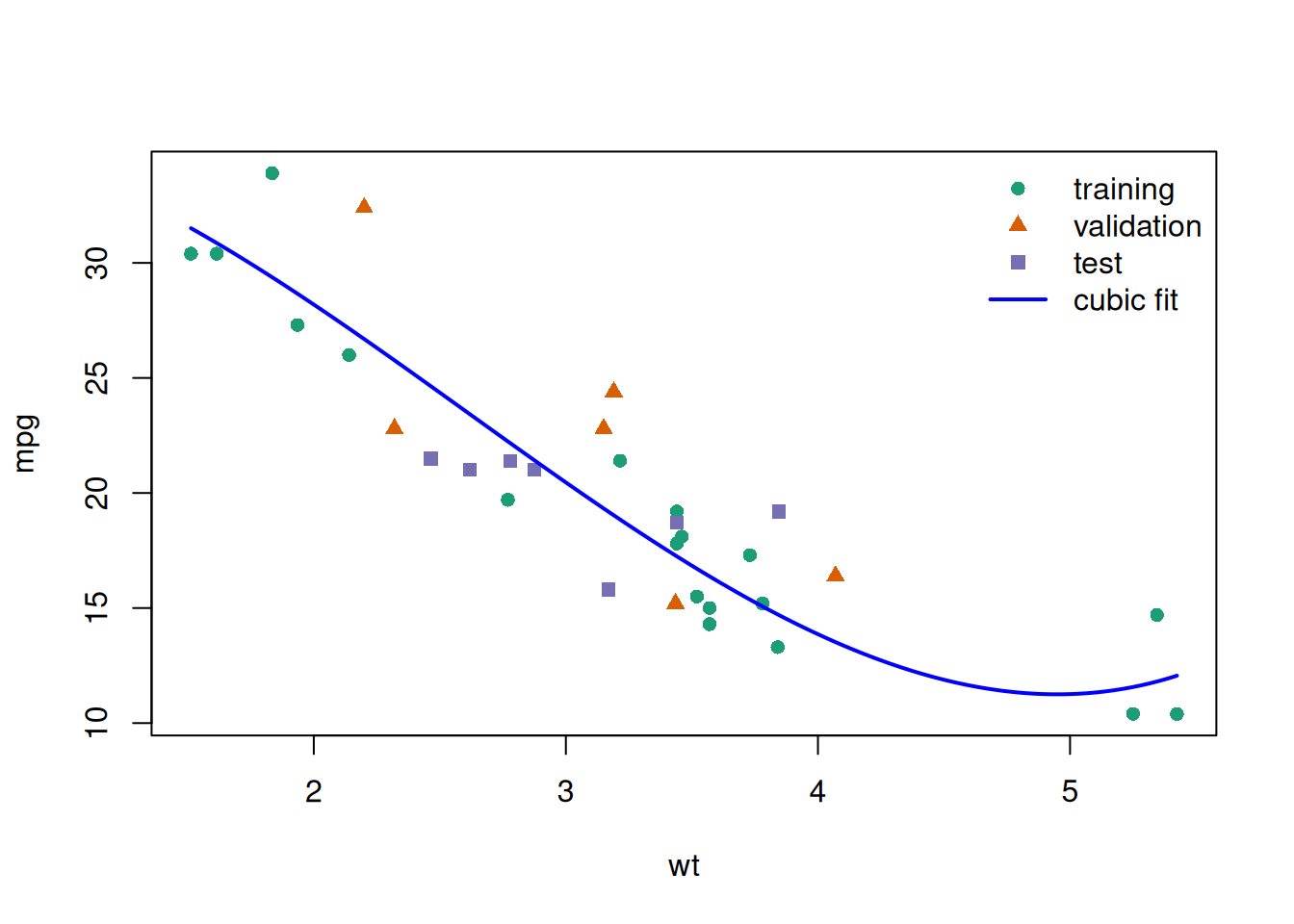
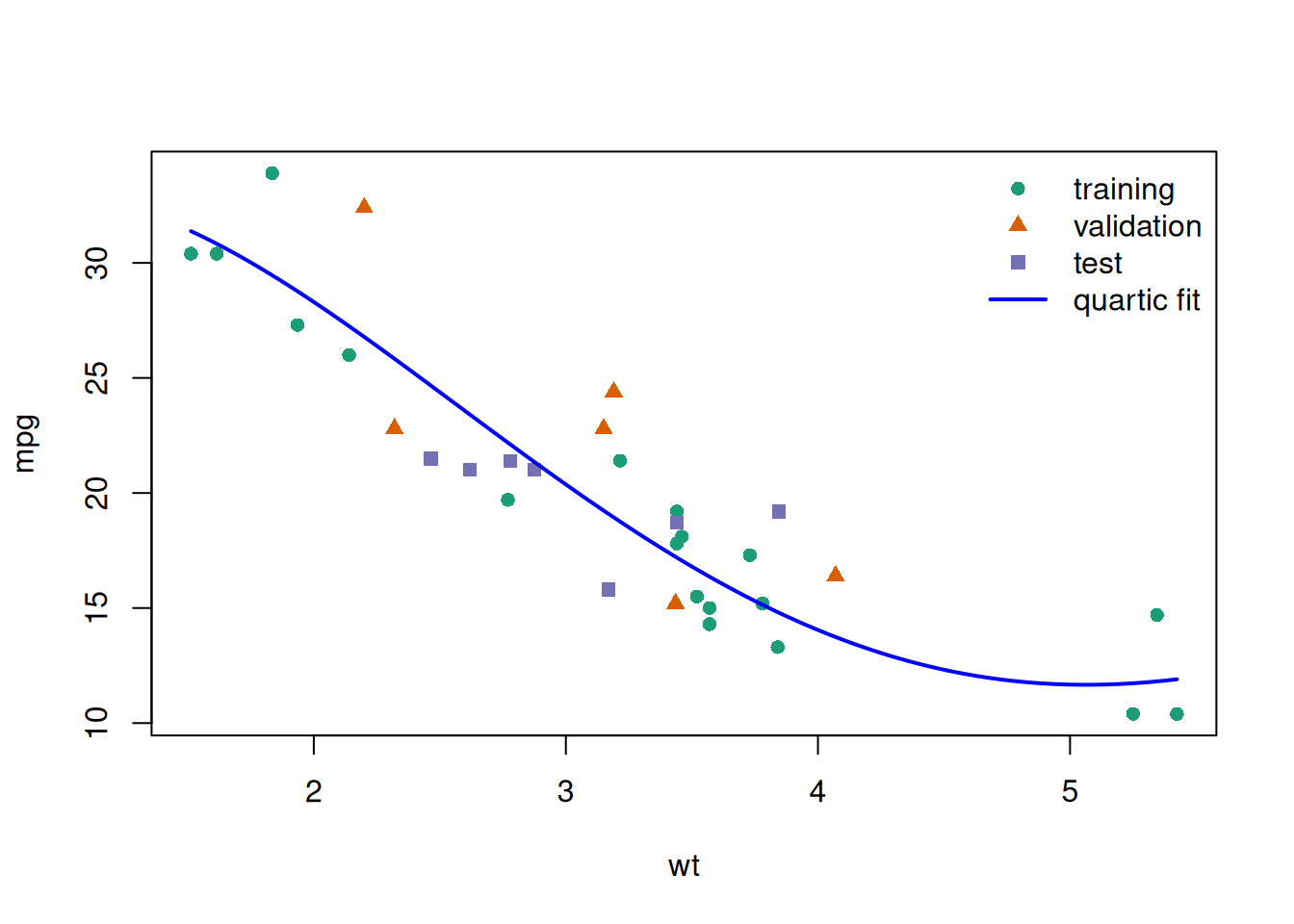
Example 8 (Numerical example) The example below uses R’s built-in mtcars dataset (\(n=32\) cars) to predict fuel efficiency (mpg) from vehicle weight (wt). It uses one random split to compare linear, quadratic, cubic, and quartic models (mpg ~ wt, mpg ~ wt + I(wt^2), mpg ~ wt + I(wt^2) + I(wt^3), and mpg ~ wt + I(wt^2) + I(wt^3) + I(wt^4)) on a validation set, then reports the chosen model’s test RMSE on untouched test data (James et al. 2021, 213).
Figure 42: Quartic model fit superimposed on data partitions
[R code]
validation_results
Table 24: Training and validation RMSE for candidate models
The chosen model is the linear model, because it has the lower validation RMSE.
[R code]
performance_comparison
Table 25: Validation and test RMSE for the chosen model
Cross-validation
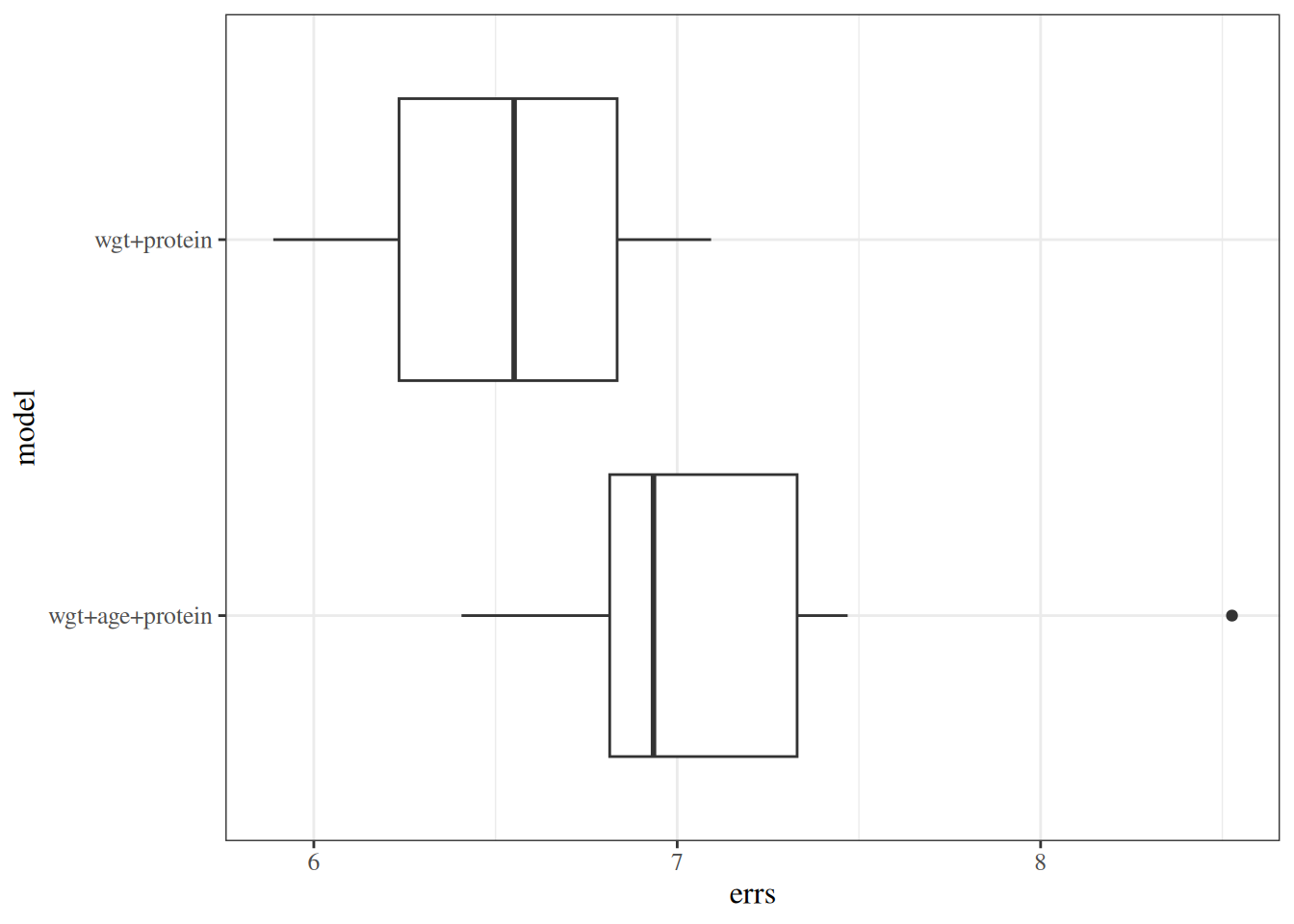
Rather than one arbitrary split, \(k\)-fold cross-validation repeatedly partitions the data into training and test folds. For each split we compute prediction error, then summarize errors across folds and replications. The preferred model has lower prediction error, with simpler models favored when errors are similar.
