Functions from these packages will be used throughout this document:
[R code]
library(conflicted) # check for conflicting function definitions# library(printr) # inserts help-file output into markdown outputlibrary(rmarkdown) # Convert R Markdown documents into a variety of formats.library(pander) # format tables for markdownlibrary(ggplot2) # graphicslibrary(ggfortify) # help with graphicslibrary(dplyr) # manipulate datalibrary(tibble) # `tibble`s extend `data.frame`slibrary(magrittr) # `%>%` and other additional piping toolslibrary(haven) # import Stata fileslibrary(knitr) # format R output for markdownlibrary(tidyr) # Tools to help to create tidy datalibrary(plotly) # interactive graphicslibrary(dobson) # datasets from Dobson and Barnett 2018library(parameters) # format model output tables for markdownlibrary(haven) # import Stata fileslibrary(latex2exp) # use LaTeX in R code (for figures and tables)library(fs) # filesystem path manipulationslibrary(survival) # survival analysislibrary(survminer) # survival analysis graphicslibrary(KMsurv) # datasets from Klein and Moeschbergerlibrary(parameters) # format model output tables forlibrary(webshot2) # convert interactive content to static for pdflibrary(forcats) # functions for categorical variables ("factors")library(stringr) # functions for dealing with stringslibrary(lubridate) # functions for dealing with dates and times
Here are some R settings I use in this document:
[R code]
rm(list =ls()) # delete any data that's already loaded into Rconflicts_prefer(dplyr::filter)ggplot2::theme_set( ggplot2::theme_bw() +# ggplot2::labs(col = "") + ggplot2::theme(legend.position ="bottom",text = ggplot2::element_text(size =12, family ="serif")))knitr::opts_chunk$set(message =FALSE)options('digits'=6)panderOptions("big.mark", ",")pander::panderOptions("table.emphasize.rownames", FALSE)pander::panderOptions("table.split.table", Inf)conflicts_prefer(dplyr::filter) # use the `filter()` function from dplyr() by defaultlegend_text_size =9run_graphs =TRUE
Logistic regression differs from linear regression, which uses the Gaussian (“normal”) distribution to model the outcome variable, conditional on the covariates.
Exercise 4 Recall: what kinds of outcomes is linear regression used for?
Solution 4. Linear regression is typically used for numerical outcomes that aren’t event counts or waiting times for an event.
Examples of outcomes that are often analyzed using linear regression include:
weight
height
income
prices
1.1 Risk estimation and prediction
Example 1 (Oral Contraceptive Use and Heart Attack)
Research question: how does oral contraceptive (OC) use affect the risk of myocardial infarction (MI; a.k.a. heart attack)?
Exercise 6 What does the term “controls” mean in the context of study design?
Solution 6.
Definition 2 (Two meanings of “controls”) Depending on context, “controls” can mean either:
individuals who don’t experience an exposure of interest,
or individuals who don’t experience an outcome of interest.
Exercise 7 What types of studies do the two definitions of controls correspond to?
Solution 7.
Definition 3 (cases and controls in retrospective studies) In retrospective case-control studies, participants who experience the outcome of interest are called cases, while participants who don’t experience that outcome are called controls.
Definition 4 (treatment groups and control groups in prospective studies) In prospective studies, the group of participants who experience the treatment or exposure of interest is called the treatment group, while the participants who receive the baseline or comparison treatment (for example, clinical trial participants who receive a placebo or a standard-of-care treatment rather than an experimental treatment) are called controls.
1.2 Comparing probabilities
Risk differences
Definition 5 (Risk difference) The risk difference of two probabilities, \(\pi_1\), and \(\pi_2\), is the difference of their values: \[\delta(\pi_1,\pi_2) \stackrel{\text{def}}{=}\pi_1 - \pi_2\]
Example 2 (Difference in MI risk) In Example 1, the maximum likelihood estimate of the difference in MI risk between OC users and OC non-users is:
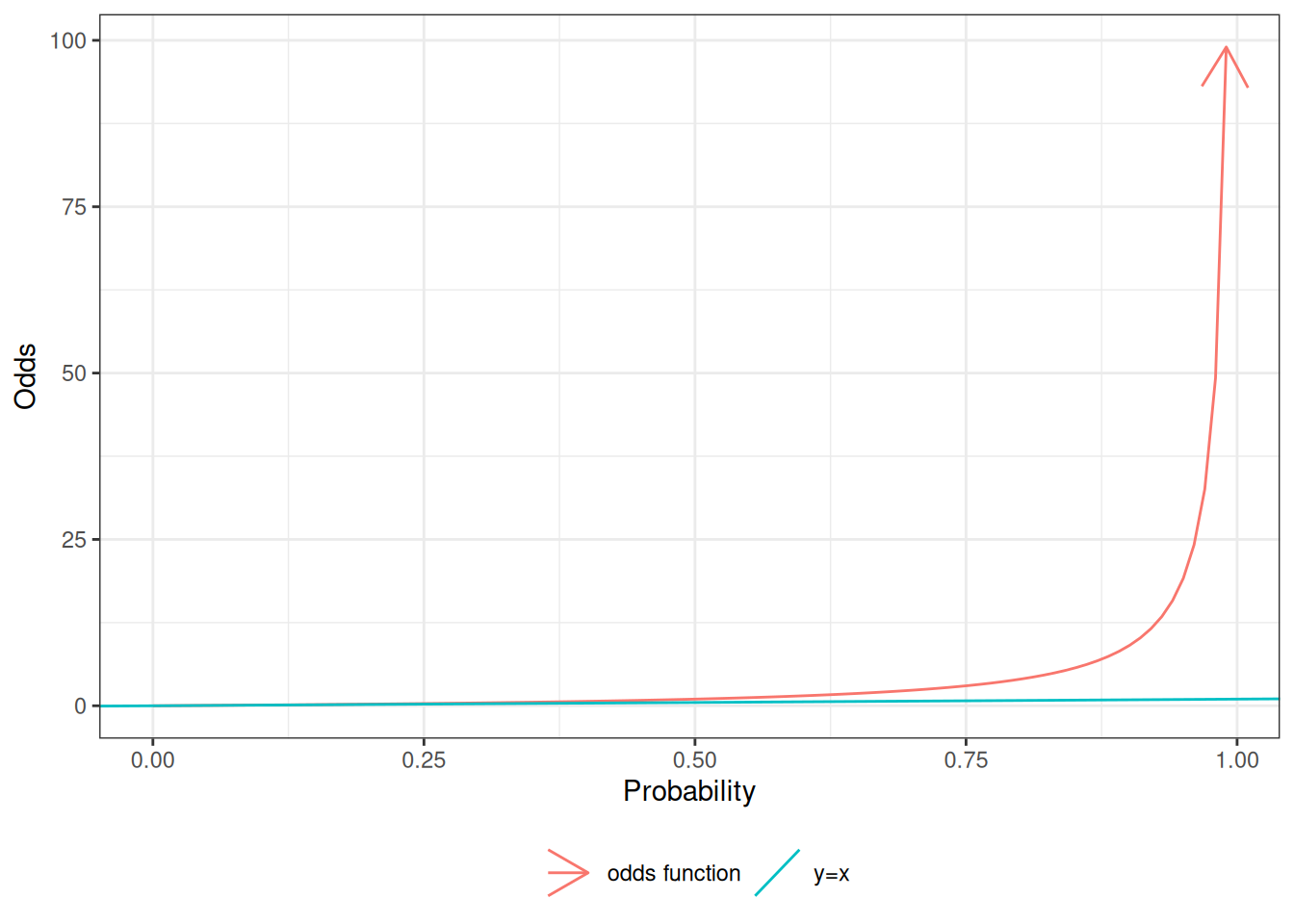
Example 4 (Computing odds from probabilities) In Exercise 5, we estimated that the probability of MI, given OC use, is \(\pi(OC) \stackrel{\text{def}}{=}\Pr(MI|OC) = 0.0026\). If this estimate is correct, then the odds of MI, given OC use, is:
Corollary 2 (Odds of a non-event) If \(\pi\) is the odds of event \(A\) and \(\omega\) is the corresponding odds of \(A\), then the odds of \(\neg A\) are:
\[
\begin{aligned}
\omega(\neg A) &= \frac{1-\pi}{\pi}
\\&= \pi^{-1}-1
\end{aligned}
\]
Proof. Left to the reader.
Odds of rare events
Exercise 17 What odds value corresponds to the probability \(\pi = 0.2\), and what is the numerical difference between these two values?
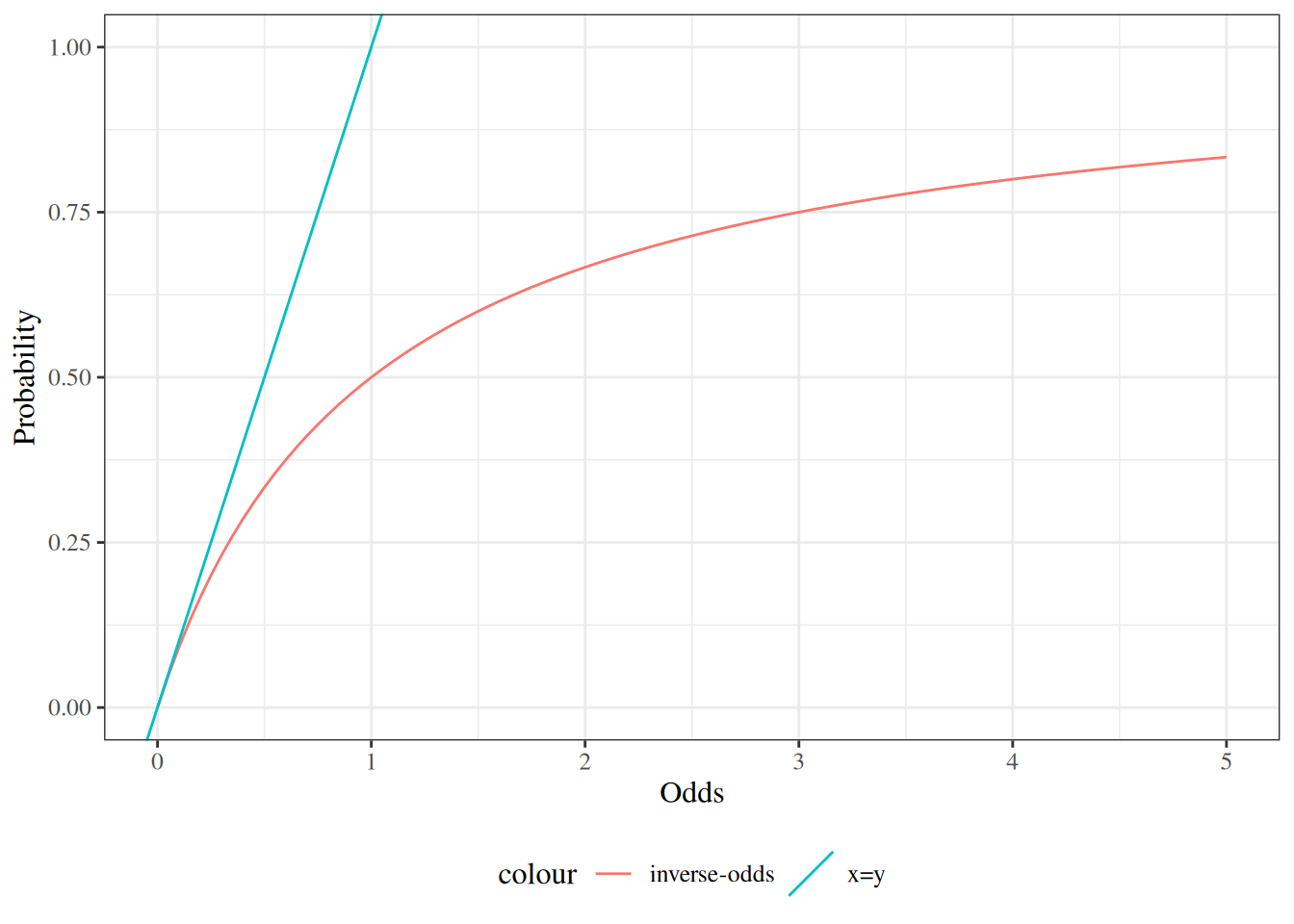
Exercise 19 If \(\pi\) is the probability of an event \(A\) and \(\omega\) is the corresponding odds of \(A\), how can we compute \(\pi\) from \(\omega\)?
For example, if \(\omega= 3/2\), what is \(\pi\)?
Solution 17. Starting from Theorem 2, we can solve Equation 3 for \(\pi\) in terms of \(\omega\):
There’s a 1:1 mapping between probability and odds, and according to that mapping, the odds are equal between two covariate patterns IF and ONLY IF the probabilities are also equal between those patterns. So, testing whether an odds ratio = 1 is equivalent to testing whether the corresponding risk ratio = 1, and also equivalent to testing whether the risk difference = 0. Therefore, in hypothesis testing, if the null hypothesis is no effect, then we can shift between RD, RR, and OR. But when we’re talking about point estimates and CIs, we need to limit our conclusions to the effect measure(s) that we actually estimated, because the sizes of RDs, RRs, and ORs don’t have a simple relationship to each other, except when pi_1=pi_2 (as shown by Figure 3).
Example 8 In Example 1, the outcome is rare for both OC and non-OC participants, so the odds for both groups are similar to the corresponding probabilities, and the odds ratio is similar the risk ratio.
Case 2: frequent events
\[\pi_1 = .4\]
\[\pi_2 = .5\]
For more frequently-occurring outcomes, this won’t be the case:
Exercise 24 Calculate the odds ratio of MI with respect to OC use, assuming that Table 1 comes from a case-control study. Confirm that the result is the same as in Example 6.
Solution.
[R code]
tbl_oc_mi |> pander::pander()
Table 3: Simulated data from study of oral contraceptive use and heart attack risk
If a cross-sectional study is a uniform probability sample of a population (which it rarely is), then we can estimate prevalence (sometimes called “prevalence risk” or just “risk”) using standard methods (Lee 1994), and we can thus also estimate prevalence differences, prevalence ratios, and prevalence odds ratios comparing sub-populations.
If the cross-sectional study is a stratified probability sample, then we can estimate prevalence, prevalence differences, prevalence ratios, and prevalence odds ratios using specialized methods for complex surveys (Lumley 2010).
If the study has sampling biases that we cannot adjust for with survey weights, such as in a convenience sample, then we need to treat it in the same way as a case-control study, and we cannot validly estimate prevalence, prevalence differences, or prevalence ratios; we can only validly estimate prevalence odds ratios.