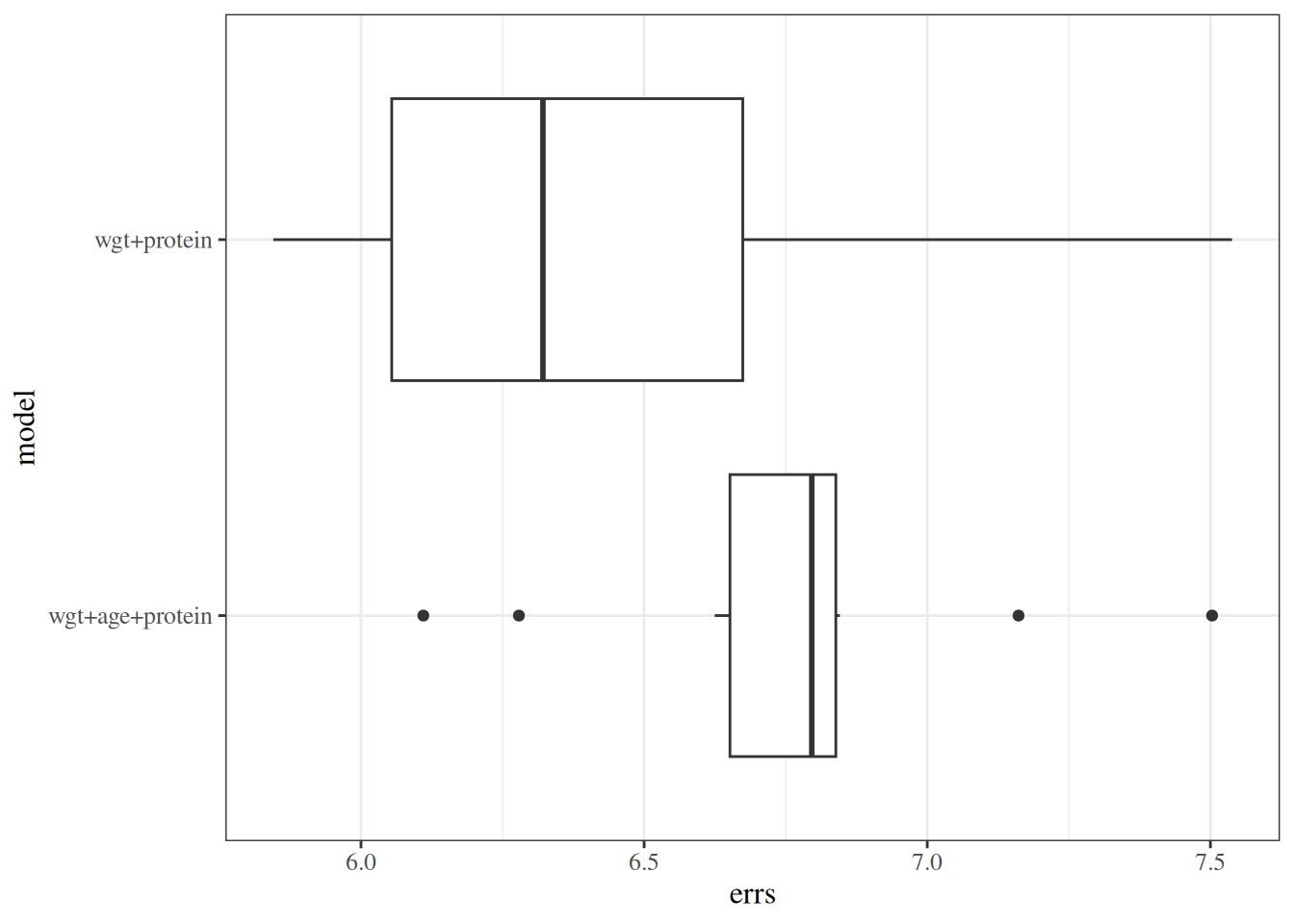
When the number of candidate explanatory variables is small, we can compare all possible subsets (\(2^p\) models) using the same cross-validation metric.
[R code]
data("carbohydrate", package ="dobson")library(cvTools)full_model <-lm(carbohydrate ~ ., data = carbohydrate)cv_full <- full_model |>cvFit(data = carbohydrate, K =5, R =10,y = carbohydrate$carbohydrate )reduced_model <- full_model |>update(formula =~ . - age)cv_reduced <- reduced_model |>cvFit(data = carbohydrate, K =5, R =10,y = carbohydrate$carbohydrate )
When the number of candidate predictors is modest, we can use best subset selection. For each model size \(k = 0, 1, \ldots, p\), we fit all \(\binom{p}{k}\) models and keep the best model of size \(k\) (e.g., by lowest RSS in the training data).
This gives at most \(p+1\) candidate models to compare across model sizes, using criteria such as cross-validated prediction error, \(C_p\), AIC/BIC, or adjusted \(R^2\). In that sense, best subset selection is more exhaustive than one-path methods like forward or backward stepwise selection.
Stepwise methods are another common approach. Forward selection adds variables one at a time. Backward selection starts with the full model and removes variables sequentially. Both approaches can select different models from the same data.
Caution about stepwise selection
Stepwise regression has several known problems:
It tends to select too many variables (overfitting)
P-values and confidence intervals are biased after selection
It ignores model uncertainty
Results can be unstable across different samples
Consider using cross-validation, penalized methods (like Lasso), or subject-matter knowledge instead. See Harrell (2015) and Heinze et al. (2018) for more discussion.
[R code]
library(olsrr)olsrr:::ols_step_both_aic(full_model)#> #> #> Stepwise Summary #> -------------------------------------------------------------------------#> Step Variable AIC SBC SBIC R2 Adj. R2 #> -------------------------------------------------------------------------#> 0 Base Model 140.773 142.764 83.068 0.00000 0.00000 #> 1 protein (+) 137.950 140.937 80.438 0.21427 0.17061 #> 2 weight (+) 132.981 136.964 77.191 0.44544 0.38020 #> -------------------------------------------------------------------------#> #> Final Model Output #> ------------------#> #> Model Summary #> ---------------------------------------------------------------#> R 0.667 RMSE 5.505 #> R-Squared 0.445 MSE 30.301 #> Adj. R-Squared 0.380 Coef. Var 15.879 #> Pred R-Squared 0.236 AIC 132.981 #> MAE 4.593 SBC 136.964 #> ---------------------------------------------------------------#> RMSE: Root Mean Square Error #> MSE: Mean Square Error #> MAE: Mean Absolute Error #> AIC: Akaike Information Criteria #> SBC: Schwarz Bayesian Criteria #> #> ANOVA #> -------------------------------------------------------------------#> Sum of #> Squares DF Mean Square F Sig. #> -------------------------------------------------------------------#> Regression 486.778 2 243.389 6.827 0.0067 #> Residual 606.022 17 35.648 #> Total 1092.800 19 #> -------------------------------------------------------------------#> #> Parameter Estimates #> ----------------------------------------------------------------------------------------#> model Beta Std. Error Std. Beta t Sig lower upper #> ----------------------------------------------------------------------------------------#> (Intercept) 33.130 12.572 2.635 0.017 6.607 59.654 #> protein 1.824 0.623 0.534 2.927 0.009 0.509 3.139 #> weight -0.222 0.083 -0.486 -2.662 0.016 -0.397 -0.046 #> ----------------------------------------------------------------------------------------
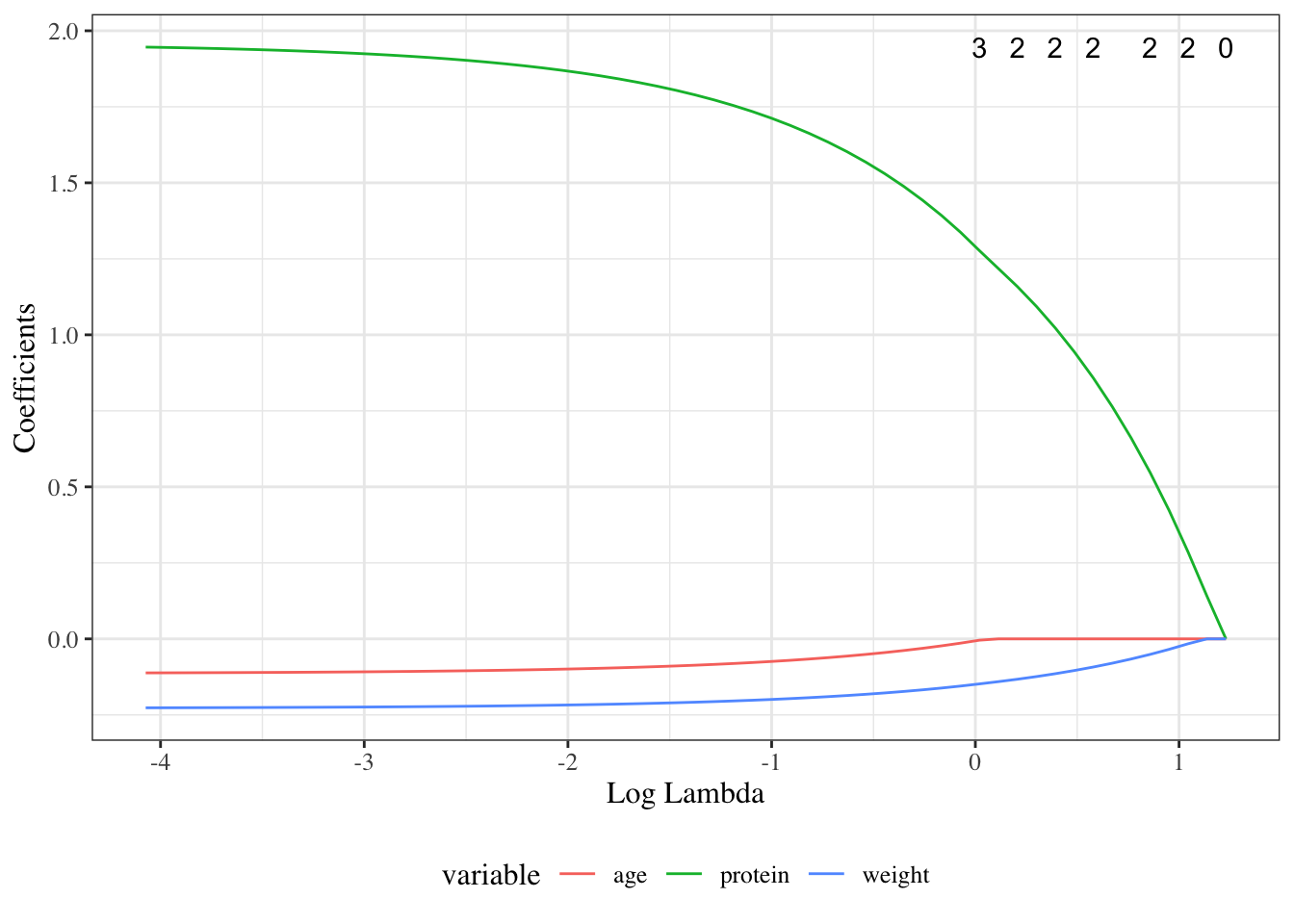
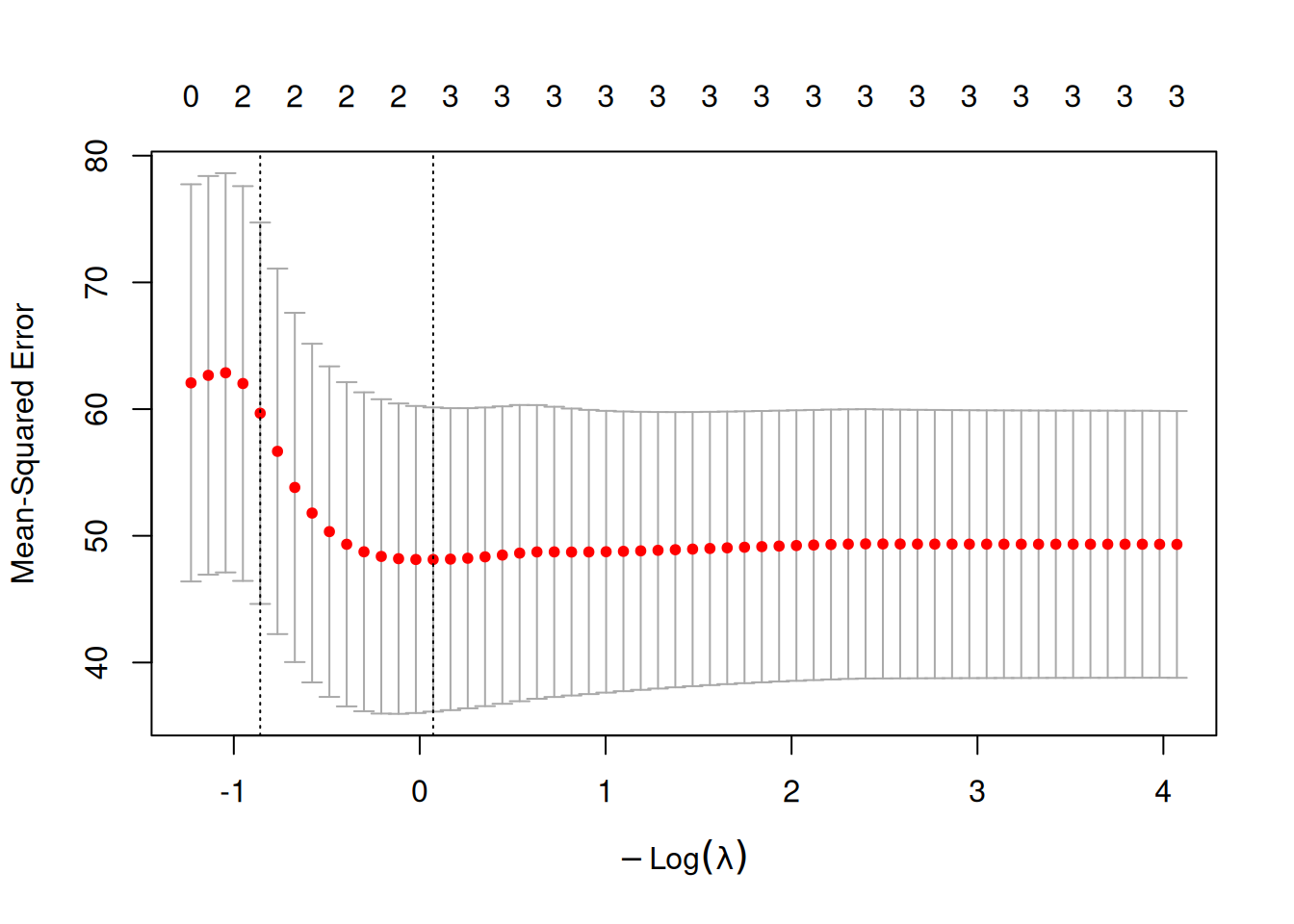
Lasso
Lasso is a penalized regression method that shrinks coefficient estimates toward zero. It adds an \(L_1\) penalty term to the objective function, creating a trade-off between model fit and parsimony. The intercept is not penalized.
As the tuning parameter \(\lambda\) increases, more coefficients are shrunken strongly, and some become exactly zero. So lasso both regularizes the model and performs variable selection. In practice, \(\lambda\) is usually chosen by cross-validation to minimize prediction error.
For Gaussian linear models, the penalized least-squares forms are:
coef(cvfit, s ="lambda.1se")#> 4 x 1 sparse Matrix of class "dgCMatrix"#> lambda.1se#> (Intercept) 34.5502388#> age . #> weight -0.0510494#> protein 0.5472281
The reduced model (Equation 16) has \(p_1\) parameters. The full model (Equation 17) adds \(q\) extra predictors and has \(p_2 = p_1 + q\) parameters. The reduced model is a special case of the full model with the constraint \(\tilde{\gamma} = \tilde{0}\).
\(H_0: \beta_{AM} = 0\) vs. \(H_A: \beta_{AM} \neq 0\).
F-statistic
Definition 16 (Partial F-statistic) Let \(\text{RSS}_0\) and \(\text{RSS}_1\) denote the residual sums of squares from the reduced and full models, respectively. The partial F-statistic is:
\(\text{RSS}_0 = \sum_{i=1}^n(y_i - \hat{y}_i^{(0)})^2\) is the residual SS under \(H_0\)
\(\text{RSS}_1 = \sum_{i=1}^n(y_i - \hat{y}_i^{(1)})^2\) is the residual SS under \(H_A\)
\(q = p_2 - p_1\) is the number of constraints (extra parameters in the full model)
\(n - p_2\) is the residual degrees of freedom of the full model
Theorem 4 (Null distribution of the partial F-statistic) Under \(H_0\) and the Gaussian linear regression assumptions,
\[
F \ \sim \ F_{q,\; n - p_2}
\tag{19}\]
This is an exact result (not an asymptotic approximation): it holds for any sample size \(n\) when the errors \(\epsilon_i \ \sim_{\text{iid}}\ N(0, \sigma^2)\).
Proof. Under \(H_0\), the extra predictors \(\tilde{z}\) contribute nothing, so the numerator \(\text{RSS}_0 - \text{RSS}_1 \ \sim \ \sigma^2 \chi^2_q\) and the denominator \(\text{RSS}_1 \ \sim \ \sigma^2 \chi^2_{n-p_2}\) are independent chi-squared random variables (this follows from the Gauss-Markov theorem and the properties of projections in the column spaces of the design matrices). Therefore,
From Section 4.1.8, the Gaussian deviance of model \(k\) is \(D_k = \text{RSS}_k / \hat\sigma^2\), where \(\hat\sigma^2\) is an estimate of \(\sigma^2\). Because \(\hat\sigma^2\) appears in both the numerator and denominator of Equation 18, it cancels:
For Gaussian linear regression, the MLE of \(\sigma^2\) under model \(k\) is \(\hat\sigma^2_k = \text{RSS}_k / n\), so the log-likelihood at the MLE is:
So \(\lambda \approx q \cdot F\) for large \(n\), and both statistics have the same asymptotic null distribution \(\chi^2_q\) (since \(q \cdot F_{q, n-p_2} \dot \sim \chi^2_q\) as \(n \to \infty\)).
Why use the F-test instead of the LRT?
For Gaussian linear regression:
The F-test is exact — it has the correct \(F_{q,n-p_2}\) null distribution for any sample size \(n\), provided the errors are Gaussian. It accounts for the estimation of \(\sigma^2\) via the residual degrees of freedom.
The LRT is approximate — it relies on the asymptotic \(\chi^2_q\) distribution, which requires large \(n\) and treats \(\sigma^2\) as known (fixed at its MLE).
Both tests give similar p-values for large \(n\). For small to moderate \(n\), the F-test is preferred because it is exact.
For non-Gaussian GLMs (Poisson, Binomial), the F-test is not applicable; the LRT (or Wald test) is the standard approach.
In R
In R, the partial F-test for two nested lm models is performed with anova():
anova(bw_lm1, bw_lm2)
Table 26
For comparison, the approximate likelihood ratio test using the lmtest package:
lmtest::lrtest(bw_lm1, bw_lm2)
Table 27
Extracting F-test components by hand
To understand the computation, we can replicate the F-statistic manually:
Table 28
rss0 <-deviance(bw_lm1) # RSS of reduced modelrss1 <-deviance(bw_lm2) # RSS of full modeln <-nobs(bw_lm2)p2 <-length(coef(bw_lm2))q <-length(coef(bw_lm2)) -length(coef(bw_lm1))s2 <- rss1 / (n - p2) # residual variance estimate from full modelF_stat <- ((rss0 - rss1) / q) / s2p_val <-pf(F_stat, df1 = q, df2 = n - p2, lower.tail =FALSE)cat("RSS_0 =", rss0, "\n")#> RSS_0 = 658771cat("RSS_1 =", rss1, "\n")#> RSS_1 = 652425cat("q =", q, "\n")#> q = 1cat("s^2 =", s2, "\n")#> s^2 = 32621.2cat("F =", F_stat, "\n")#> F = 0.194543cat("p-val =", p_val, "\n")#> p-val = 0.663893
The covariance matrix \(\widehat{\text{Cov}}(\hat{\tilde{\beta}})\) is a \(p \times p\) symmetric matrix, where \(p\) is the number of regression coefficients (including the intercept, if present). Its rows and columns correspond to those \(p\) coefficient estimates. When an intercept is included, the coefficients are typically written \(\hat\beta_0, \hat\beta_1, \ldots\), with \(\hat\beta_0\) denoting the intercept. The matrix entries themselves are still indexed by position, so matrix row/column index \(1\) corresponds to the intercept term when one is included.
The diagonal entries are the variances of the individual coefficient estimates: the entry in matrix position \((j+1, j+1)\) is \(\text{Var}{\left(\hat\beta_j\right)}\), for \(j = 0, 1, \ldots, p - 1\).
The off-diagonal entries are the covariances between pairs of coefficient estimates: the entry in matrix position \((i+1, j+1)\) is \(\text{Cov}{\left(\hat\beta_i, \hat\beta_j\right)}\), for \(i \neq j\).
The matrix is symmetric: \(\text{Cov}{\left(\hat\beta_i, \hat\beta_j\right)} = \text{Cov}{\left(\hat\beta_j, \hat\beta_i\right)}\).
Example 10 For model 2, which has four coefficients \((\hat\beta_0, \hat\beta_M, \hat\beta_A, \hat\beta_{AM})\), the covariance matrix has the following layout:
Table 31: Estimated model for birthweight data with interaction term
Parameter
Coefficient
SE
95% CI
t(20)
p
(Intercept)
-2141.67
1163.60
(-4568.90, 285.56)
-1.84
0.081
sex (male)
872.99
1611.33
(-2488.18, 4234.17)
0.54
0.594
age
130.40
30.00
(67.82, 192.98)
4.35
< .001
sex (male) × age
-18.42
41.76
(-105.52, 68.68)
-0.44
0.664
Wald tests and confidence intervals
For Gaussian linear regression, the ordinary least squares (OLS) estimates \(\hat\beta_k\) are exactly Gaussian when the error terms \(\epsilon_i\) are Gaussian, for any sample size. See also the table of Gaussian vs. MLE-based tests.