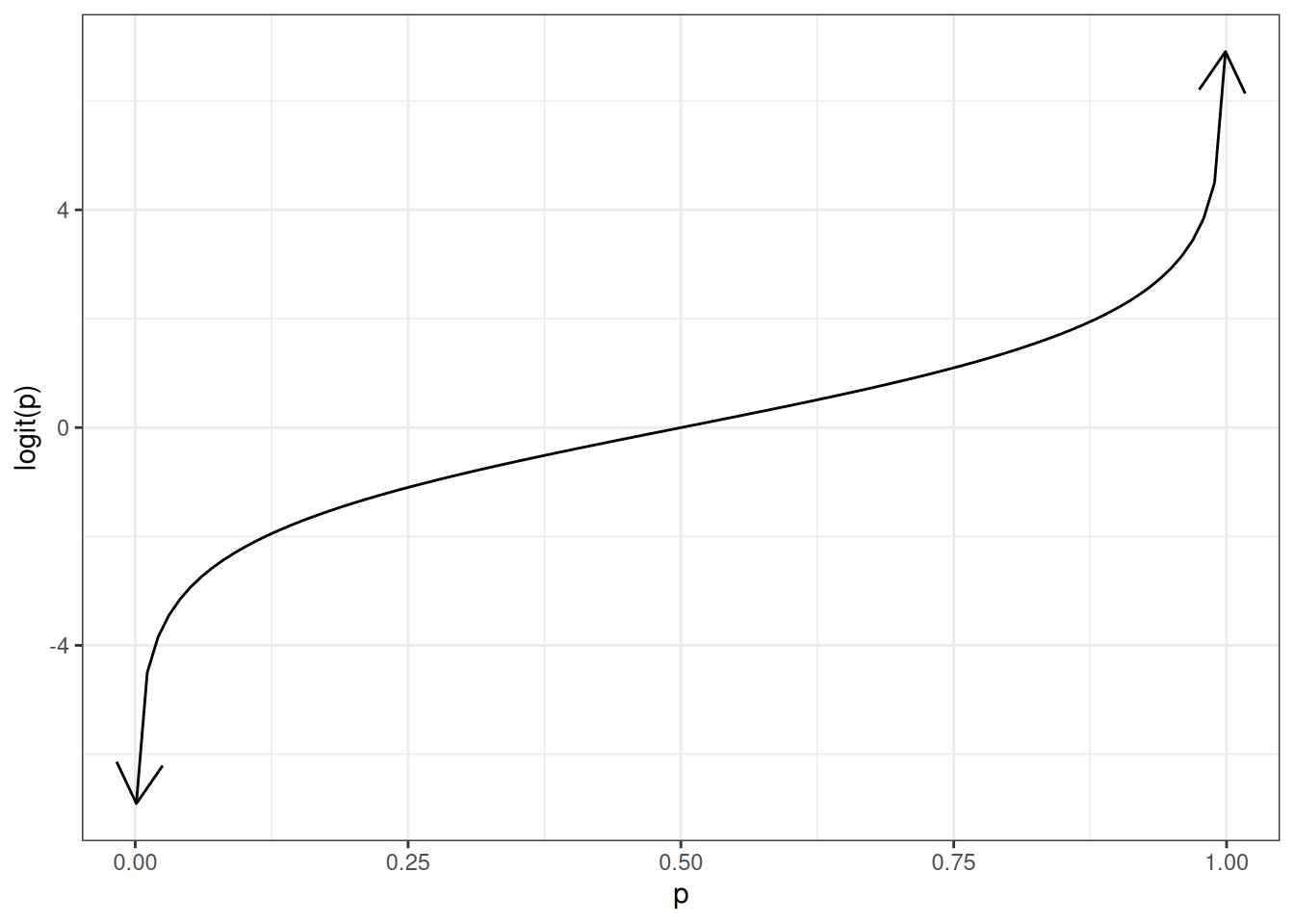
Theorem 10 If \(\pi\) is the probability of an event \(A\), \(\omega\) is the corresponding odds of \(A\), and \(\eta\) is the corresponding log-odds of \(A\), then:
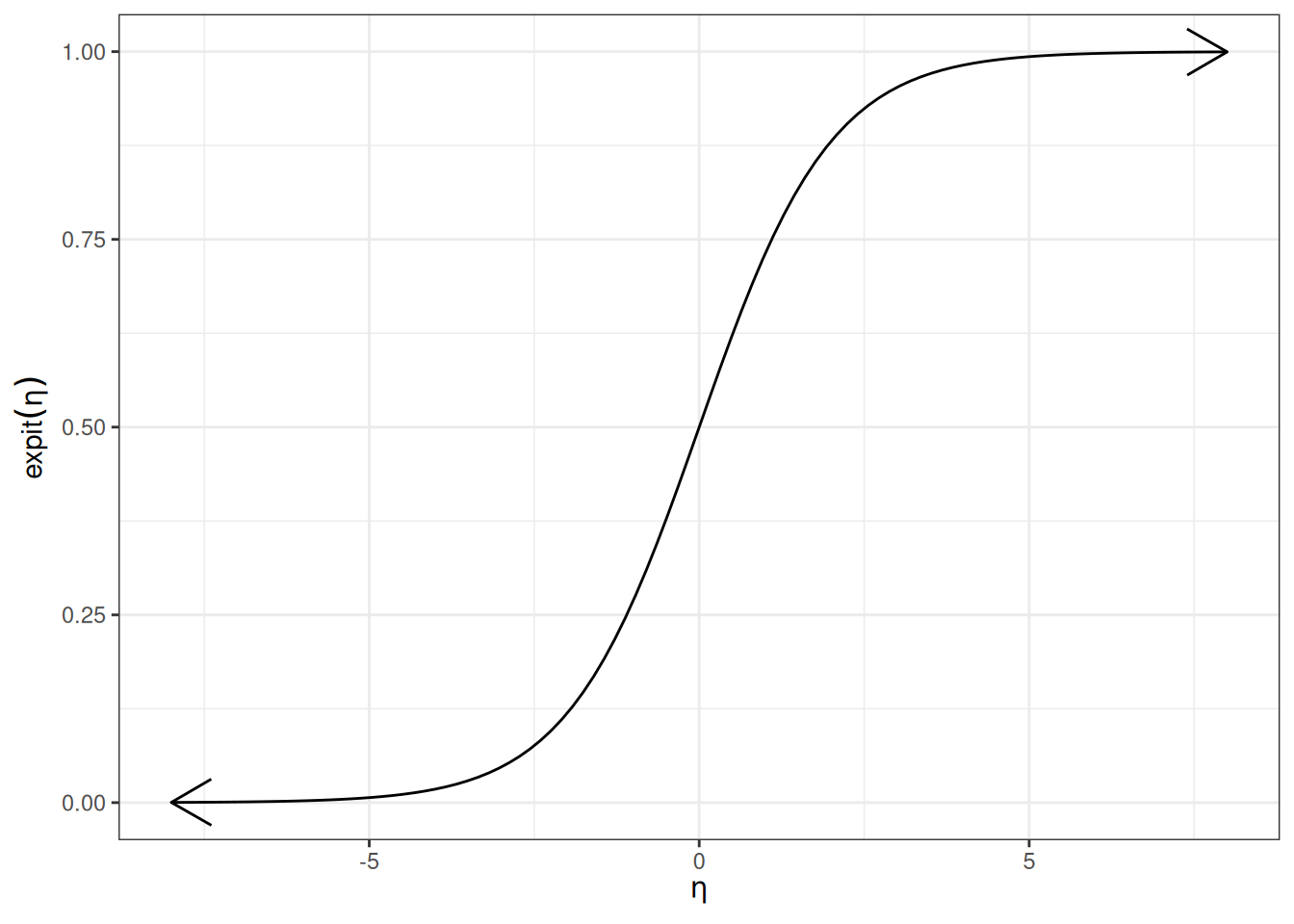
Definition 15 (expit, logistic, inverse-logit) The expit function of a log-odds \(\eta\), also known as the inverse-logit function or logistic function, is the inverse-odds of the exponential of \(\eta\):
Proof. Apply definitions and Lemma 1. Details left to the reader.
Theorem 14 If \(\pi\) is the probability of an event \(A\), \(\omega\) is the corresponding odds of \(A\), and \(\eta\) is the corresponding log-odds of \(A\), then:
Exercise 26 Let \(\tilde{y}\) represent a data set of mutually independent binary outcomes, each with a potentially different event probability \(\pi_i\):
In order to interpret \(\beta_j\): differentiate or difference \({\color{red}\eta(\tilde{x})}\) with respect to \({\color{red}x_j}\) (depending on whether \(x_j\) is continuous or discrete, respectively):
In order to find the MLE \(\hat{\tilde{\beta}}\): differentiate the log-likelihood function \({\color{blue}\ell(\tilde{\beta})}\) with respect to \({\color{blue}\tilde{\beta}}\):
Solution 24 (General formula for odds ratios in logistic regression). \[
\begin{aligned}
\theta(\tilde{x},{\tilde{x}^*})
&\stackrel{\text{def}}{=}\frac{\omega(\tilde{x})}{\omega({\tilde{x}^*})}
\\
&= \frac{\text{exp}{\left\{\eta(\tilde{x})\right\}}}{\text{exp}{\left\{\eta({\tilde{x}^*})\right\}}}
\\
&= \text{exp}{\left\{{\color{red}\eta(\tilde{x}) - \eta({\tilde{x}^*})}\right\}}
\end{aligned}
\]
Lemma 7 (General formula for odds ratios in logistic regression)\[\theta(\tilde{x},{\tilde{x}^*}) = \text{exp}{\left\{{\color{red}\eta(\tilde{x}) - \eta({\tilde{x}^*})}\right\}} \tag{19}\]
Corollary 10 (Shorthand general formula for odds ratios in logistic regression)\[\theta(\tilde{x},{\tilde{x}^*}) = \text{exp}{\left\{{\color{red}\Delta \eta}\right\}} \tag{20}\]
Exercise 31 (Difference in log-odds) Find a concise expression for the difference in log-odds: \[\Delta \eta\stackrel{\text{def}}{=}{\color{red}\eta(\tilde{x}) - \eta({\tilde{x}^*})}\]
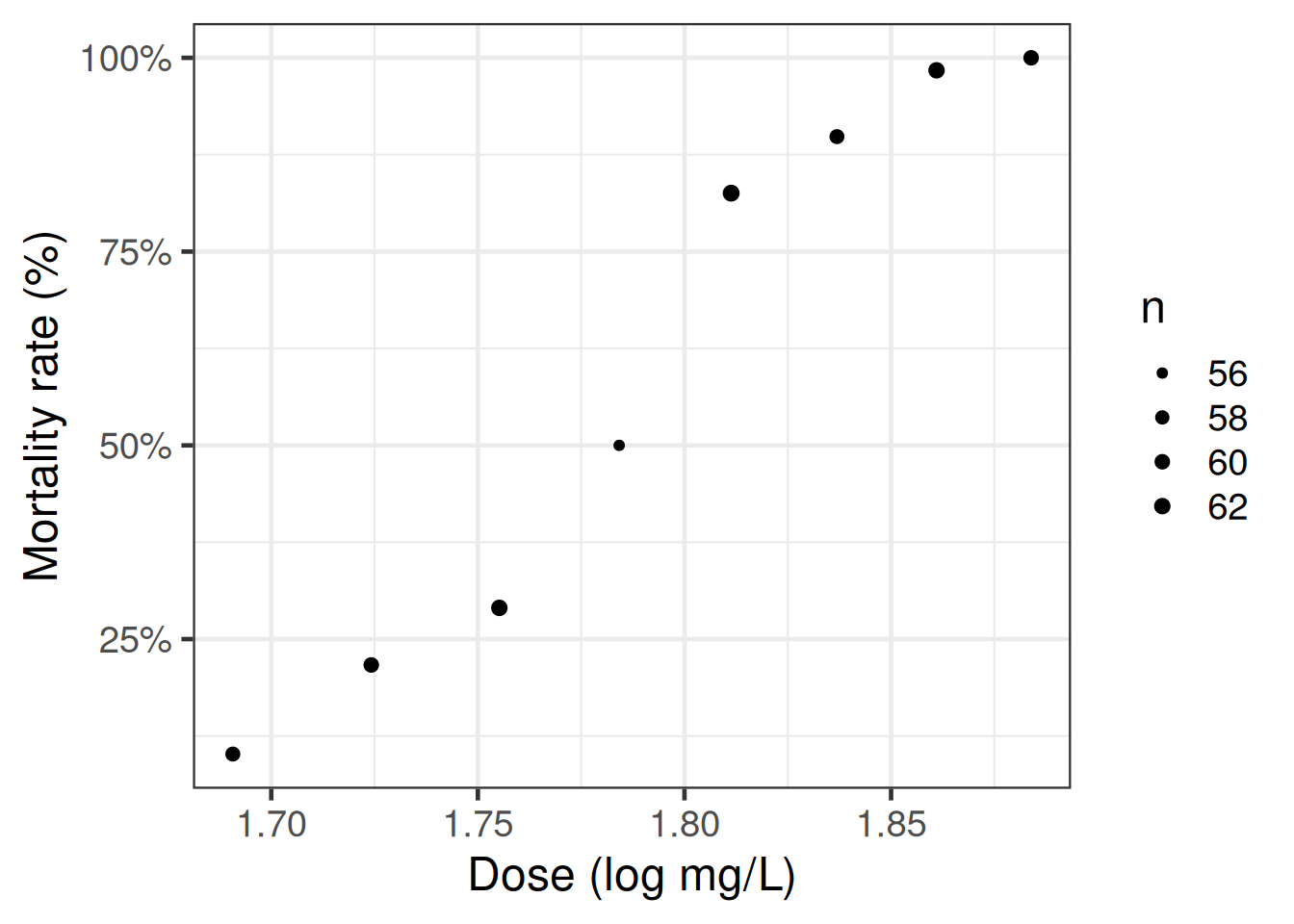
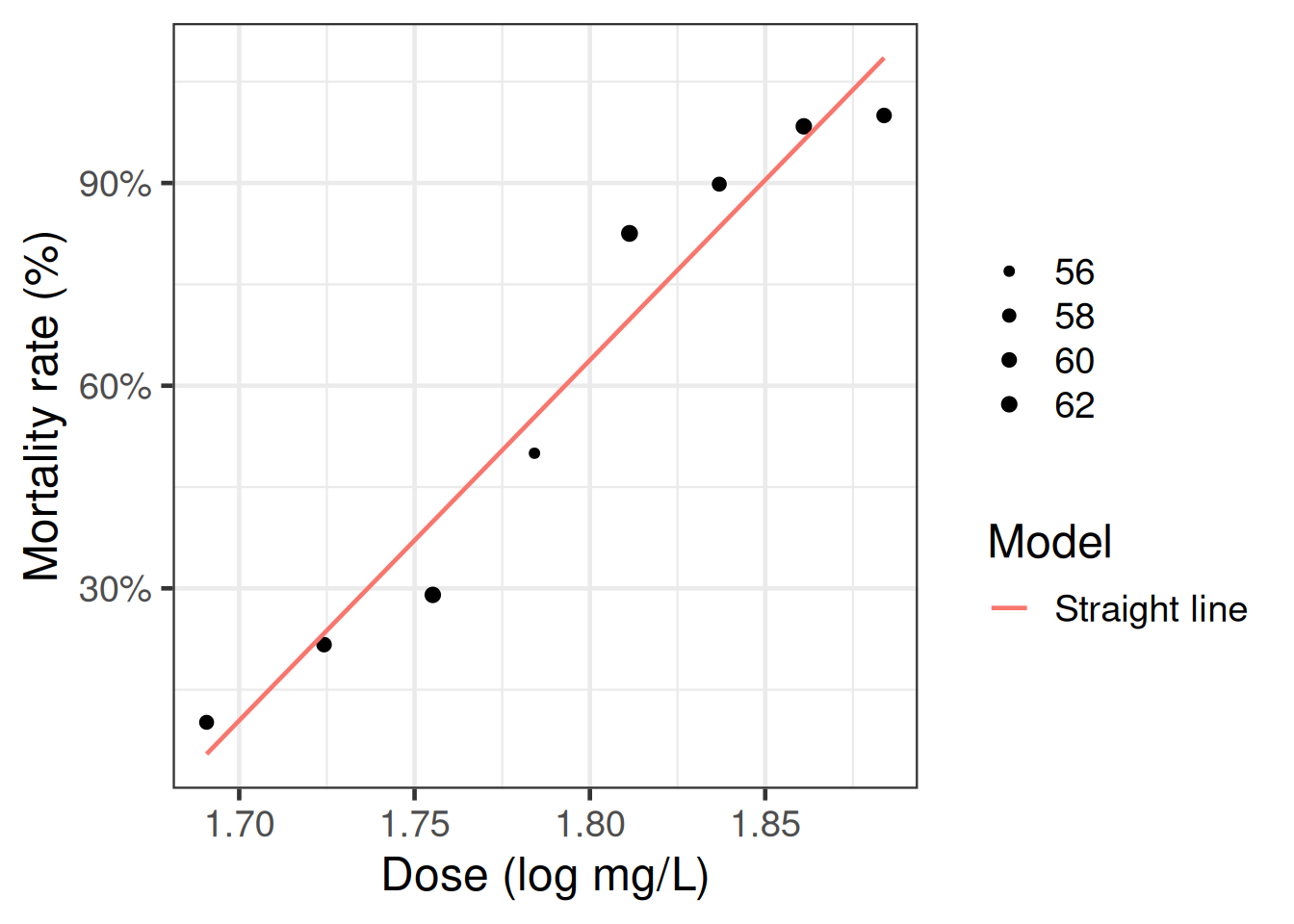
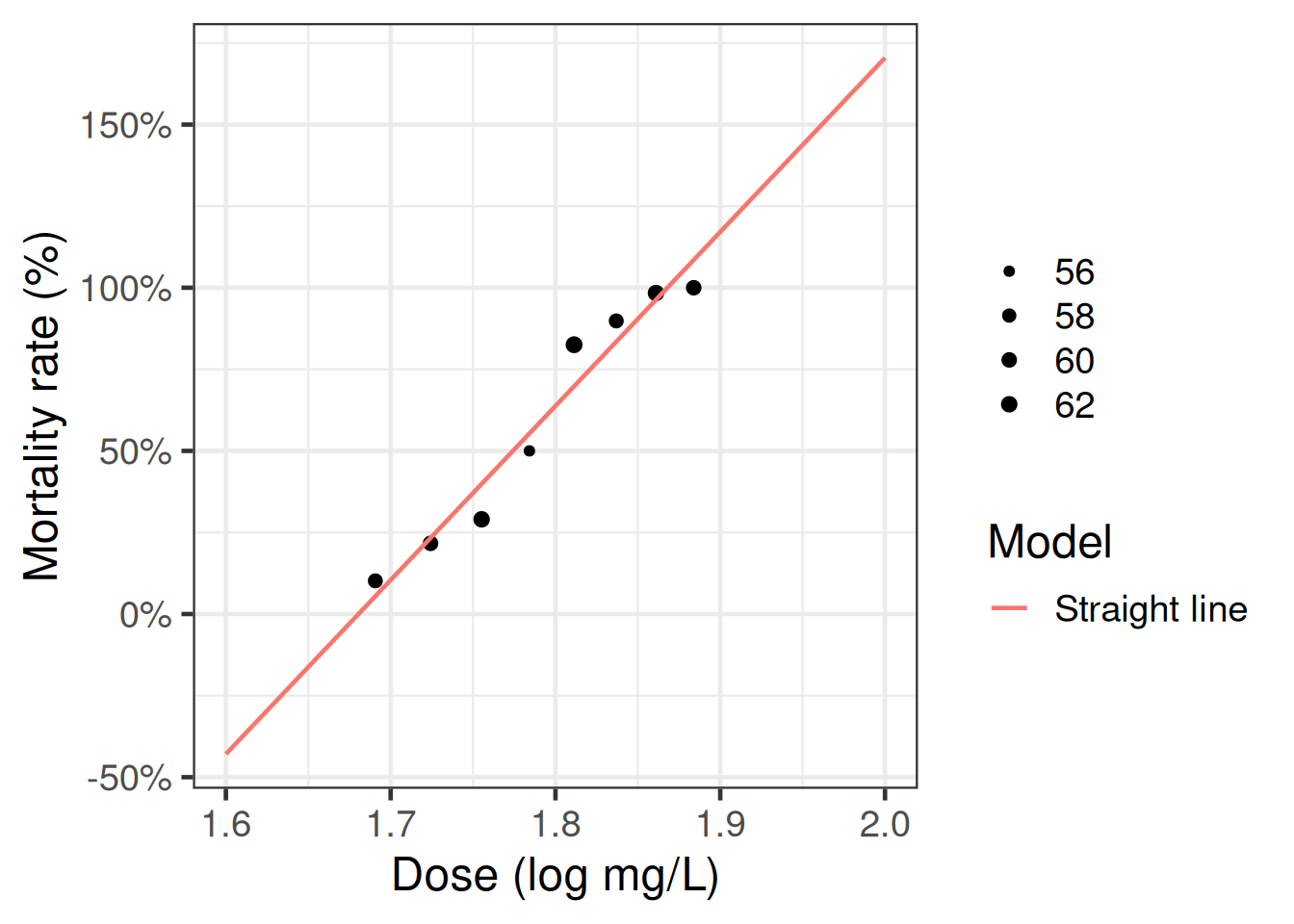
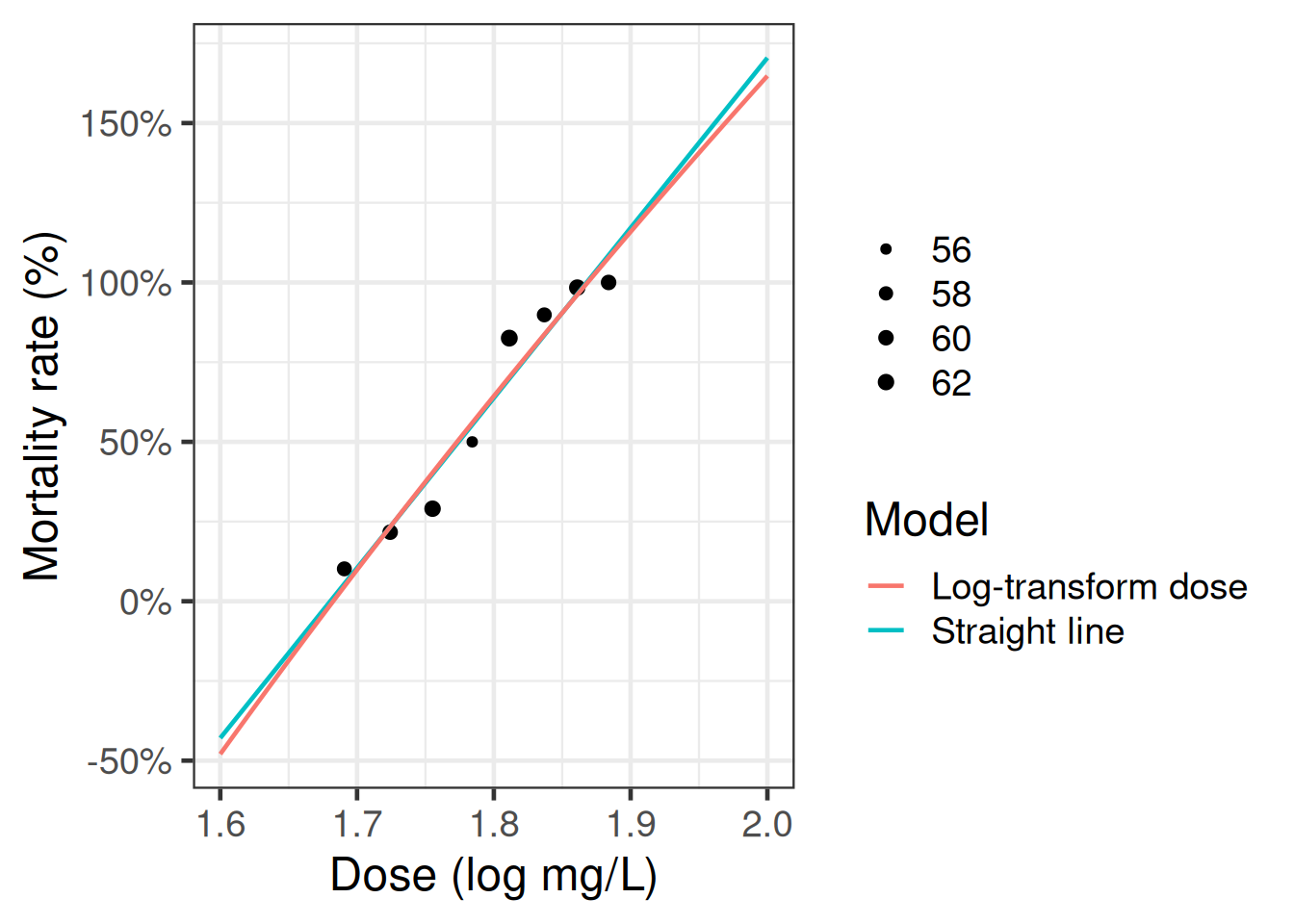
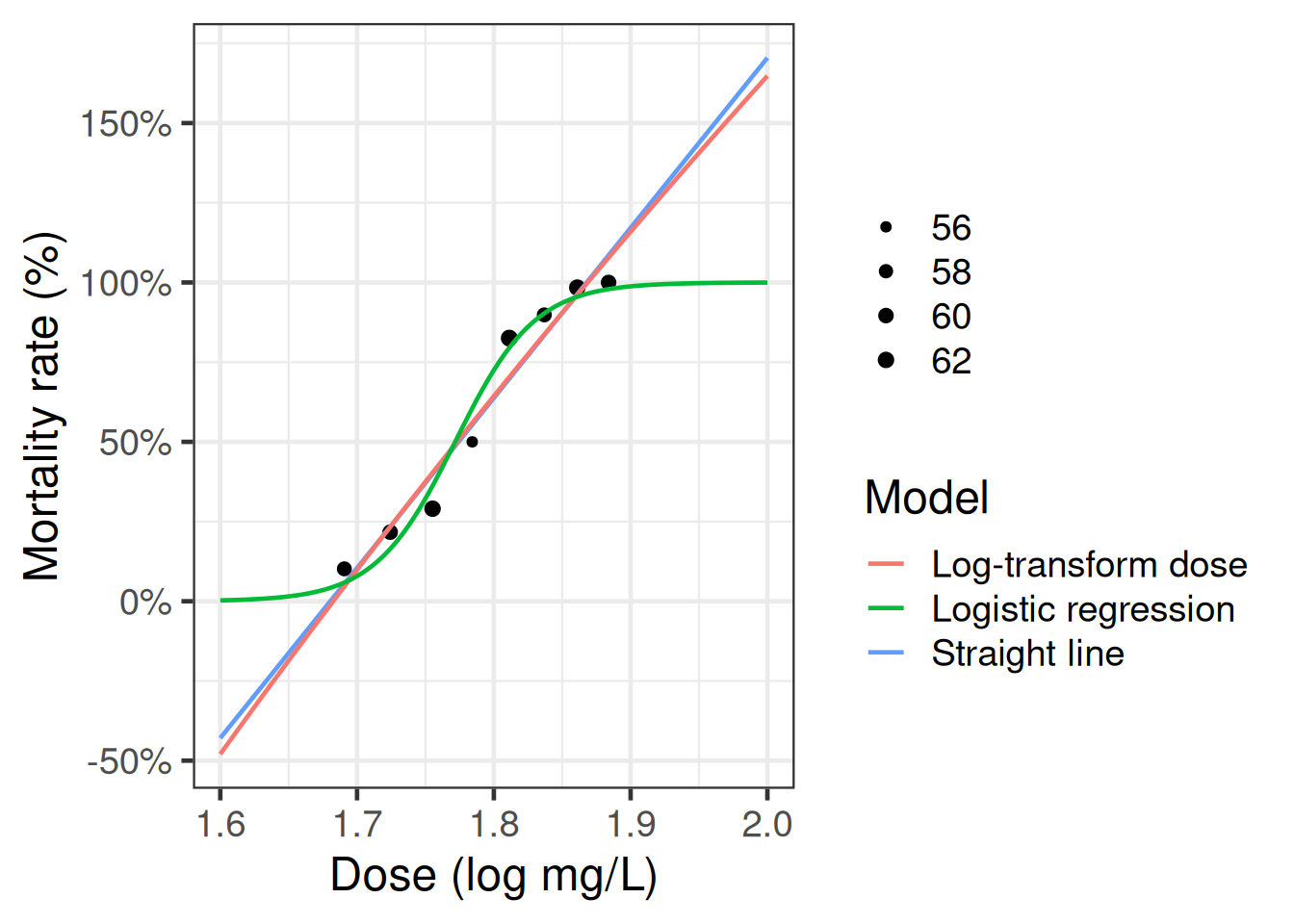
Example 9 In our model for the beetles data, we only have an intercept plus one covariate, gas concentration (\(c\)): \[\tilde{x}= (1, c)\]
If \(c_i\) is the gas concentration for the beetle in observation \(i\), and \(\tilde{c} = (c_1, c_2, ...c_n)\), then the score equation \(\tilde{\ell'} = 0\) means that for the MLE \(\hat{\tilde{\beta}}\):
the sum of the errors (aka deviations) equals 0:
\[\sum_{i=1}^n\varepsilon_i = 0\]
the weighted sum of the error times the gas concentrations equals 0:
\[\sum_{i=1}^nc_i \varepsilon_i = 0 \]
Exercise 36 Implement and graph the score function for the beetles data
where \(\mathbf{D} \stackrel{\text{def}}{=}\text{diag}(\text{Var}{\left(Y_i|X_i=x_i\right)})\) is the diagonal matrix whose \(i^{th}\) diagonal element is \(\text{Var}{\left(Y_i|X_i=x_i\right)}\).
For covariate coefficients (\(k \neq 0\)), \(e^{\beta_k}\) is an odds ratio (the multiplicative change in odds per 1-unit increase in \(x_k\), holding all other covariates fixed). For the intercept (\(k = 0\)), \(e^{\beta_0}\) is the baseline odds (the odds when all covariates equal zero), not an odds ratio.
In R
In R, parameters() from the parameters package automatically computes Wald tests and confidence intervals for logistic regression model coefficients:
Table 14: Wald tests and 95% CIs for beetles logistic regression
Parameter
Log-Odds
SE
95% CI
z
p
(Intercept)
-60.72
5.18
(-71.44, -51.08)
-11.72
< .001
dose
34.27
2.91
(28.85, 40.30)
11.77
< .001
Pass exponentiate = TRUE to parameters() to report exponentiated coefficients. The intercept is then interpreted as baseline odds, while the non-intercept coefficients are odds ratios:
Table 15: Exponentiated coefficients and 95% CIs for beetles
Parameter
Odds Ratio
SE
95% CI
z
p
(Intercept)
4.27e-27
2.21e-26
(9.39e-32, 6.56e-23)
-11.72
< .001
dose
7.65e+14
2.23e+15
(3.40e+12, 3.18e+17)
11.77
< .001
6.2 Inference for predicted probabilities
Exercise 39 Given a maximum likelihood estimate \(\hat \beta\) and a corresponding estimated covariance matrix \(\hat \Sigma\stackrel{\text{def}}{=}\widehat{\text{Cov}}(\hat \beta)\), calculate a 95% confidence interval for the predicted probability \(\pi(\tilde{x}) = \Pr(Y = 1 | \tilde{X}= \tilde{x})\).
Theorem 27 (Estimated variance and standard error of log-odds)\[
{\color{orange}\widehat{\text{Var}}{\left(\hat\eta(\tilde{x})\right)}} = {\color{orange}{\tilde{x}}^{\top}\hat{\Sigma}\tilde{x}}
\tag{35}\]
In R, predict() with type = "link" and se.fit = TRUE computes the estimated log-odds \(\hat\eta(\tilde{x}) = \tilde{x}'\hat \beta\) and its estimated standard error for each covariate pattern:
Table 16: Predicted log-odds and 95% CI for beetles logistic regression
dose
logodds_hat
se
ci_lower_logodds
ci_upper_logodds
pi_hat
ci_lower_prob
ci_upper_prob
1.7
-2.458
0.263
-2.974
-1.942
0.079
0.049
0.125
1.8
0.969
0.145
0.685
1.253
0.725
0.665
0.778
1.9
4.396
0.377
3.656
5.136
0.988
0.975
0.994
6.3 Inference for odds ratios
Exercise 42 Given a maximum likelihood estimate \(\hat \beta\) and a corresponding estimated covariance matrix \(\hat \Sigma\stackrel{\text{def}}{=}\widehat{\text{Cov}}(\hat \beta)\), calculate a 95% confidence interval for the odds ratio comparing covariate patterns \(\tilde{x}\) and \({\tilde{x}^*}\), \(\theta(\tilde{x},{\tilde{x}^*})\).
Theorem 28 (Estimated variance and standard error of difference in log-odds)\[
{\color{orange}\widehat{\text{Var}}{\left(\Delta{\hat\eta}\right)}} = {\color{orange}{\Delta\tilde{x}}^{\top}\hat{\Sigma}(\Delta\tilde{x})}
\tag{42}\]
“The Western Collaborative Group Study (WCGS) was a large epidemiological study designed to investigate the association between the”type A” behavior pattern and coronary heart disease (CHD)“.
Exercise 45 What is “type A” behavior?
Solution 39. From Wikipedia, “Type A and Type B personality theory”:
“The hypothesis describes Type A individuals as outgoing, ambitious, rigidly organized, highly status-conscious, impatient, anxious, proactive, and concerned with time management….
The hypothesis describes Type B individuals as a contrast to those of Type A. Type B personalities, by definition, are noted to live at lower stress levels. They typically work steadily and may enjoy achievement, although they have a greater tendency to disregard physical or mental stress when they do not achieve.”
Study design
from ?faraway::wcgs:
3154 healthy young men aged 39-59 from the San Francisco area were assessed for their personality type. All were free from coronary heart disease at the start of the research. Eight and a half years later change in CHD status was recorded.
Details (from faraway::wcgs)
The WCGS began in 1960 with 3,524 male volunteers who were employed by 11 California companies. Subjects were 39 to 59 years old and free of heart disease as determined by electrocardiogram. After the initial screening, the study population dropped to 3,154 and the number of companies to 10 because of various exclusions. The cohort comprised both blue- and white-collar employees.
Baseline data collection
socio-demographic characteristics:
age
education
marital status
income
occupation
physical and physiological including:
height
weight
blood pressure
electrocardiogram
corneal arcus
biochemical measurements:
cholesterol and lipoprotein fractions;
medical and family history and use of medications;
behavioral data:
Type A interview,
smoking,
exercise
alcohol use.
Later surveys added data on:
anthropometry
triglycerides
Jenkins Activity Survey
caffeine use
Average follow-up continued for 8.5 years with repeat examinations.