Wald test statistic
To test \(H_0: \beta_k = \beta_{k,0}\) (typically \(\beta_{k,0} = 0\)):
Exercise 16 Given a maximum likelihood estimate \(\hat{\tilde{\beta}}\) and a corresponding estimated covariance matrix \(\hat \Sigma\stackrel{\text{def}}{=}\widehat{\text{Cov}}(\hat{\tilde{\beta}})\), calculate a 95% confidence interval for the predicted mean \(\mu(\tilde{x}) = \text{E}{\left[Y|\tilde{X}=\tilde{x}\right]}\).
Combining Equation 26 and the Gauss-Markov theorem:
Theorem 5 (Estimated variance and standard error of predicted mean)\[
{\color{orange}\widehat{\text{Var}}{\left(\hat\mu(\tilde{x})\right)}} = {\color{orange}{\tilde{x}}^{\top}\hat{\Sigma}\tilde{x}}
\tag{27}\]
In R, predict() with se.fit = TRUE computes the estimated mean \(\hat\mu(\tilde{x}) = \tilde{x}'\hat{\tilde{\beta}}\) and its estimated standard error for each covariate pattern:
Figure 45: Predicted values and confidence bands for the birthweight model with interaction term
Why are confidence bands narrower near the center of the data?
The confidence bands in Figure 45 are visibly narrower near the center of the gestational age range. To understand why, consider a simple linear regression with one predictor \(a\) (gestational age) and an intercept. The covariate vector for a new observation at age \(a\) is \(\tilde{x}= {(1, a)}^{\top}\), and the general variance formula for the predicted mean specializes to:
where \(\bar{a} = \frac{1}{n}\sum_{i=1}^na_i\) is the mean gestational age and \(S_{AA} = \sum_{i=1}^n(a_i - \bar{a})^2\) is the total variation in gestational age.
To derive Equation 29, first note that for \(n\) observations with design matrix rows \((1, a_i)\):
Since \((a - \bar{a})^2 \geq 0\) and equals zero when \(a = \bar{a}\), the standard error is minimized at the mean gestational age \(\bar{a}\) and increases as \(a\) moves away from \(\bar{a}\) in either direction. Consequently, confidence intervals are narrowest at \(\bar{a}\) and widen toward the extremes of the gestational age range.
Intuitively, the fitted line is “anchored” at the center of the data: in simple linear regression with an intercept, the OLS fitted line passes exactly through the sample mean point \((\bar{a}, \bar{y})\), so the estimated mean at \(\bar{a}\) is relatively stable across different samples. Moving away from \(\bar{a}\), small changes in the estimated slope cause the fitted line to “pivot” around that anchor, producing larger changes in the predicted mean the further \(a\) is from \(\bar{a}\).
Additionally, there is typically more nearby data near the center of the covariate range, so we have more information about the true mean response there. Near the edges of the covariate range, there is less nearby data, leaving us less confident in our estimate of the mean response at those values.
5.4 Inference for differences in means
Exercise 18 Given a maximum likelihood estimate \(\hat{\tilde{\beta}}\) and a corresponding estimated covariance matrix \(\hat \Sigma\stackrel{\text{def}}{=}\widehat{\text{Cov}}(\hat{\tilde{\beta}})\), calculate a 95% confidence interval for the difference in means comparing covariate patterns \(\tilde{x}\) and \({\tilde{x}^*}\):
Exercise 19 Express the difference in means \(\Delta \mu \stackrel{\text{def}}{=}\mu(\tilde{x}) - \mu({\tilde{x}^*})\) as a linear function of \(\tilde{\beta}\).
Combining Equation 33 and the Gauss-Markov theorem:
Theorem 6 (Estimated variance and standard error of difference in means)\[
{\color{orange}\widehat{\text{Var}}{\left(\widehat{\Delta \mu}\right)}} = {\color{orange}{\Delta\tilde{x}}^{\top}\hat{\Sigma}(\Delta\tilde{x})}
\tag{34}\]
In R, we can compute the CI for the difference in means by computing the predicted means for both covariate patterns and applying the variance formula directly:
\(\text{Var}{\left(\varepsilon^*\right)} = \sigma^2\): the variance of the future observation’s own noise, which is irreducible.
\(\text{Var}{\left({\tilde{x}^*} \cdot \hat \beta\right)} = {({\tilde{x}^*})}^{\top}\text{Var}{\left(\hat \beta\right)}{\tilde{x}^*}\): the variance due to estimating the mean \({\tilde{x}^*} \cdot \tilde{\beta}\) from the data.
The first component is not present in the confidence interval for \(\hat\mu({\tilde{x}^*})\), which only accounts for estimation uncertainty. This is why prediction intervals are always wider than the corresponding confidence intervals: a prediction interval must additionally account for the irreducible noise \(\varepsilon^*\) in a new observation.
The standard error of the prediction error is the square root of its variance:
Since \(\varepsilon^* \sim \text{N}{\left(0, \sigma^2\right)}\) and \(\hat \beta\sim \text{N}{\left(\tilde{\beta}, \sigma^2(\mathbf{X}'\mathbf{X})^{-1}\right)}\) are both normally distributed, and since \(\varepsilon^* \perp\!\!\!\perp\hat \beta\) (as noted above in the variance derivation), their difference \(Y^* - \hat{Y}^* = \varepsilon^* - {({\tilde{x}^*})}^{\top}(\hat \beta- \tilde{\beta})\) is also normally distributed, with mean 0 (as shown above) and variance given by Equation 36. Standardizing by dividing by \(\sigma\sqrt{1 + {({\tilde{x}^*})}^{\top}(\mathbf{X}'\mathbf{X})^{-1}{\tilde{x}^*}}\) yields a standard normal random variable. Replacing \(\sigma\) with \(\hat \sigma\), which is estimated with \(n-p\) degrees of freedom and is independent of \(Y^* - \hat{Y}^*\), the standardized prediction error follows a \(t\) distribution:
x <-tibble(age =40, sex ="male")bw_lm2 |>predict(newdata = x, interval ="predict")#> fit lwr upr#> 1 3210.64 2805.71 3615.57
If you don’t specify newdata, you get a warning:
[R code]
bw_lm2 |>predict(interval ="predict") |>head()#> Warning in predict.lm(bw_lm2, interval = "predict"): predictions on current data refer to _future_ responses#> fit lwr upr#> 1 2552.73 2124.50 2980.97#> 2 2552.73 2124.50 2980.97#> 3 2683.13 2275.99 3090.27#> 4 2813.53 2418.60 3208.47#> 5 2813.53 2418.60 3208.47#> 6 2943.93 2551.48 3336.38
The warning from the last command is: “predictions on current data refer to future responses” (since you already know what happened to the current data, and thus don’t need to predict it).
Dataset summary: The ToothGrowth dataset contains one row per guinea pig. Variable definitions: - \(Y\): tooth length (len) - \(X\): dose (dose) - \(Z\): supplement indicator (supp) with \(Z=1\) for VC and \(Z=0\) for OJ
Consider the additive model
\[
\text{E}{\left[Y|X=x,Z=z\right]}
= \beta_0 + \beta_X x + \beta_Z z.
\]
State the interpretation of \(\beta_0\), \(\beta_X\), and \(\beta_Z\). Which interpretations depend on the reference level OJ?
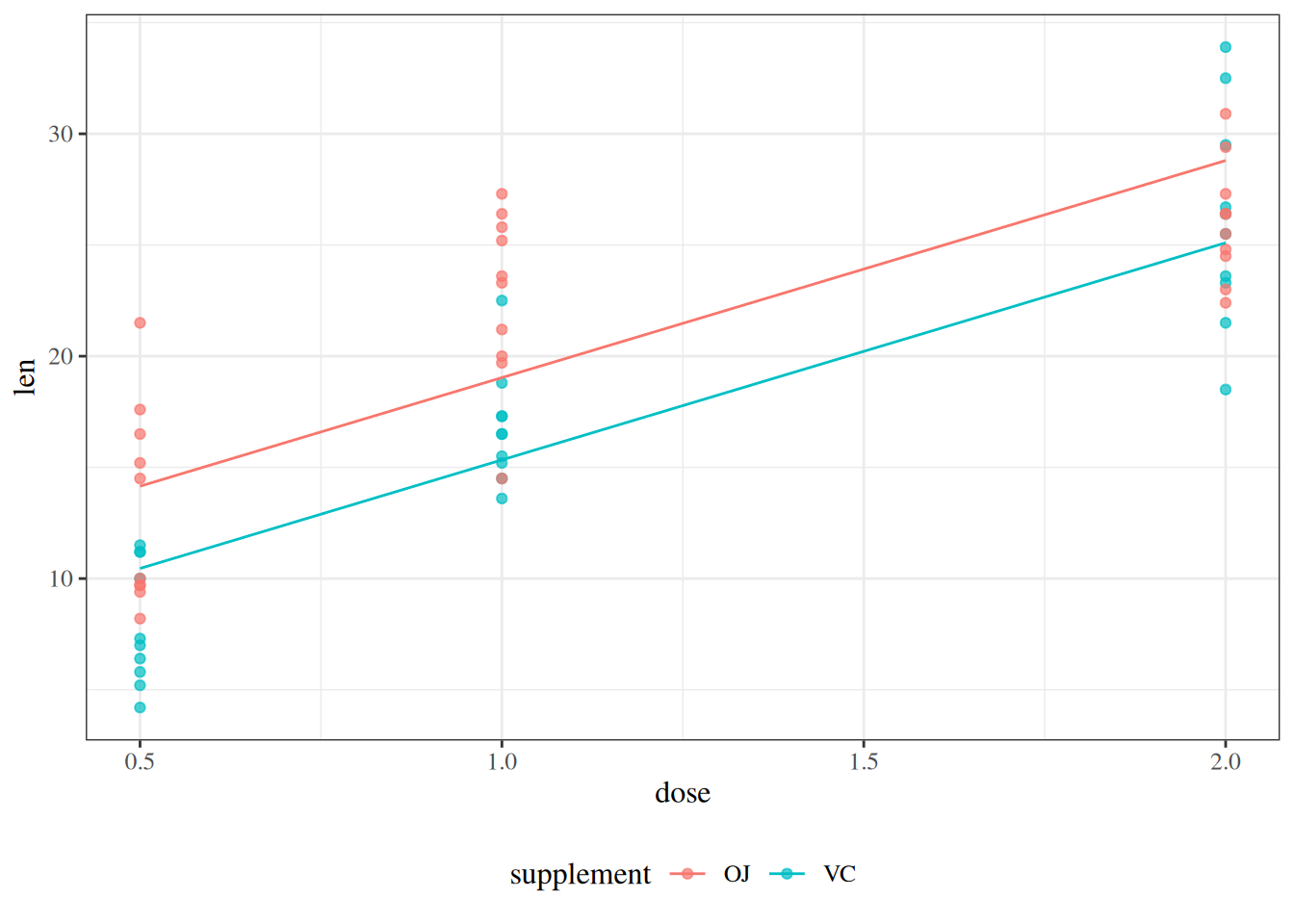
Figure 47: ToothGrowth data with additive (parallel-lines) fit
Solution.
\(\beta_0\) is the mean tooth length for guinea pigs given OJ at dose 0.
\(\beta_X\) is the change in mean tooth length for each one-unit increase in dose. In this additive model, that dose effect is the same for OJ and VC.