Load the data
Here, I load the data:
[R code]
### load the data directly from a UCSF website:library(haven)url <-paste0(# I'm breaking up the url into two chunks for readability"https://regression.ucsf.edu/sites/g/files/","tkssra6706/f/wysiwyg/home/data/wcgs.dta")wcgs <- haven::read_dta(url)
Table 18: Baseline characteristics by CHD status at end of follow-up
Characteristic
Overall
N = 3,1541
No
N = 2,8971
Yes
N = 2571
p-value
Age (years)
45.0 (42.0, 50.0)
45.0 (41.0, 50.0)
49.0 (44.0, 53.0)
<0.0012
Arcus Senilis
941 (30%)
839 (29%)
102 (40%)
<0.0013
Missing
2
0
2
Behavioral Pattern
<0.0013
A1
264 (8.4%)
234 (8.1%)
30 (12%)
A2
1,325 (42%)
1,177 (41%)
148 (58%)
B3
1,216 (39%)
1,155 (40%)
61 (24%)
B4
349 (11%)
331 (11%)
18 (7.0%)
Body Mass Index (kg/m2)
24.39 (22.96, 25.84)
24.39 (22.89, 25.84)
24.82 (23.63, 26.50)
<0.0012
Total Cholesterol
223 (197, 253)
221 (195, 250)
245 (222, 276)
<0.0012
Missing
12
12
0
Diastolic Blood Pressure
80 (76, 86)
80 (76, 86)
84 (80, 90)
<0.0012
Behavioral Pattern
<0.0013
Type B
1,565 (50%)
1,486 (51%)
79 (31%)
Type A
1,589 (50%)
1,411 (49%)
178 (69%)
Height (inches)
70.00 (68.00, 72.00)
70.00 (68.00, 72.00)
70.00 (68.00, 71.00)
0.42
Ln of Systolic Blood Pressure
4.84 (4.79, 4.91)
4.84 (4.77, 4.91)
4.87 (4.82, 4.97)
<0.0012
Ln of Weight
5.14 (5.04, 5.20)
5.13 (5.04, 5.20)
5.16 (5.09, 5.22)
<0.0012
Cigarettes per day
0 (0, 20)
0 (0, 20)
20 (0, 30)
<0.0012
Systolic Blood Pressure
126 (120, 136)
126 (118, 136)
130 (124, 144)
<0.0012
Current smoking
1,502 (48%)
1,343 (46%)
159 (62%)
<0.0013
Observation (follow up) time (days)
2,942 (2,842, 3,037)
2,952 (2,864, 3,048)
1,666 (934, 2,400)
<0.0012
Type of CHD Event
<0.0014
None
0 (0%)
0 (0%)
0 (0%)
infdeath
2,897 (92%)
2,897 (100%)
0 (0%)
silent
135 (4.3%)
0 (0%)
135 (53%)
angina
71 (2.3%)
0 (0%)
71 (28%)
4
51 (1.6%)
0 (0%)
51 (20%)
Weight (lbs)
170 (155, 182)
169 (155, 182)
175 (162, 185)
<0.0012
Weight Category
<0.0013
< 140
232 (7.4%)
217 (7.5%)
15 (5.8%)
140-170
1,538 (49%)
1,440 (50%)
98 (38%)
170-200
1,171 (37%)
1,049 (36%)
122 (47%)
> 200
213 (6.8%)
191 (6.6%)
22 (8.6%)
RECODE of age (Age)
<0.0013
35-40
543 (17%)
512 (18%)
31 (12%)
41-45
1,091 (35%)
1,036 (36%)
55 (21%)
46-50
750 (24%)
680 (23%)
70 (27%)
51-55
528 (17%)
463 (16%)
65 (25%)
56-60
242 (7.7%)
206 (7.1%)
36 (14%)
1 Median (Q1, Q3); n (%)
2 Wilcoxon rank sum test
3 Pearson’s Chi-squared test
4 Fisher’s exact test
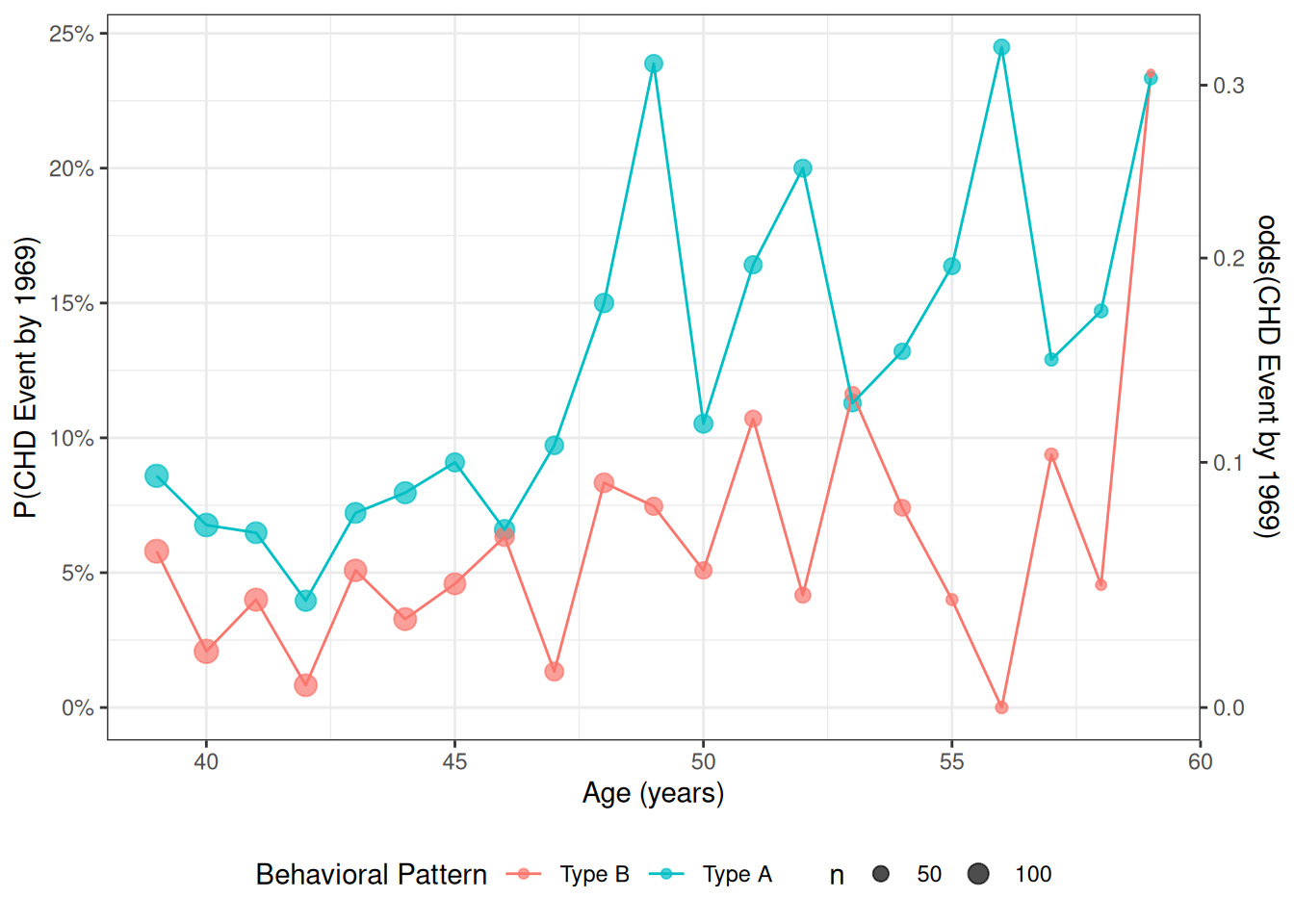
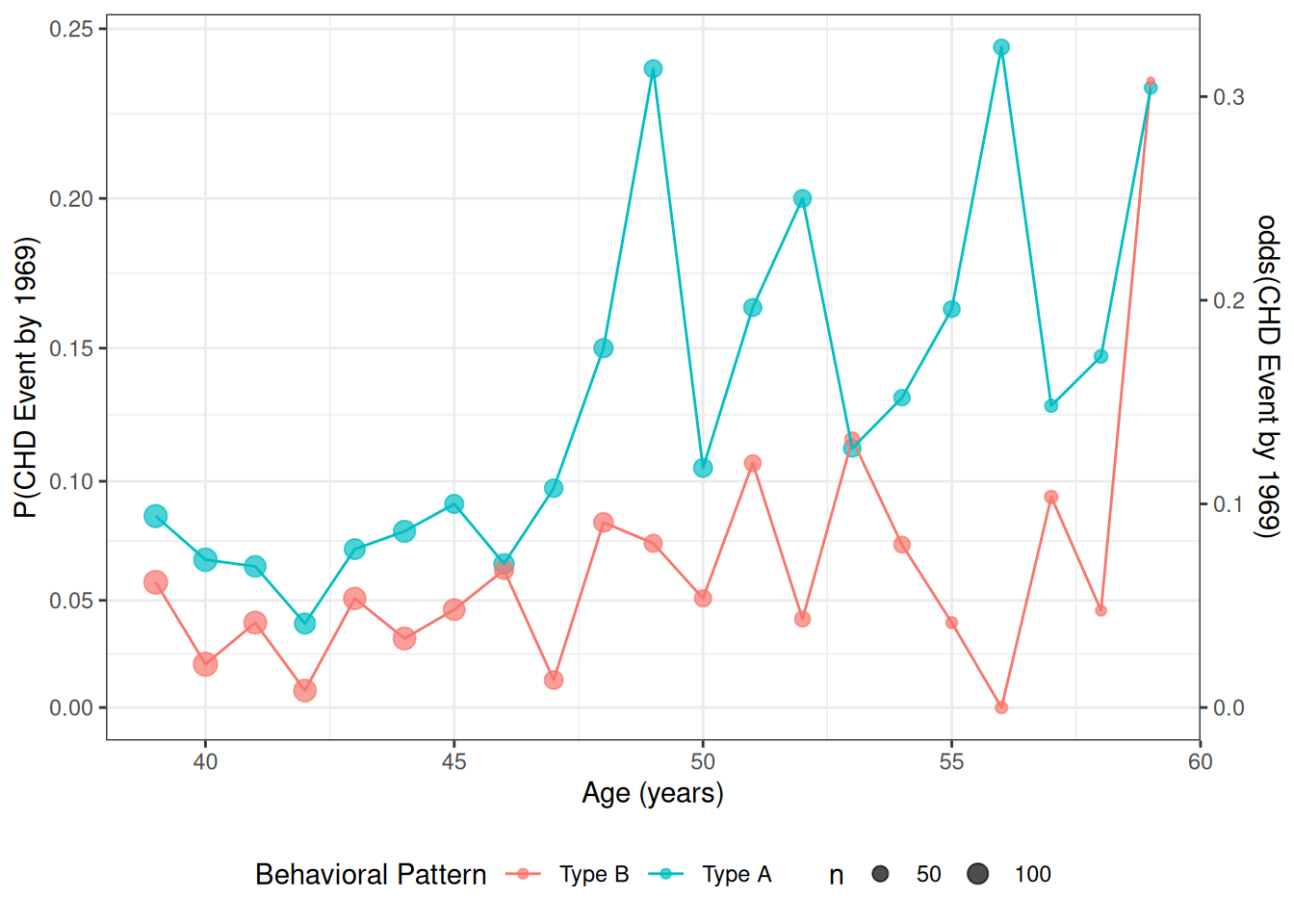
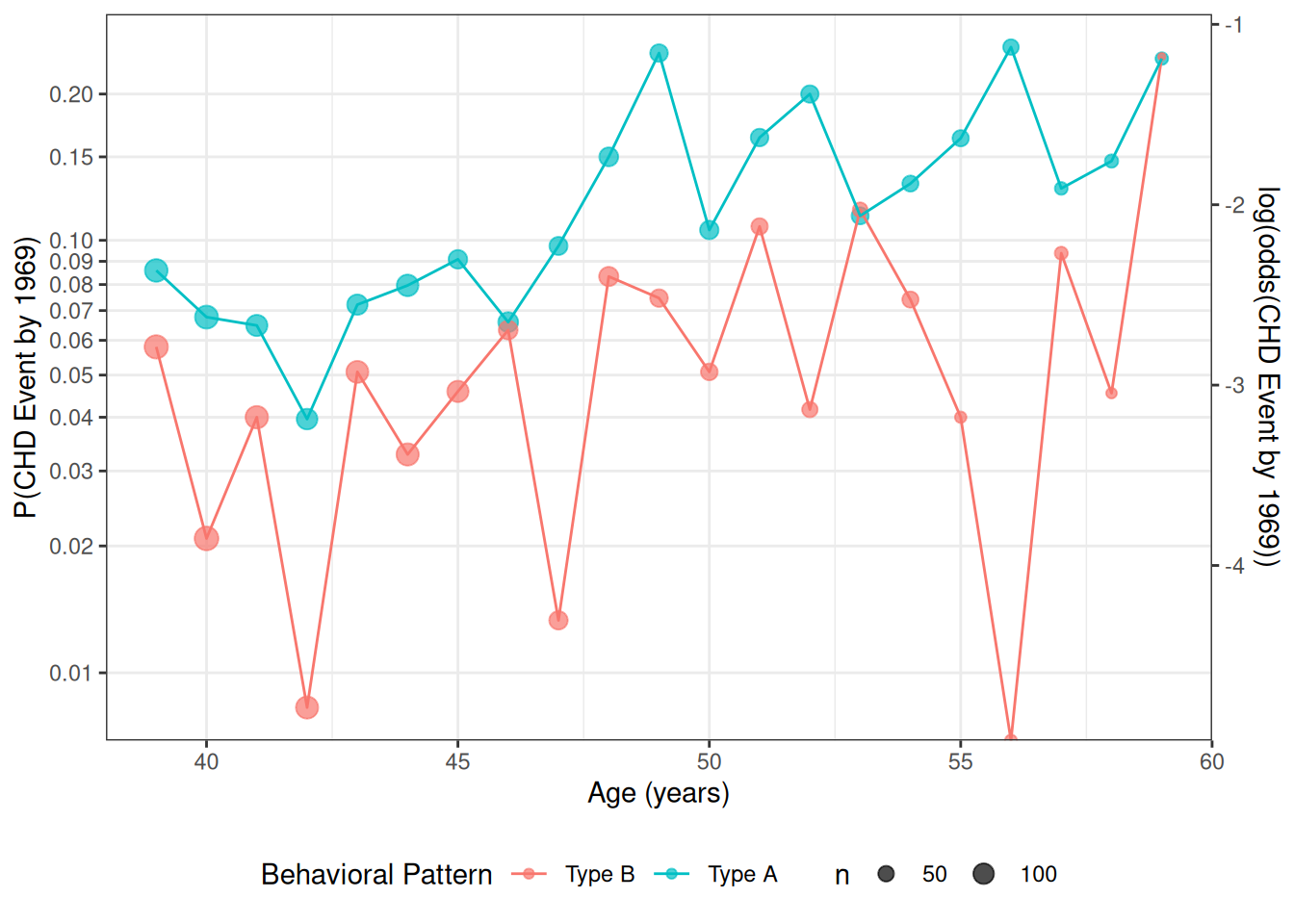
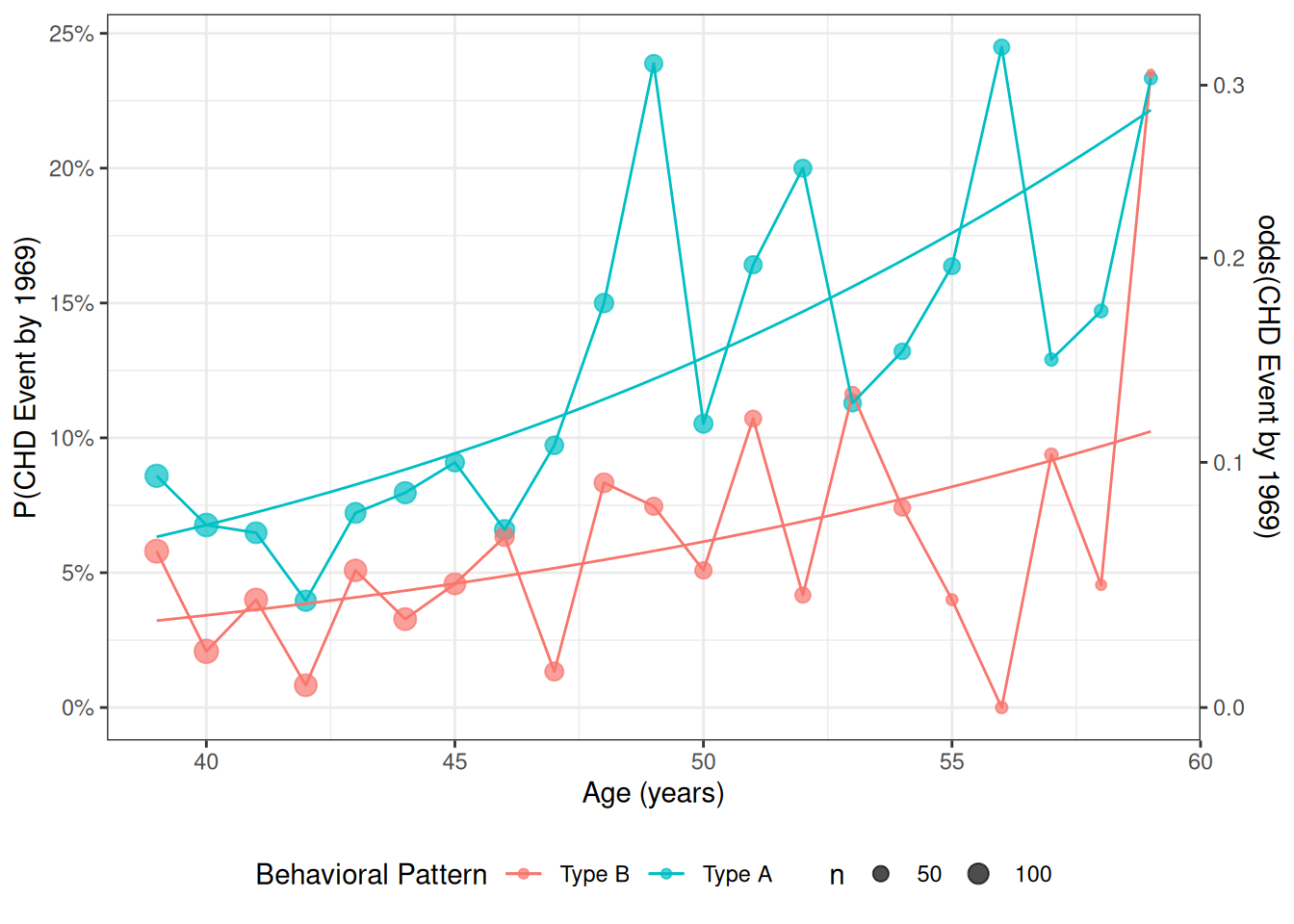
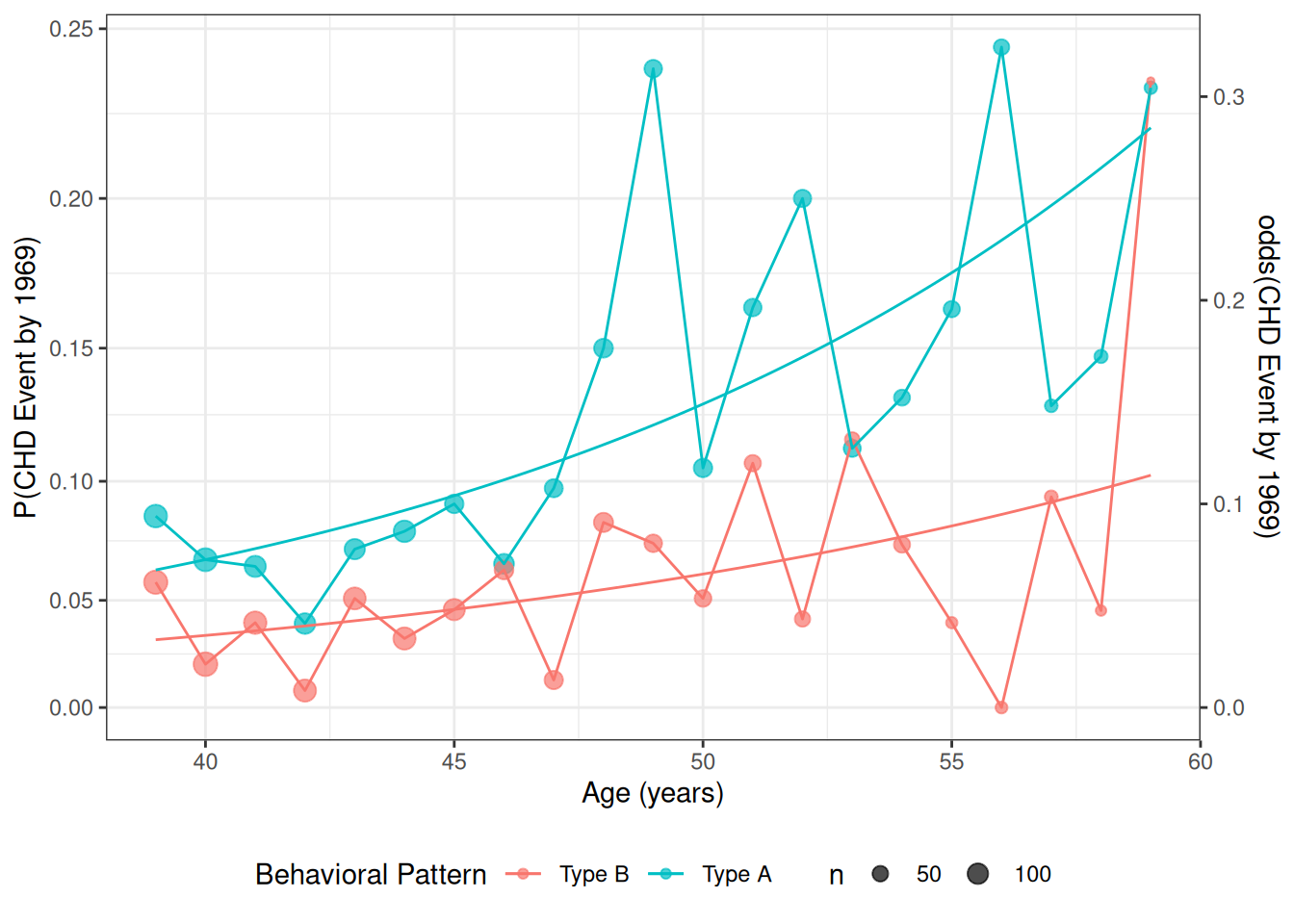
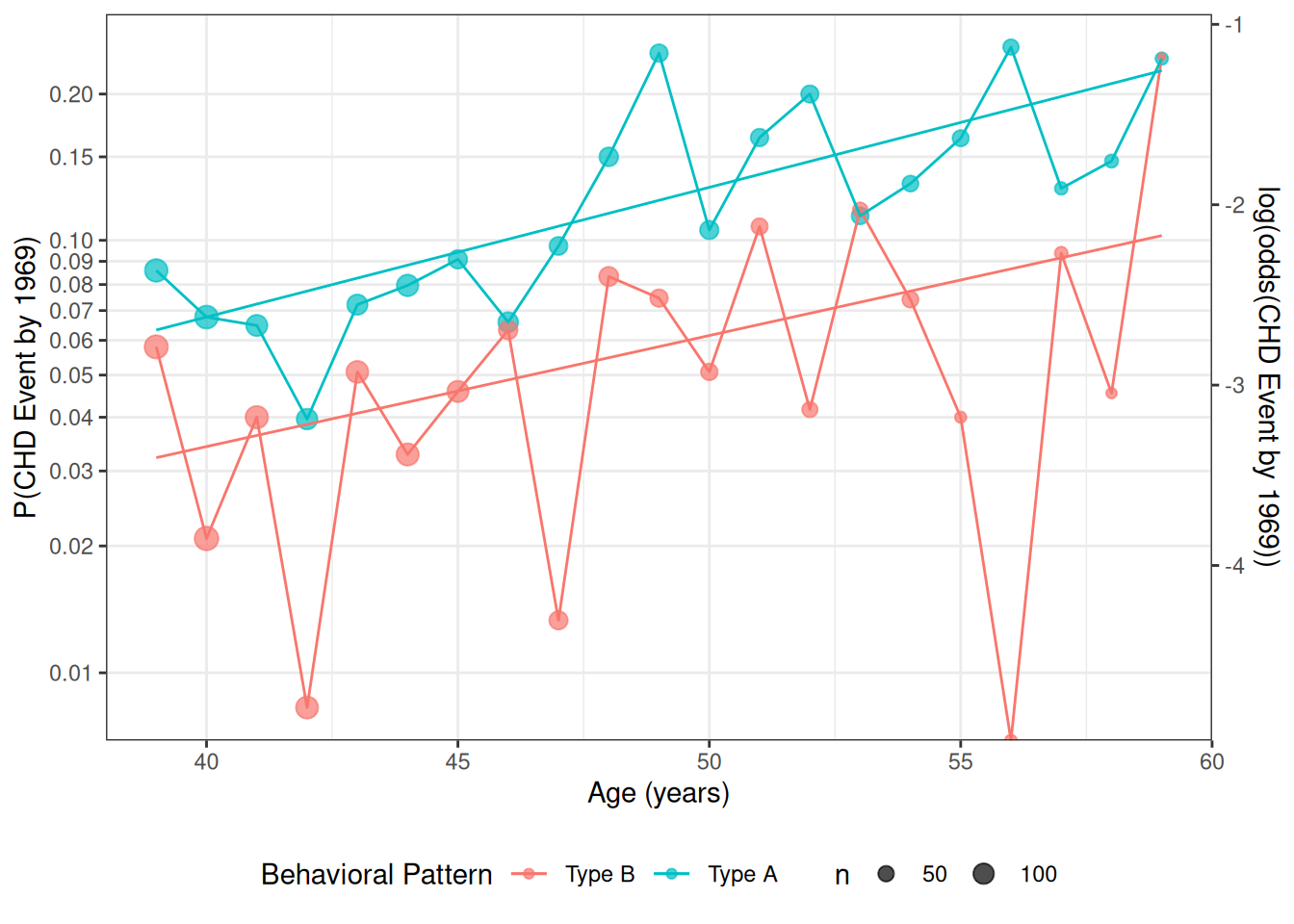
Data by age and personality type
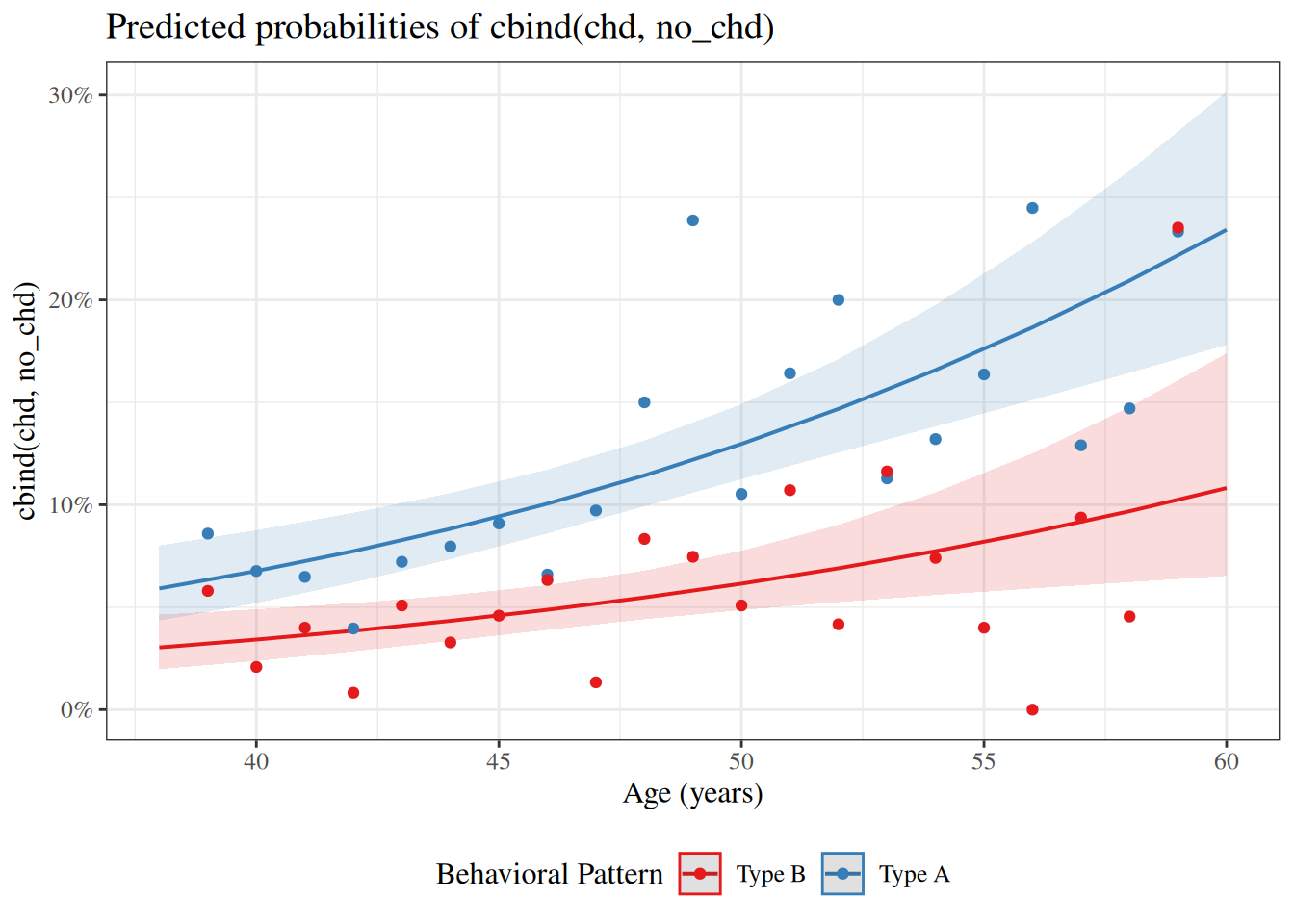
For now, we will look at the interaction between age and personality type (dibpat). To make it easier to visualize the data, we summarize the event rates for each combination of age:
Exercise 46 For Equation 44, derive interpretations of \(\beta_0\), \(\beta_P\), \(\beta_A\), and \(\beta_{PA}\) on the odds and log-odds scales, State the interpretations concisely in math and in words.
\(\beta_{0}\) is the natural logarithm of the odds (“log-odds”) of experiencing CHD for a 0 year-old person with a type B personality; that is,
\(\text{e}^{\beta_{0}}\) is the odds of experiencing CHD for a 0 year-old with a type B personality,
\[
\begin{aligned}
\text{exp}{\left\{\beta_{0}\right\}}
&= \frac{\Pr(Y= 1| P = 0, A = 0)}{1-\Pr(Y= 1| P = 0, A = 0)} \\
&= \frac
{\Pr(Y= 1| P = 0, A = 0)}
{\Pr(Y= 0| P = 0, A = 0)}
\end{aligned}
\]
\[\beta_A = \frac{\partial}{\partial a}\eta(P=0, A = a) \tag{46}\]
\(\beta_A\) is the slope of the log-odds of CHD with respect to age, for individuals with personality type B.
Alternatively:
\[
\begin{aligned}
\beta_{A}
&= \eta(P = 0, A = a + 1)- \eta(P = 0, A = a)
\end{aligned}
\]
That is, \(\beta_{A}\) is the difference in log-odds of experiencing CHD experiencing CHD per one-year difference in age between two individuals with type B personalities.
\[
\begin{aligned}
\text{exp}{\left\{\beta_{A}\right\}} &= \text{exp}{\left\{\eta(P = 0, A = a + 1)- \eta(P = 0, A = a)\right\}}
\\
&= \frac{\text{exp}{\left\{\eta(P = 0, A = a + 1)\right\}}}{\text{exp}{\left\{\eta(P = 0, A = a)\right\}}}
\\
&= \frac{\omega(P = 0, A = a + 1)}{\omega(P = 0, A = a)}
\\
&= \frac
{\text{odds}(Y= 1|P=0, A = a + 1)}
{\text{odds}(Y= 1|P=0, A = a)}
\\
&= \theta(\Delta a = 1 | P = 0)
\end{aligned}
\]
The odds ratio of experiencing CHD (aka “the odds ratio”) differs by a factor of \(\text{e}^{\beta_{A}}\) per one-year difference in age between individuals with type B personality.
\(\beta_{P}\) is the difference in log-odds of experiencing CHD for a 0 year-old person with type A personality compared to a 0 year-old person with type B personality; that is,
\[\beta_P = \eta(P = 1, A = 0) - \eta(P=0, A = 0) \tag{47}\]
\(\text{e}^{\beta_{P}}\) is the ratio of the odds (aka “the odds ratio”) of experiencing CHD, for a 0-year old individual with type A personality vs a 0-year old individual with type B personality; that is,
\[
\text{exp}{\left\{\beta_{P}\right\}}
= \frac
{\text{odds}(Y= 1|P=1, A = 0)}
{\text{odds}(Y= 1|P=0, A = 0)}
\]
\[
\begin{aligned}
\frac{\partial}{\partial a}\eta(P={\color{red}1}, A = a) &= {\color{red}\beta_A + \beta_{PA}}
\\
\frac{\partial}{\partial a}\eta(P={\color{blue}0}, A = a) &= {\color{blue}\beta_A}
\end{aligned}
\]
Therefore:
\[
\begin{aligned}
\frac{\partial}{\partial a}\eta(P={\color{red}1}, A = a) - \frac{\partial}{\partial a}\eta(P={\color{blue}0}, A = a) &= {\color{red}\beta_A + \beta_{PA}} - {\color{blue}\beta_A}
\\
&= \beta_{PA}
\end{aligned}
\]
That is,
\[
\begin{aligned}
\beta_{PA} &= \frac{\partial}{\partial a}\eta(P={\color{red}1}, A = a) - \frac{\partial}{\partial a}\eta(P={\color{blue}0}, A = a)
\\
&= \frac{\partial}{\partial a}\eta(P={\color{red}1}, A = a) - \frac{\partial}{\partial a}\eta(P={\color{blue}0}, A = a)
\end{aligned}
\]
\(\beta_{PA}\) is the difference in the slopes of log-odds over age between participants with Type A personalities and participants with Type B personalities.
Accordingly, the odds ratio of experiencing CHD per one-year difference in age differs by a factor of \(\text{e}^{\beta_{PA}}\) for participants with type A personality compared to participants with type B personality; that is,
\[
\begin{aligned}
\theta(\Delta a = 1 | P = 1)
= \text{exp}{\left\{\beta_{PA}\right\}} \times \theta(\Delta a = 1 | P = 0)
\end{aligned}
\]
or equivalently:
\[
\text{exp}{\left\{\beta_{PA}\right\}} =
\frac
{\theta(\Delta a = 1 | P = 1)}
{\theta(\Delta a = 1 | P = 0)}
\]
See Section 5.1.1 of Vittinghoff et al. (2012) for another perspective, also using the wcgs data as an example.
Exercise 47 If I give you model 1, how would you get the coefficients of model 2?
8 Model comparisons for logistic models
Deviance test
We can compare the maximized log-likelihood of our model, \(\ell(\hat\beta; \mathbf x)\), versus the log-likelihood of the full model (aka saturated model aka maximal model), \(\ell_{\text{full}}\), which has one parameter per covariate pattern. With enough data, \(2(\ell_{\text{full}} - \ell(\hat\beta; \mathbf x)) \dot \sim \chi^2(N - p)\), where \(N\) is the number of distinct covariate patterns and \(p\) is the number of \(\beta\) parameters in our model. A significant p-value for this deviance statistic indicates that there’s some detectable pattern in the data that our model isn’t flexible enough to catch.
Caution
The deviance statistic needs to have a large amount of data for each covariate pattern for the \(\chi^2\) approximation to hold. A guideline from Dobson is that if there are \(q\) distinct covariate patterns \(x_1...,x_q\), with \(n_1,...,n_q\) observations per pattern, then the expected frequencies \(n_k \cdot \pi(x_k)\) should be at least 1 for every pattern \(k\in 1:q\).
If you have covariates measured on a continuous scale, you may not be able to use the deviance tests to assess goodness of fit.