\(\beta_Z\) is the mean tooth-length difference between VC and OJ at the same dose. The interpretations that depend on OJ as the reference level are \(\beta_0\) and \(\beta_Z\).
Use ToothGrowth as introduced in Exercise 21. Variable definitions: - \(Y\): tooth length (len) - \(X\): dose (dose) - \(Z\): supplement indicator (supp) with \(Z=1\) for VC and \(Z=0\) for OJ
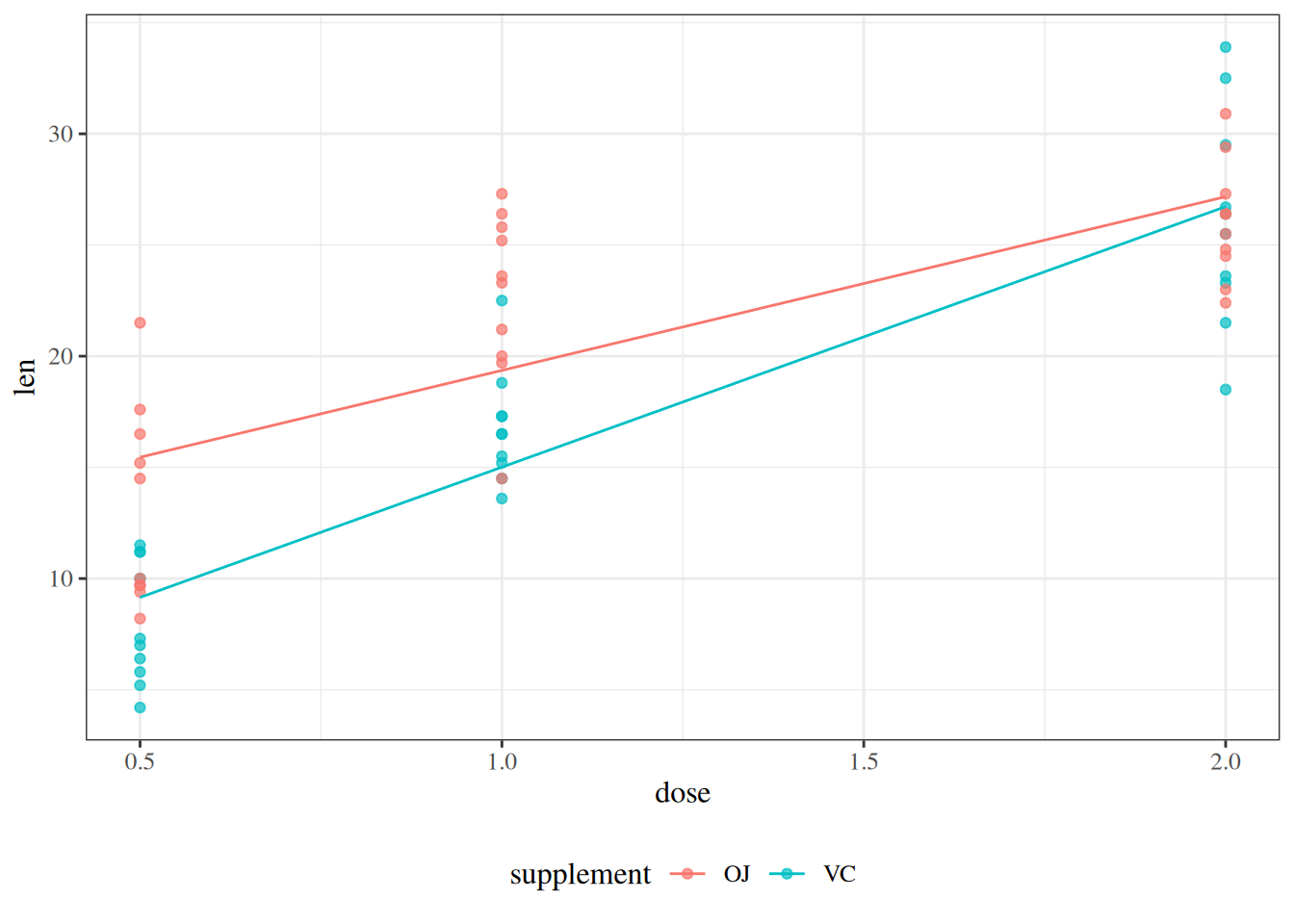
Consider the interaction model
\[
\text{E}{\left[Y|X=x,Z=z\right]}
= \beta_0 + \beta_X x + \beta_Z z + \beta_{XZ}(x\cdot z).
\]
Using the plot, write the slope with respect to \(X\) for OJ and for VC. Then interpret \(\beta_{XZ}\).
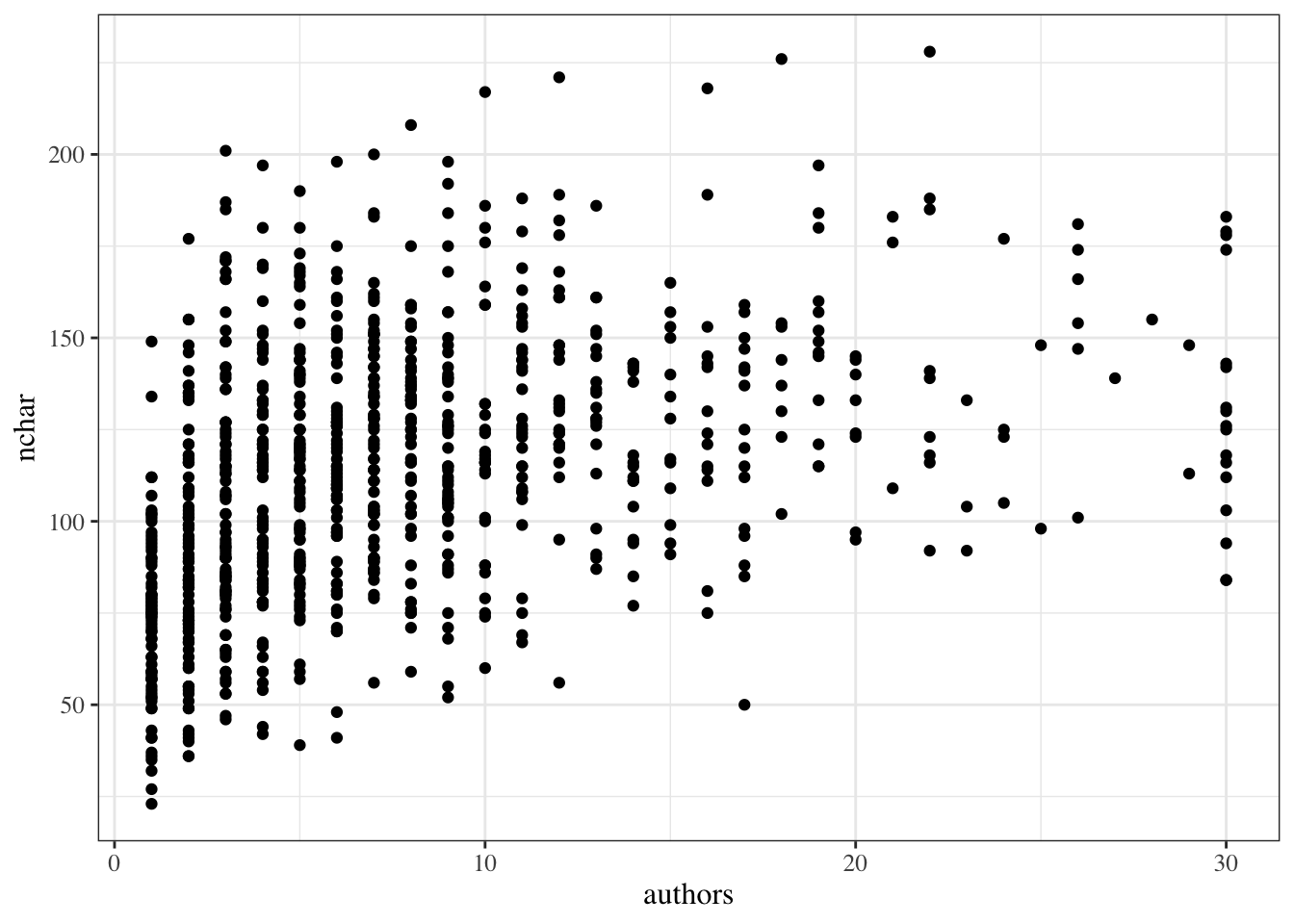
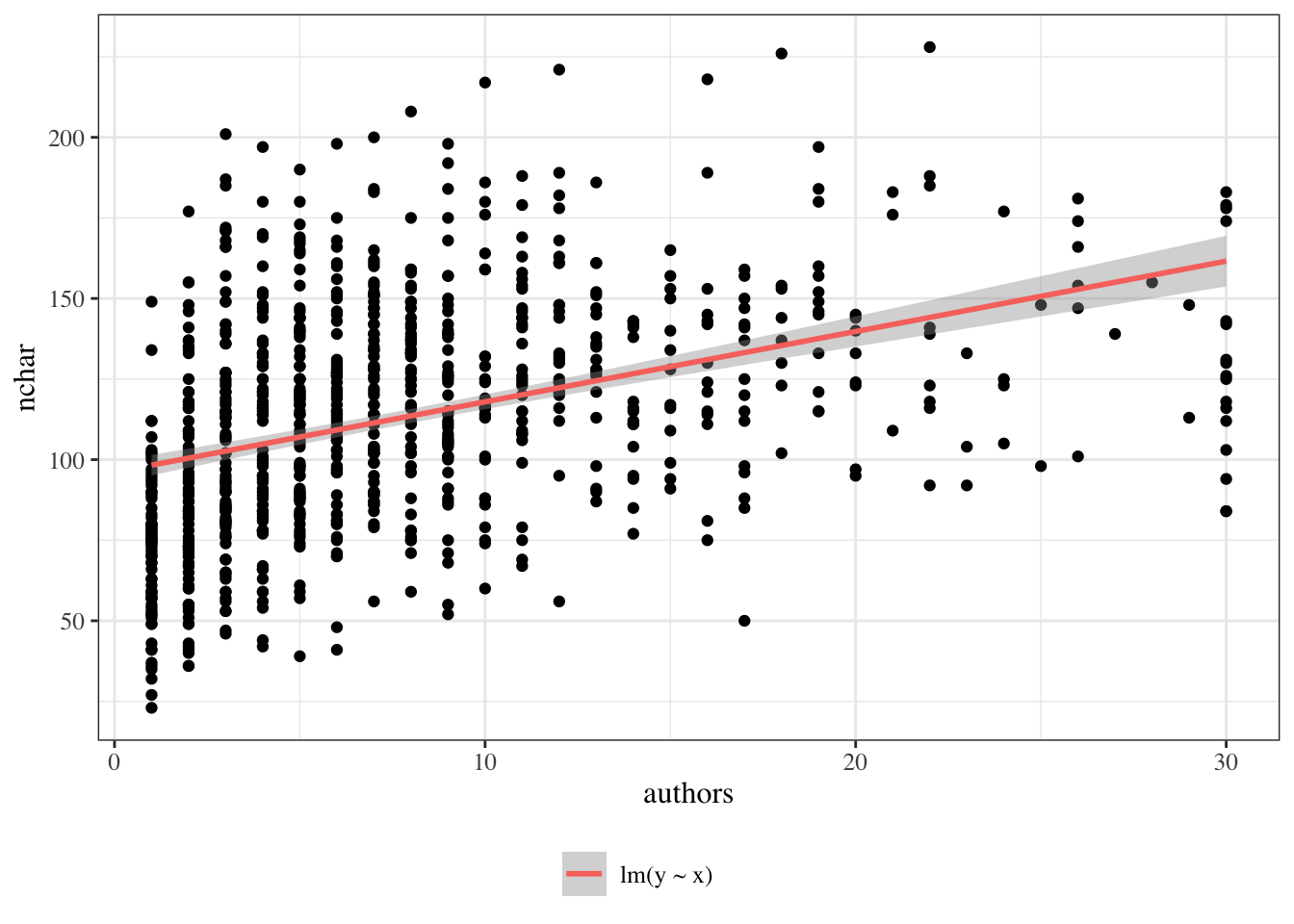
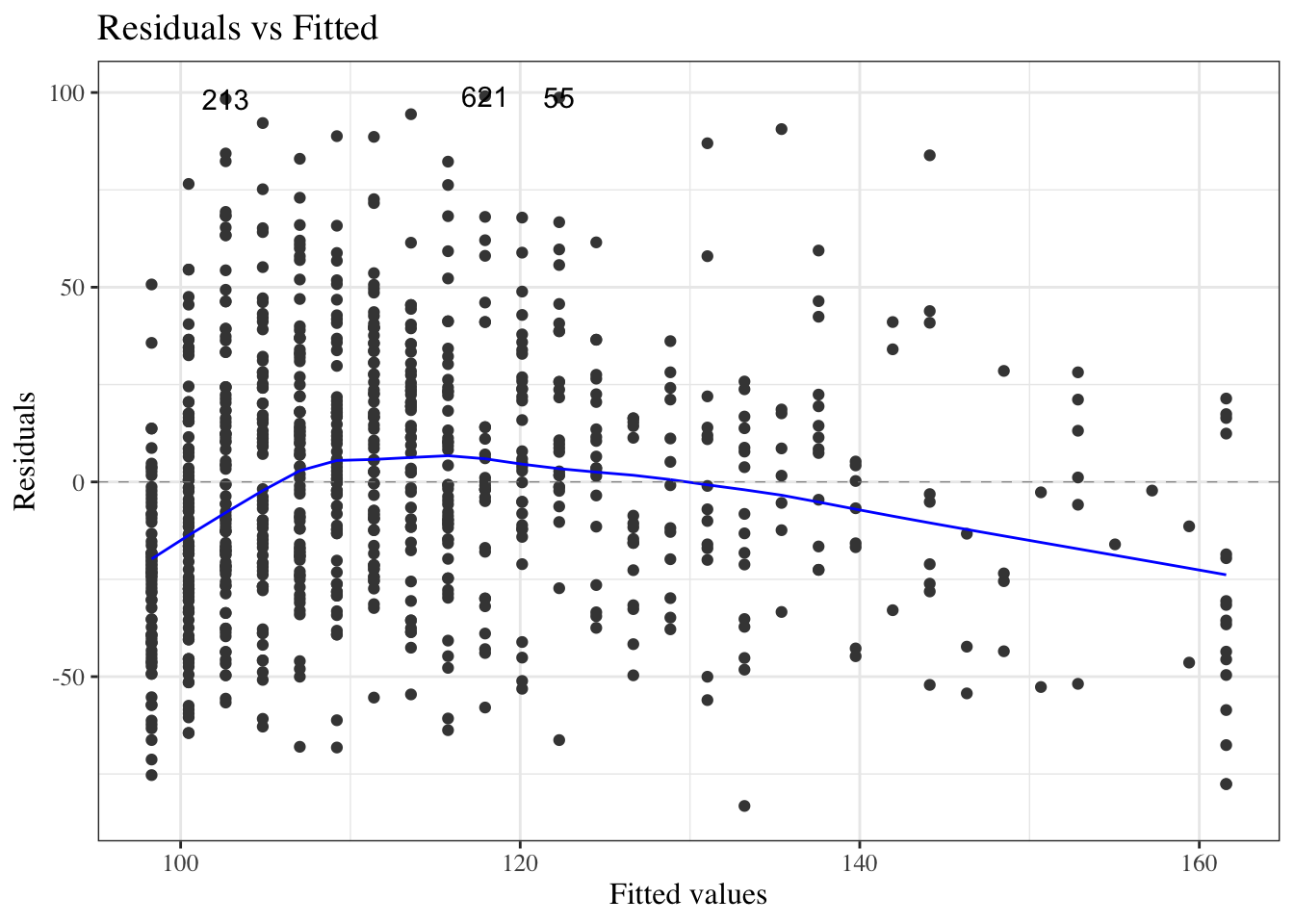
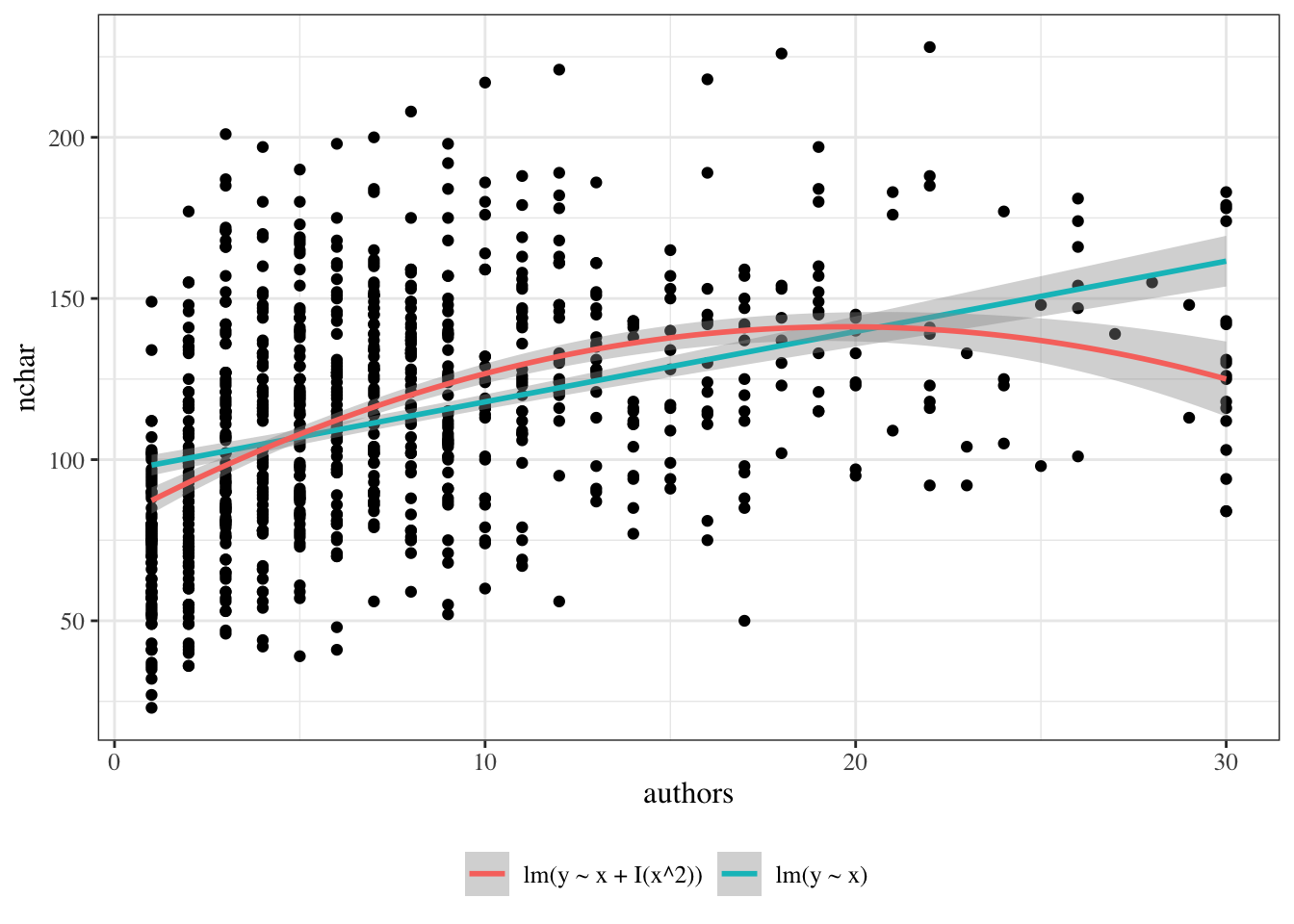
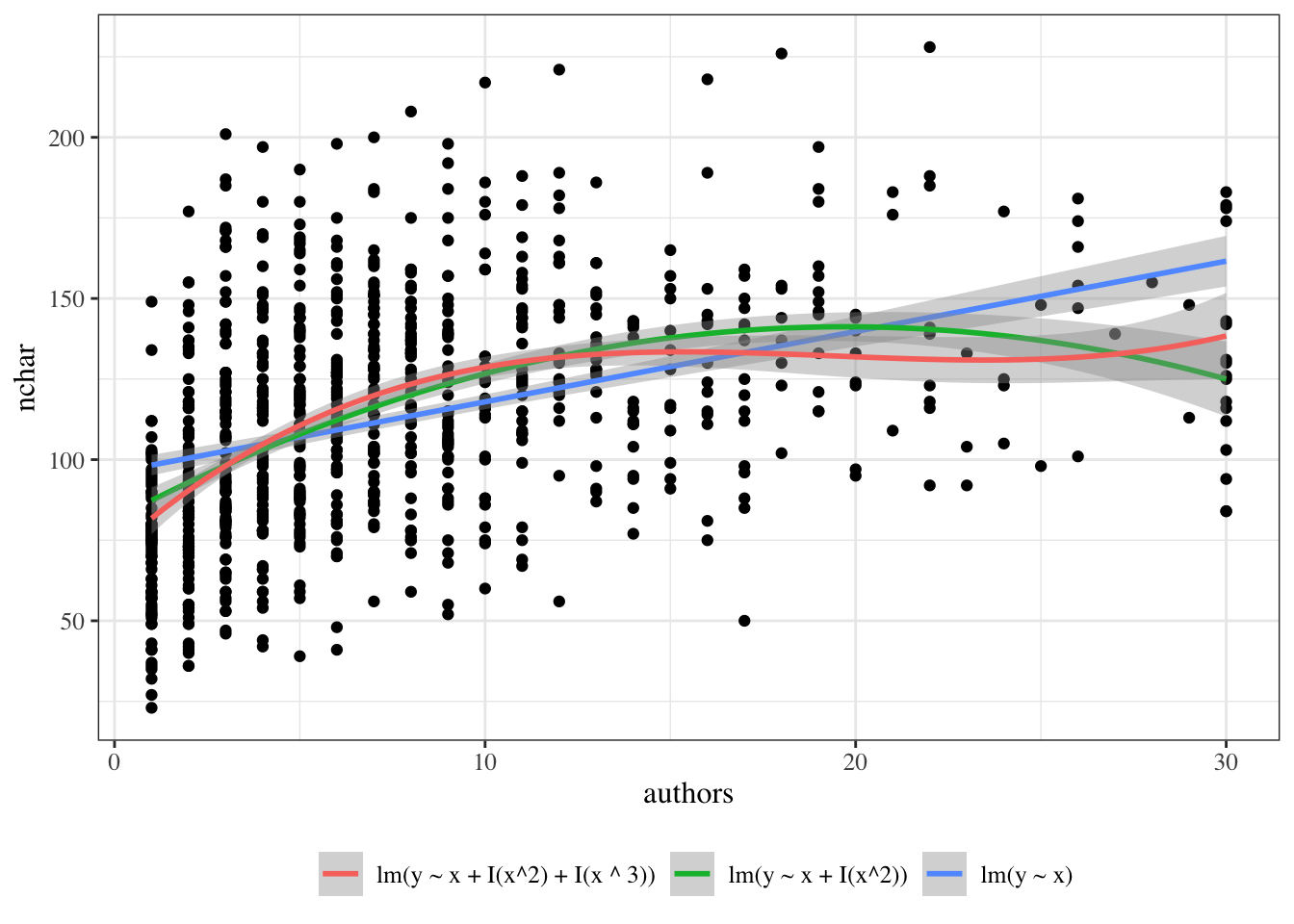
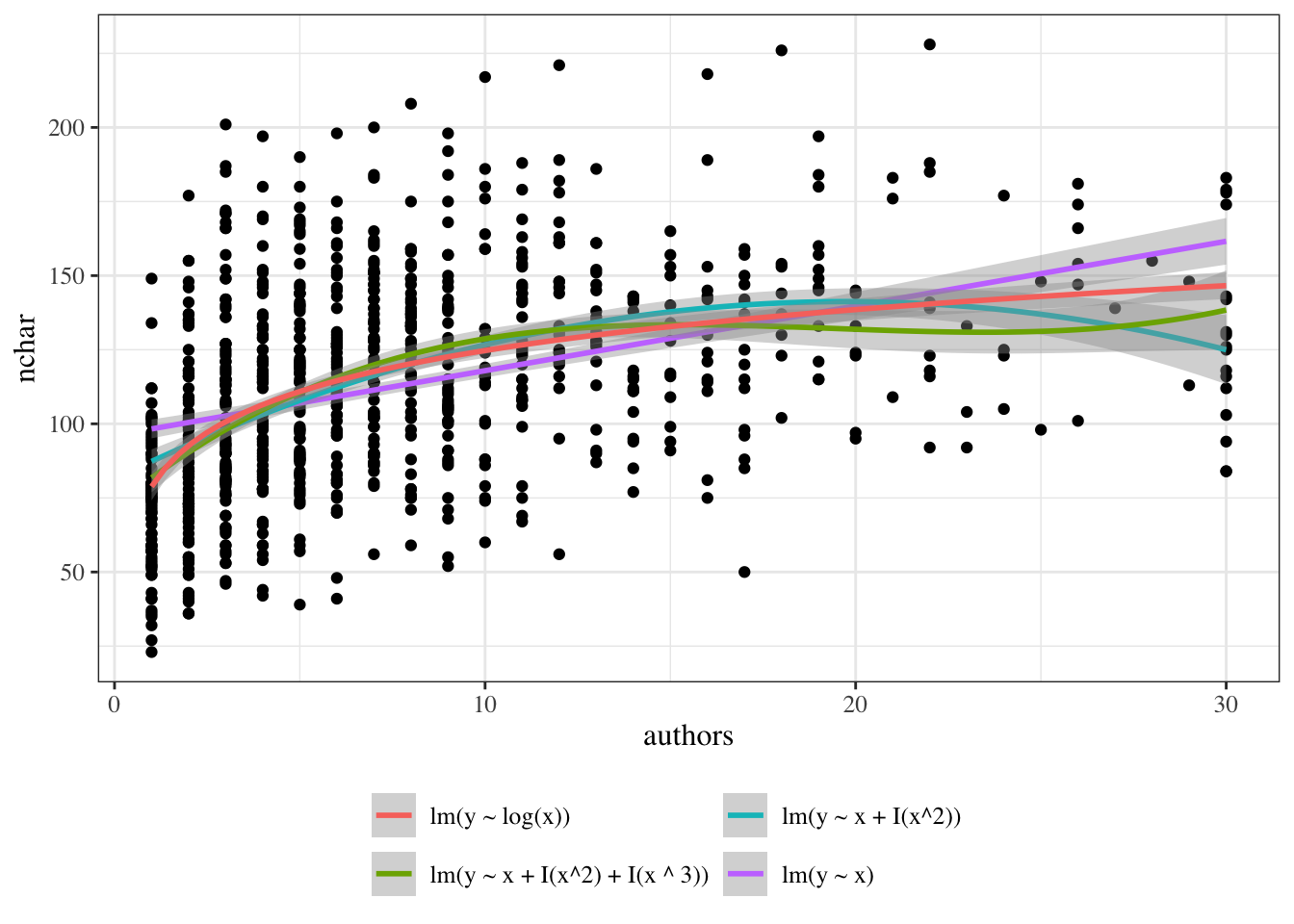
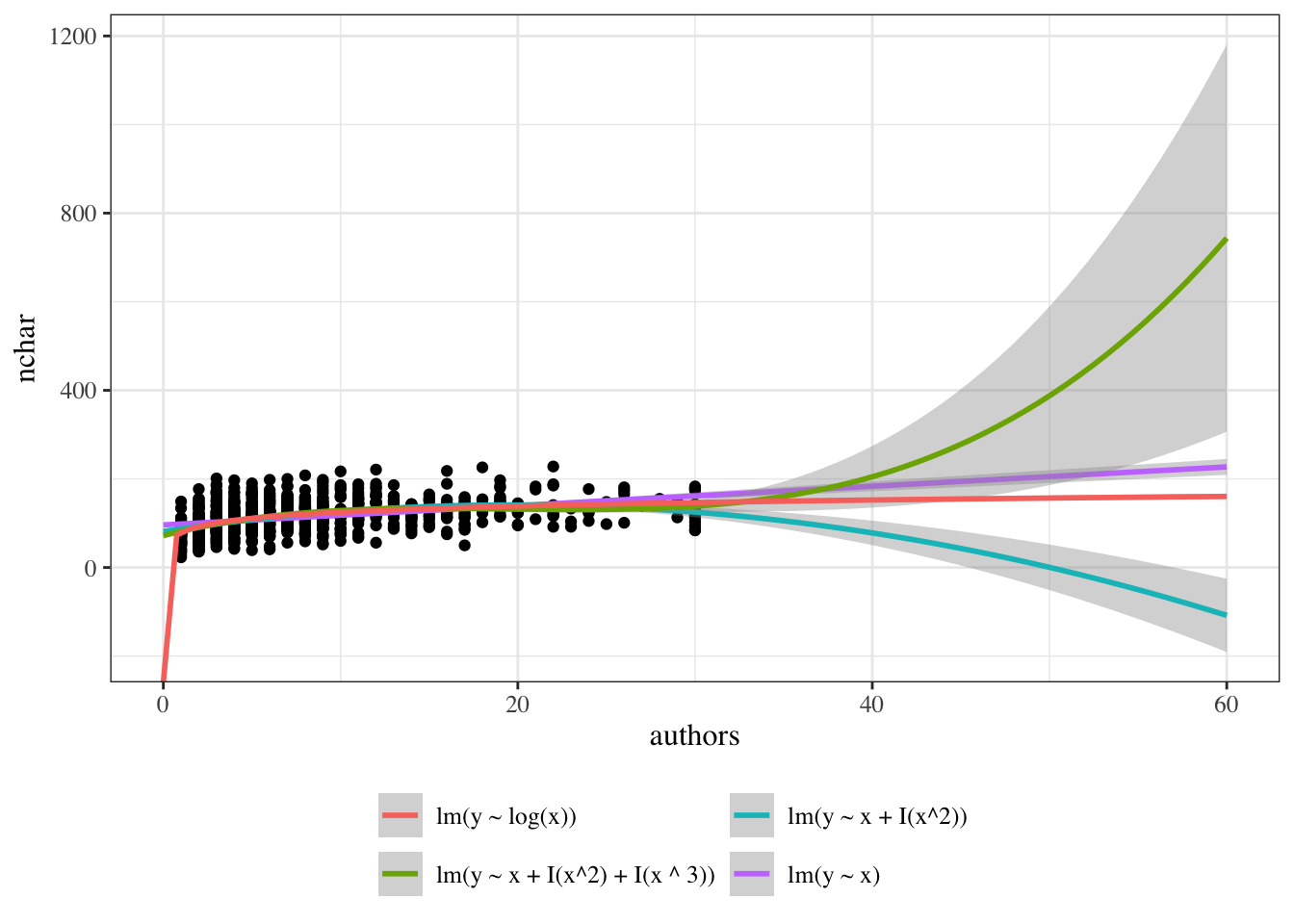
Dataset summary: The PLOS dataset contains one row per paper. Variable definitions: - \(Y\): title length (nchar) - \(X\): number of authors (authors) - \(X^*\): centered author count (authors_centered), constructed from authors, defined as \(X^* = X - 10\)
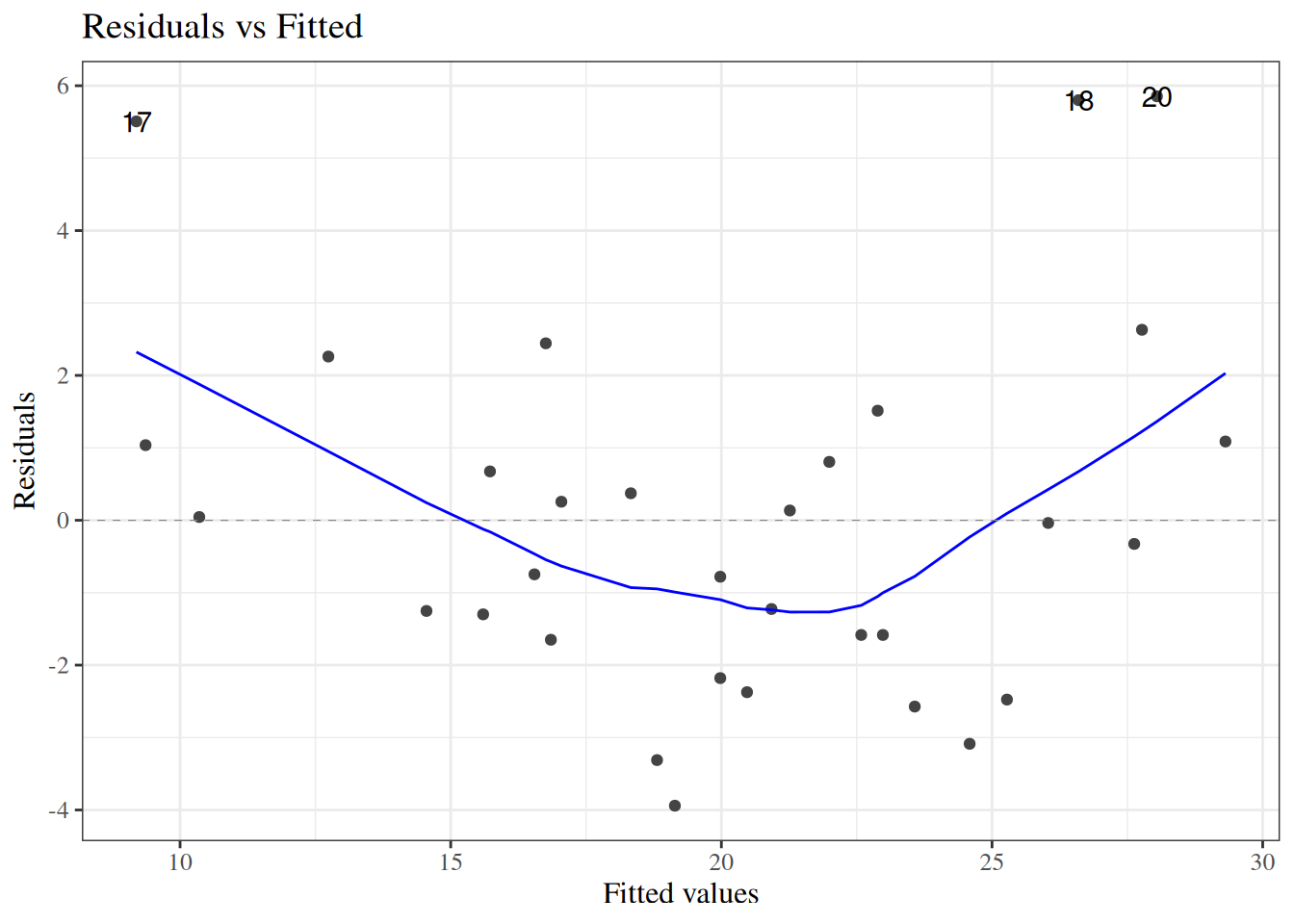
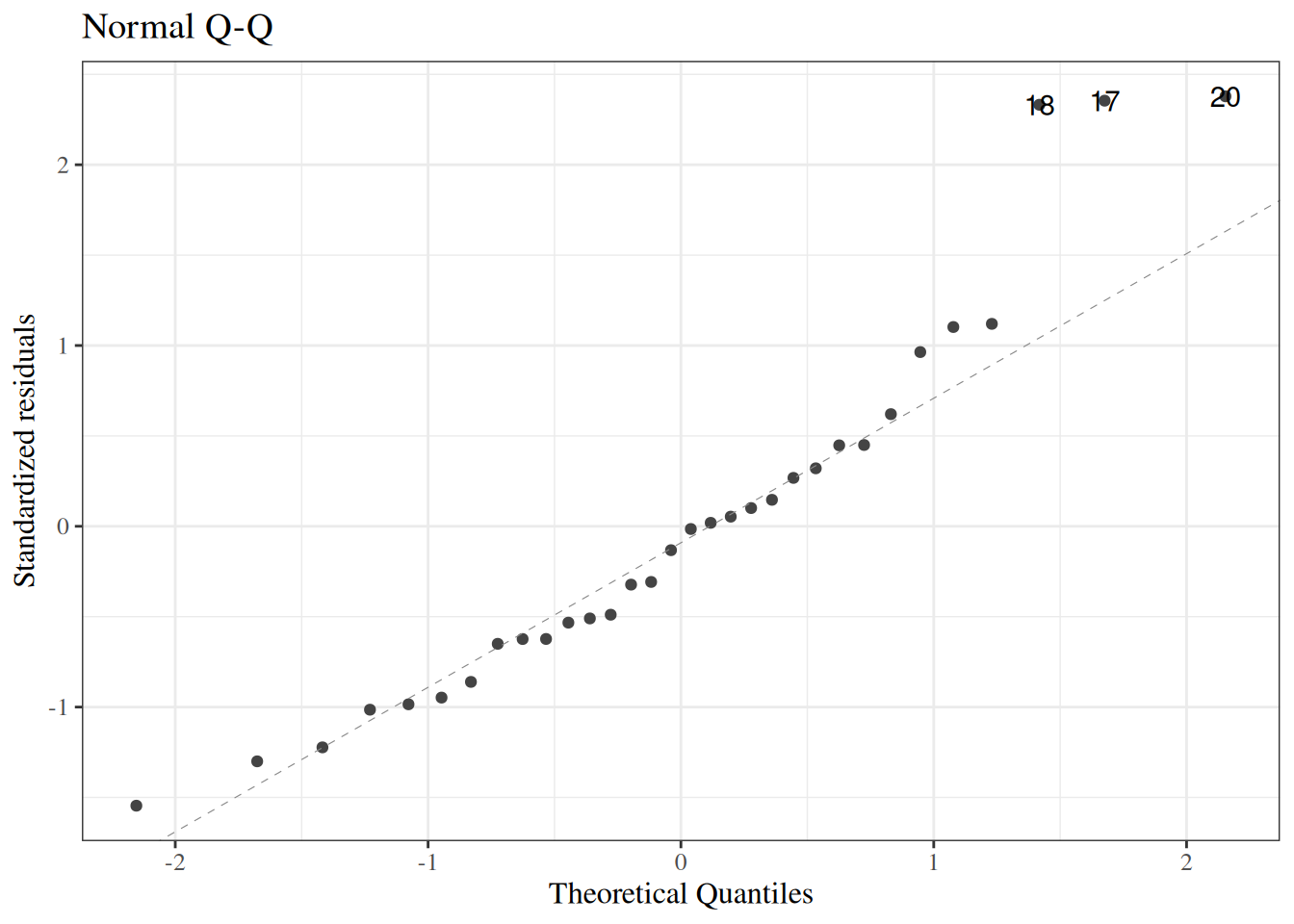
eoc_mtcars_fit <-lm(mpg ~ wt + hp, data = eoc_mtcars)autoplot(eoc_mtcars_fit, which =1, ncol =1)autoplot(eoc_mtcars_fit, which =2, ncol =1)
Figure 50: Diagnostic plots for linear model fit to mtcars data
(a) Residuals versus fitted
(b) Normal Q-Q
Solution.
The residual-vs-fitted plot shows nonlinearity and non-constant spread. The Q-Q plot shows mild tail departures from normality.
The correct conclusion is that linearity and constant-variance assumptions are the most questionable here. A practical next step is to fit a model with a nonlinear weight term (for example, a spline or polynomial in wt) and then re-check diagnostics.
Exercises