Hosmer-Lemeshow test
If our covariate patterns produce groups that are too small, a reasonable solution is to make bigger groups by merging some of the covariate-pattern groups together.
Hosmer and Lemeshow (1980) proposed that we group the patterns by their predicted probabilities according to the model of interest. For example, you could group all of the observations with predicted probabilities of 10% or less together, then group the observations with 11%-20% probability together, and so on; \(g=10\) categories in all.
Then we can construct a statistic \[X^2 = \sum_{c=1}^g \frac{(o_c - e_c)^2}{e_c}\] where \(o_c\) is the number of events observed in group \(c\), and \(e_c\) is the number of events expected in group \(c\) (based on the sum of the fitted values \(\hat\pi_i\) for observations in group \(c\)).
If each group has enough observations in it, you can compare \(X^2\) to a \(\chi^2\) distribution; by simulation, the degrees of freedom has been found to be approximately \(g-2\).
Our statistic is \(X^2 = 1.110287\); \(p(\chi^2(1) > 1.110287) = 0.29202\), which is our p-value for detecting a lack of goodness of fit.
Unfortunately that grouping plan left us with just three categories with any observations, so instead of grouping by 10% increments of predicted probability, typically analysts use deciles of the predicted probabilities:
Now we have more evenly split categories. The p-value is \(0.56042\), still not significant.
Graphically, we have compared:
[R code]
HL_plot <-# nolint: object_name_linter HL_table |>ggplot(aes(x = pred_prob_cats1)) +geom_line(aes(y = e, x = pred_prob_cats1, group ="Expected", col ="Expected") ) +geom_point(aes(y = e, size = n, col ="Expected")) +geom_point(aes(y = o, size = n, col ="Observed")) +geom_line(aes(y = o, col ="Observed", group ="Observed")) +scale_size(range =c(1, 4)) +theme_bw() +ylab("number of CHD events") +theme(axis.text.x =element_text(angle =45))
Don’t worry about these options for now; I chose them to match autoplot() as closely as I can. plot.glm and autoplot use stats::lowess instead of stats::loess; stats::lowess is older, hard to use with geom_smooth, and hard to match exactly with stats::loess; see https://support.bioconductor.org/p/2323/.]
[R code]
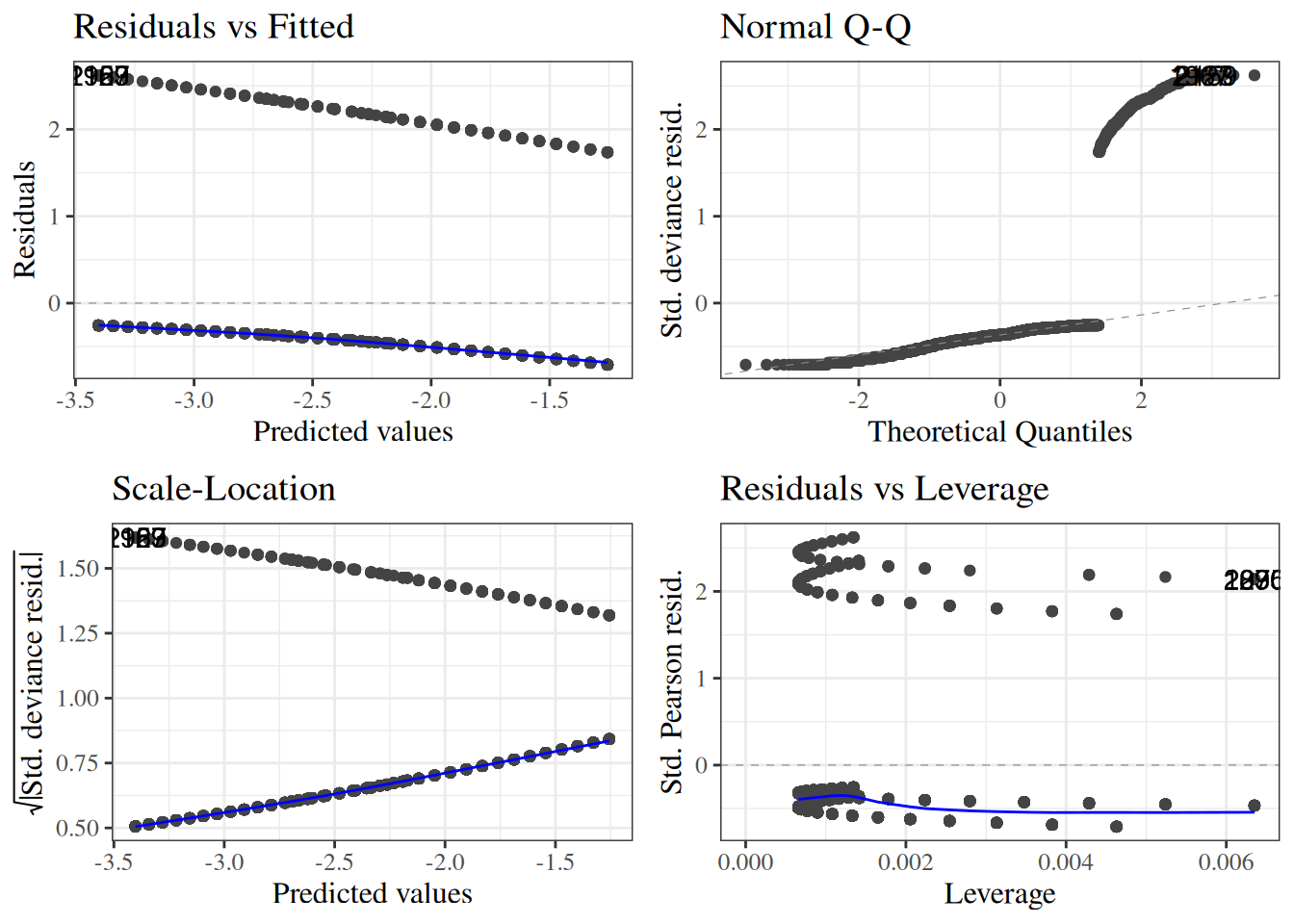
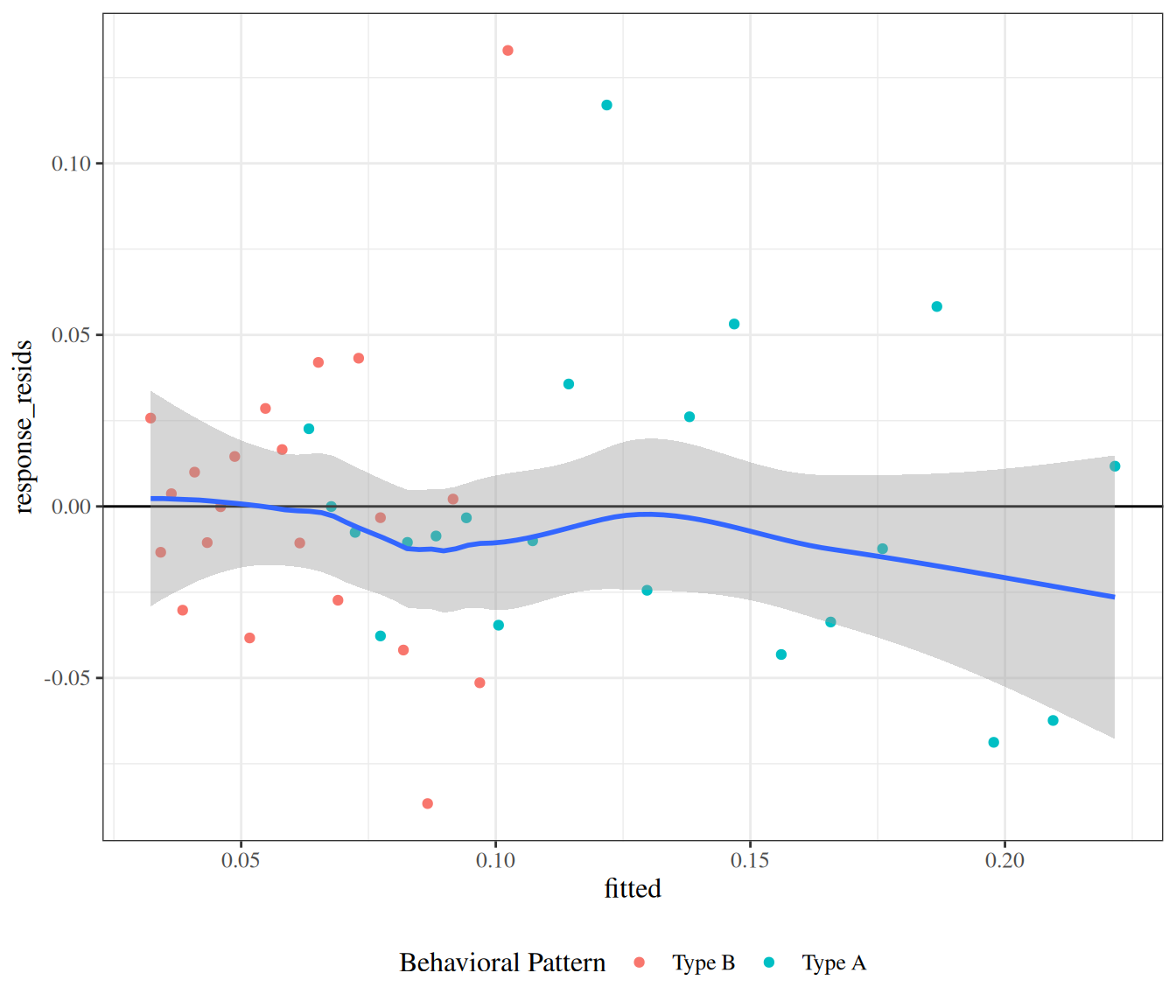
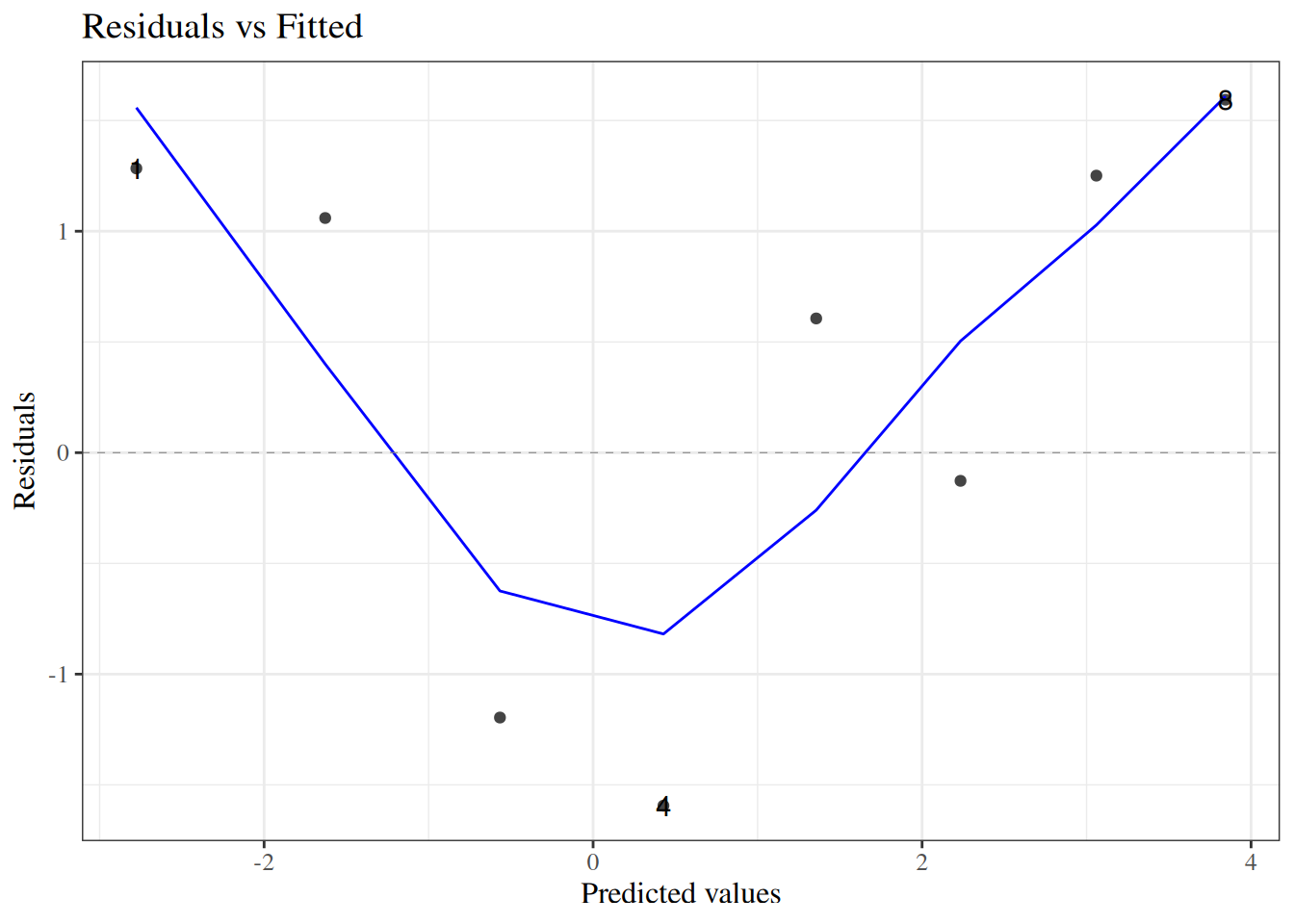
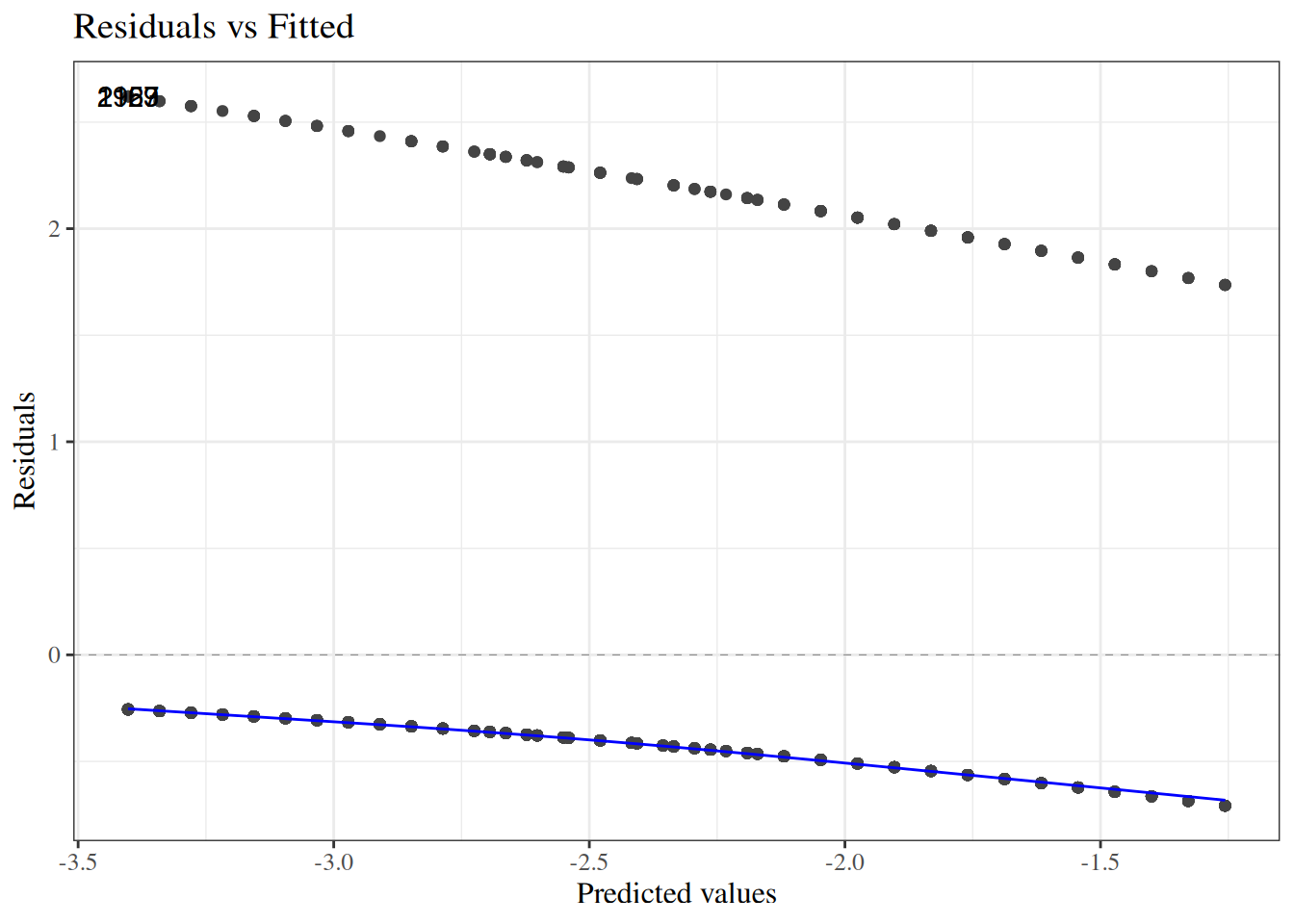
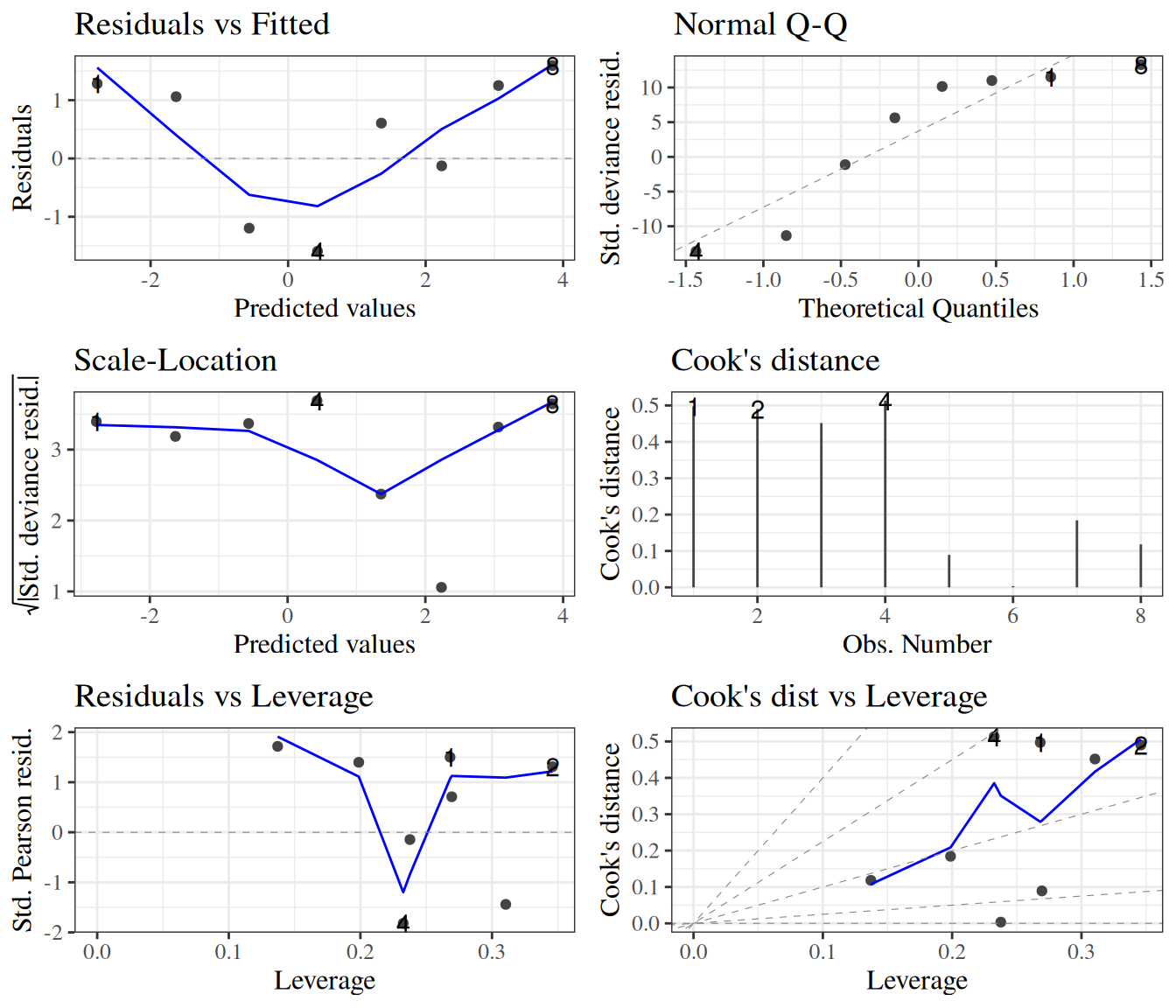
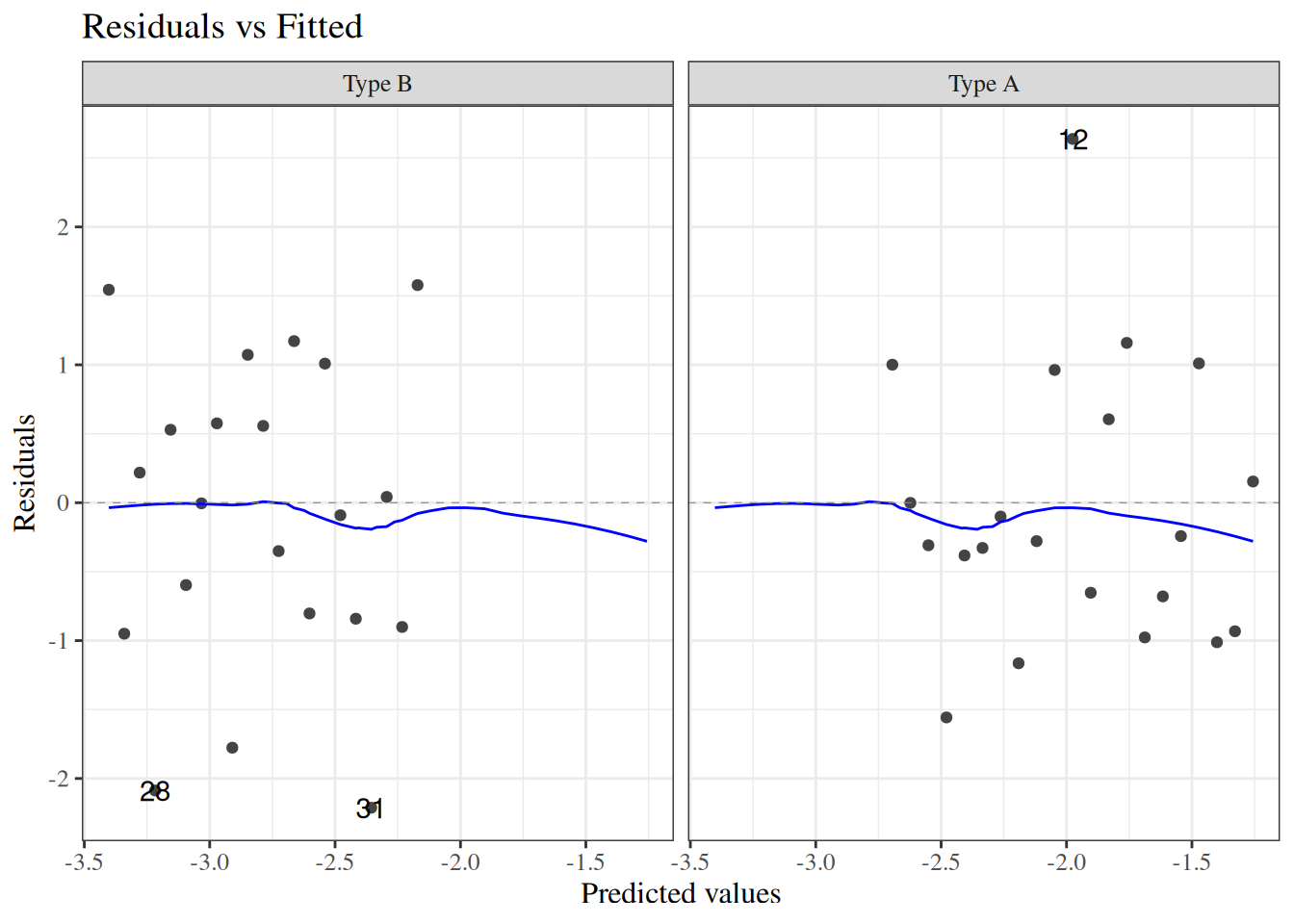
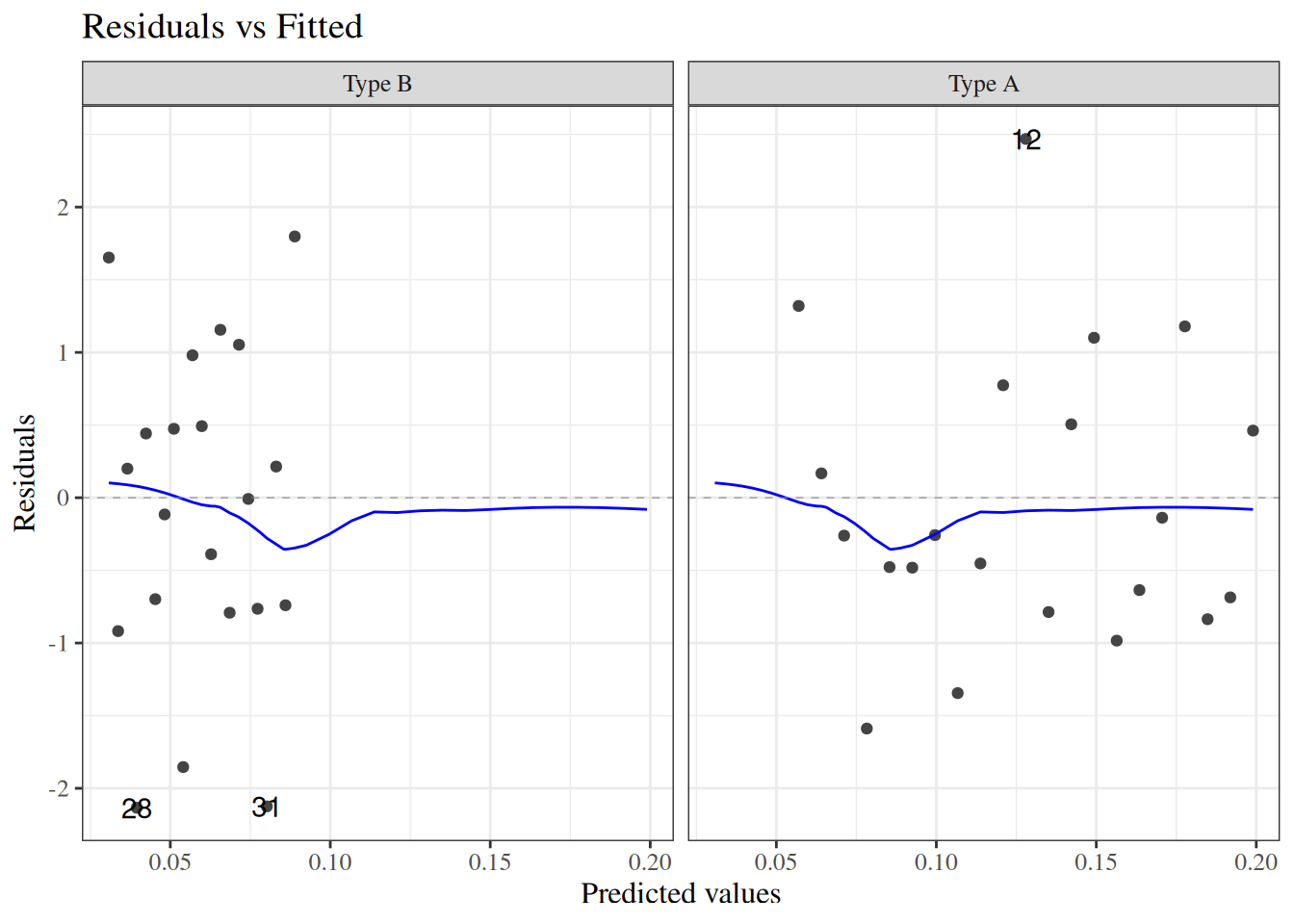
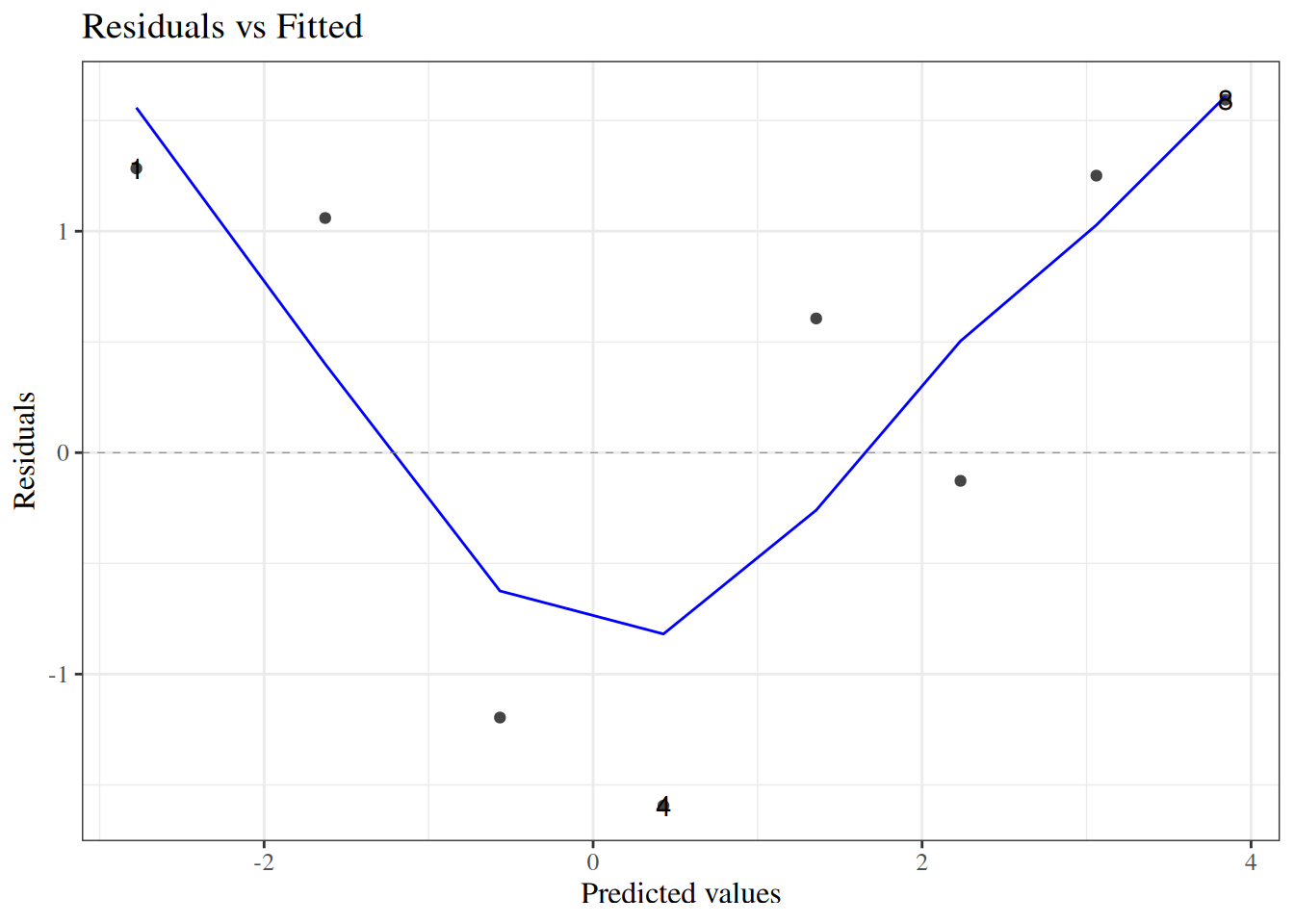
wcgs_response_resid_plot |>print()
Figure 23: residuals plot for wcgs model
We can see a slight fan-shape here: observations on the right have larger variance (as expected since \(var(\bar y) = \pi(1-\pi)/n\) is maximized when \(\pi = 0.5\)).
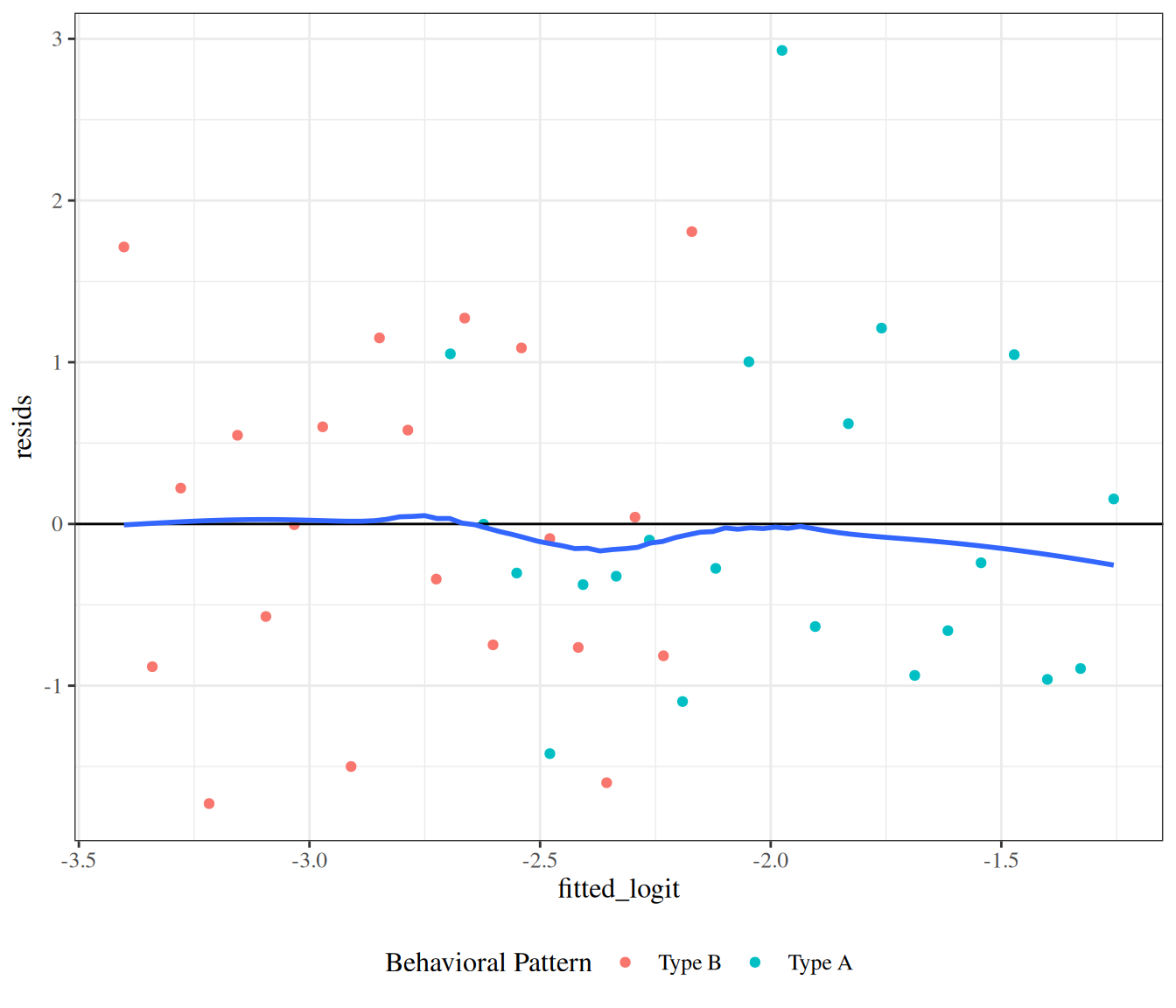
Pearson residuals
The fan-shape in the response residuals plot isn’t necessarily a concern here, since we haven’t made an assumption of constant residual variance, as we did for linear regression.