Exercise 25 (Likelihood for simple linear regression) (adapted from Kleinbaum et al. (2014), Chapter 6, and Dobson and Barnett (2018), Chapter 6)
Since \(-\frac{n}{2}\text{log}{\left\{2\pi\sigma^2\right\}}\) does not depend on \(\beta_0\) or \(\beta_1\), and \(\sigma^2 > 0\), maximizing \(\ell\) over \((\beta_0, \beta_1)\) is equivalent to maximizing \(-\frac{\text{RSS}}{2\sigma^2}\), which is equivalent to minimizing \(\text{RSS}\).
This shows that for Gaussian errors, the maximum likelihood estimator equals the ordinary least squares estimator.
Exercise 26 (Score equations for simple linear regression) (adapted from Dobson and Barnett (2018), Chapter 6)
Using the log-likelihood from Exercise 25, derive the score equations for \(\beta_0\) and \(\beta_1\). That is, compute \(\frac{\partial \ell}{\partial \beta_0} = 0\) and \(\frac{\partial \ell}{\partial \beta_1} = 0\), and show they are equivalent to the normal equations:
These are the normal equations, whose solution gives the OLS/MLE estimators \(\hat\beta_0\) and \(\hat\beta_1\).
Exercise 27 (Closed-form OLS estimators (adapted from Vittinghoff et al. (2012), Chapter 4)) Using the normal equations from Exercise 26, show that the closed-form solutions are:
where \(Y\) is diastolic blood pressure (mmHg), \(X_1\) is age (years), and \(X_2\) is an indicator for current smoking (\(X_2 = 1\) for smoker, \(X_2 = 0\) for non-smoker). Suppose the estimates are \(\hat\beta_0 = 55\), \(\hat\beta_1 = 0.4\), \(\hat\beta_2 = 6\).
(a) Interpret \(\hat\beta_0\).
(b) Interpret \(\hat\beta_1\).
(c) Interpret \(\hat\beta_2\).
(d) Predict mean blood pressure for a 50-year-old smoker.
(e) What assumption does this model make about the relationship between age and blood pressure for smokers versus non-smokers?
Solution. (a)
\(\hat\beta_0 = 55\) mmHg is the estimated mean diastolic blood pressure among non-smokers (\(X_2 = 0\)) aged zero (\(X_1 = 0\)). This is an extrapolation beyond the observed range of ages and may not be a meaningful quantity on its own.
(b)
\(\hat\beta_1 = 0.4\) mmHg/year is the estimated mean increase in diastolic blood pressure per one-year increase in age, holding smoking status constant. Or equivalently: among people of the same smoking status, those who are one year older have, on average, 0.4 mmHg higher diastolic blood pressure.
(c)
\(\hat\beta_2 = 6\) mmHg is the estimated mean difference in diastolic blood pressure between current smokers and non-smokers of the same age. Smokers have, on average, 6 mmHg higher diastolic blood pressure than non-smokers of the same age.
The model assumes that the slope of mean blood pressure with respect to age is the same (\(\hat\beta_1 = 0.4\) mmHg/year) for both smokers and non-smokers (parallel slopes or no interaction). An interaction term \(\beta_3 X_1 X_2\) would be needed to allow different slopes.
Exercise 29 (Coefficient of determination) (adapted from Kleinbaum et al. (2014), Chapter 7)
In the simple linear regression of \(Y\) on \(X\), define:
(a) Explain in words what \(\text{TSS}\), \(\text{RSS}\), and \(R^2\) measure.
(b) If \(n = 20\), \(\text{TSS} = 400\), and \(R^2 = 0.75\), compute \(\text{RSS}\).
(c) Is a large \(R^2\) sufficient to conclude the model is correct? Briefly explain.
Solution. (a)
\(\text{TSS}\) (total sum of squares): the total variability in \(Y\) around its mean \(\bar{y}\), ignoring the predictor \(X\).
\(\text{RSS}\) (residual sum of squares): the residual variability in \(Y\) remaining after accounting for the linear regression on \(X\). Smaller values indicate a better-fitting model.
\(R^2\): the proportion of the total variability in \(Y\) explained by the linear regression on \(X\). \(R^2 = 0\) means \(X\) explains none of the variation; \(R^2 = 1\) means \(X\) perfectly predicts \(Y\).
No. A high \(R^2\) indicates good fit in terms of variance explained, but does not guarantee the model is correctly specified. For example:
The true relationship may be nonlinear, and a high \(R^2\) can still be achieved with a linear model over a limited range.
Important confounders or interaction terms may be omitted.
The residuals may violate the model assumptions (non-normality, heteroscedasticity, dependence), which would invalidate inference even with high \(R^2\).
References
Akaike, Hirotugu. 1974. “A New Look at the Statistical Model Identification.”IEEE Transactions on Automatic Control 19 (6): 716–23. https://doi.org/10.1109/TAC.1974.1100705.
Anderson, Edgar. 1935. “The Irises of the Gaspe Peninsula.”Bulletin of American Iris Society 59: 2–5.
Harrell, Frank E. 2015. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis. 2nd ed. Springer. https://doi.org/10.1007/978-3-319-19425-7.
Heinze, Georg, Christine Wallisch, and Daniela Dunkler. 2018. “Variable Selection – A Review and Recommendations for the Practicing Statistician.”Biometrical Journal 60 (3): 431–49. https://doi.org/10.1002/bimj.201700067.
Hogg, Robert V., Elliot A. Tanis, and Dale L. Zimmerman. 2015. Probability and Statistical Inference. Ninth edition. Pearson.
Hulley, Stephen, Deborah Grady, Trudy Bush, et al. 1998. “Randomized Trial of Estrogen Plus Progestin for Secondary Prevention of Coronary Heart Disease in Postmenopausal Women.”JAMA : The Journal of the American Medical Association (Chicago, IL) 280 (7): 605–13.
James, Gareth, Daniela Witten, Trevor Hastie, Robert Tibshirani, et al. 2013. An Introduction to Statistical Learning. Vol. 112. Springer. https://www.statlearning.com/.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in R. 2nd ed. Springer. https://doi.org/10.1007/978-1-0716-1418-1.
Vittinghoff, Eric, David V Glidden, Stephen C Shiboski, and Charles E McCulloch. 2012. Regression Methods in Biostatistics: Linear, Logistic, Survival, and Repeated Measures Models. 2nd ed. Springer. https://doi.org/10.1007/978-1-4614-1353-0.
Weisberg, Sanford. 2005. Applied Linear Regression. Vol. 528. John Wiley & Sons.