However, we might want to divide by the standard error in order to make the graph easier to interpret. Here’s one way to do that:
The Pearson (chi-squared) residual for covariate pattern \(k\) is: \[
\begin{aligned}
X_k &= \frac{\bar y_k - \hat\pi_k}{\sqrt{\hat \pi_k (1-\hat\pi_k)/n_k}}
\end{aligned}
\]
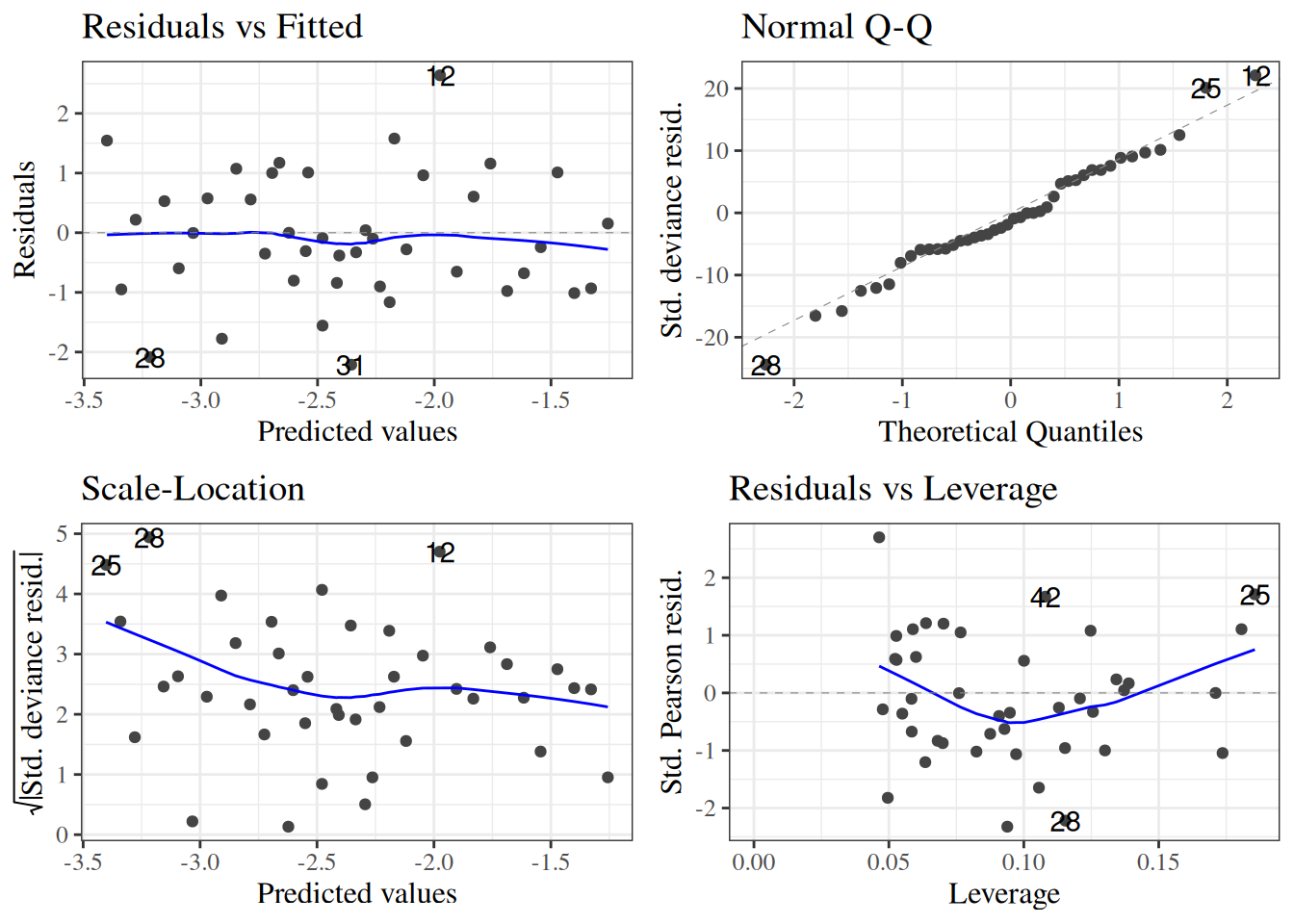
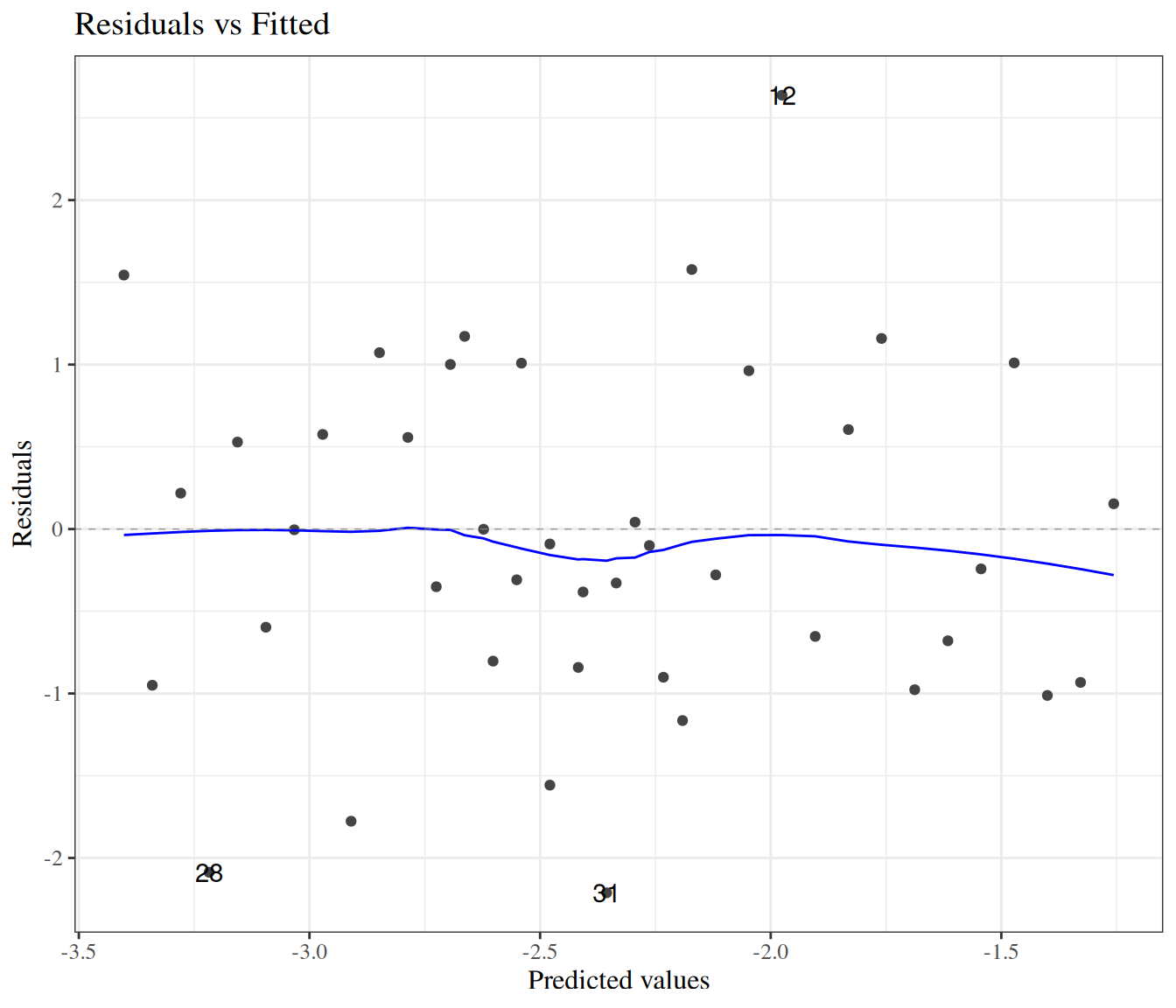
For our CHD model, the p-value for this test is 0.265236; no significant evidence of a lack of fit at the 0.05 level.
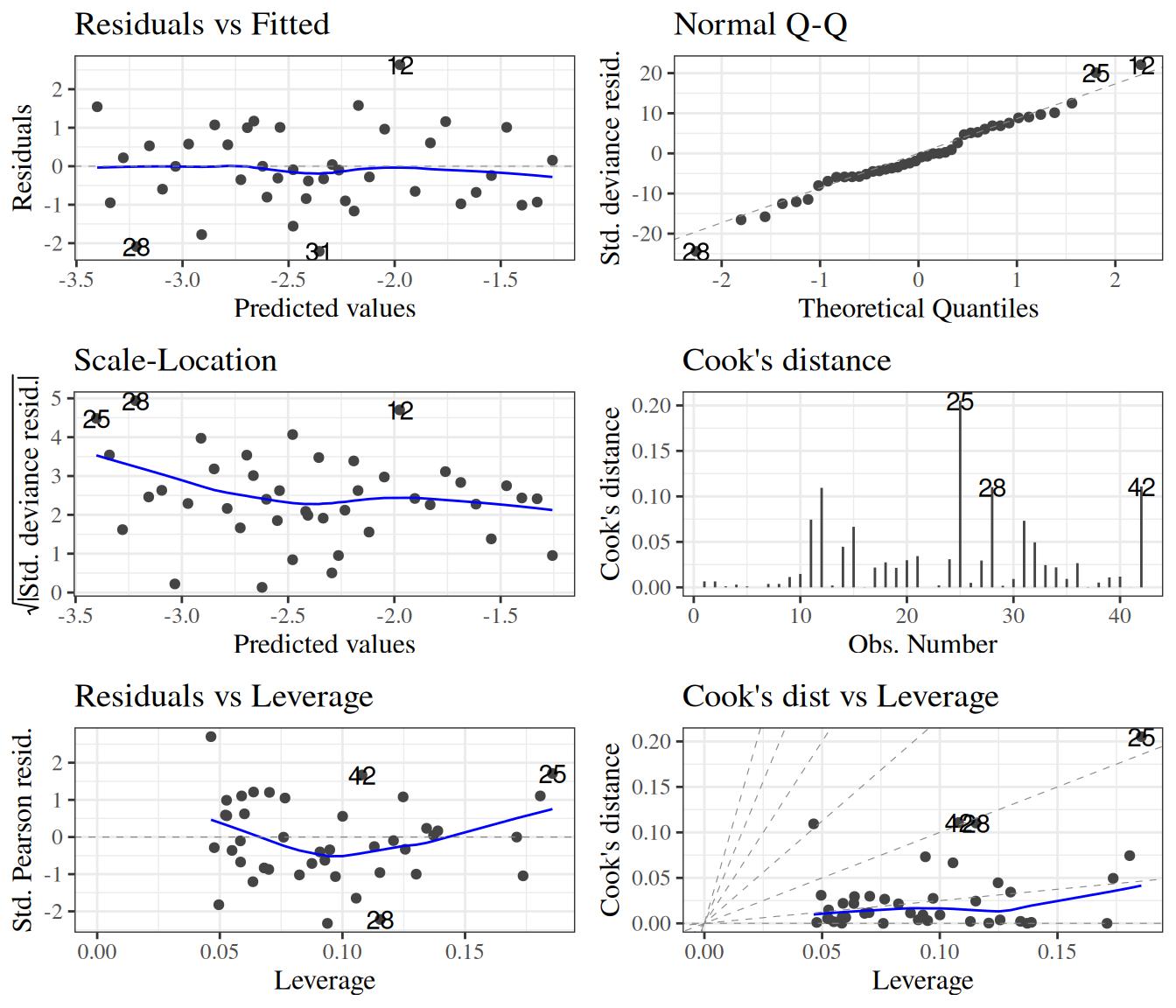
Standardized Pearson residuals
Especially for small data sets, we might want to adjust our residuals for leverage (since outliers in \(X\) add extra variance to the residuals):
\[r_{P_k} = \frac{X_k}{\sqrt{1-h_k}}\]
where \(h_k\) is the leverage of \(X_k\). The functions autoplot() and plot.lm() use these for some of their graphs.
Deviance residuals
For large sample sizes, the Pearson and deviance residuals will be approximately the same. For small sample sizes, the deviance residuals from covariate patterns with small sample sizes can be unreliable (high variance).
As we saw in Figure 3, the odds ratio is not very closely correlated with the risk difference, and the risk difference is typically the metric that ultimately matters for policy decisions.
In other words, for a model with an identity link function, if covariates \(X\) and \(C\) are independent, then the slope with respect to \(X\) doesn’t depend on whether \(C\) is included in the model (and an analogous result holds if \(X\) is discrete or categorical).
Exercise 48 What are the expressions for \(\text{E}{\left[Y|X=x\right]}\) and \(\frac{\partial}{\partial x} \text{E}{\left[Y|X=x\right]}\) for the model above, if \(\text{E}{\left[C|X=x\right]} = \gamma_0 + \gamma_x x\)?
Solution 41. Left to the reader.
Exercise 49 What are the expressions for \(\text{E}{\left[Y|X=x\right]}\) and \(\frac{\partial}{\partial x} \text{E}{\left[Y|X=x\right]}\), if instead of the model above, \[\pi(x,c) = \eta_0 + \beta_Xx + \beta_Cc +\beta_{XC}xc\] and \(\text{E}{\left[C|X=x\right]} = \gamma_0 + \gamma_x x\)?
Solution 42. Left to the reader.
Hint: does adding the interaction term change the functional form of \(\text{E}{\left[Y|X=x\right]}\)?
Deriving risk ratios and risk differences from logistic regression models
If you want to report risk differences or risk ratios instead of odds ratios, you can obtain estimates from logistic regression models, as long as you didn’t stratify sampling by the outcome; in other words, not in case-control studies (see Section 1.3.3.4).
To compute risk ratios from logistic regression models:
Apply the expit function to the linear predictor for each covariate pattern to compute the (estimated) risks,
Then take the differences or ratios of the risks, as needed.
To quantify uncertainty for risk difference or risk ratio estimates derived from logistic regression models (e.g., to calculate SEs, CIs, and p-values), you will need to use the bootstrap, the multivariate delta method, or some other special technique.
When I try to use link ="log" in practice, I often get errors about not finding good starting values for the estimation procedure. This is likely because the model is producing fitted probabilities greater than 1.
When this happens, you can try to fit Poisson regression models instead (we will see those soon!). But then the outcome distribution isn’t quite right, and you won’t get warnings about fitted probabilities greater than 1. In my opinion, the Poisson model for binary outcomes is confusing and not very appealing.
Lee, James. 1994. “Odds Ratio or Relative Risk for Cross-Sectional Data?”International Journal of Epidemiology (England) 23 (1): 201–3. https://doi.org/10.1093/ije/23.1.201.
Lumley, Thomas. 2010. Complex Surveys : A Guide to Analysis Using R. Wiley Series in Survey Methodology. John Wiley. https://doi.org/10.1002/9780470580066.
Norton, Edward C., Bryan E. Dowd, Melissa M. Garrido, and Matthew L. Maciejewski. 2024. “Requiem for Odds Ratios.”Health Services Research 59 (4): e14337. https://doi.org/https://doi.org/10.1111/1475-6773.14337.
Rosenman, Ray H, Richard J Brand, C David Jenkins, Meyer Friedman, Reuben Straus, and Moses Wurm. 1975. “Coronary Heart Disease in the Western Collaborative Group Study: Final Follow-up Experience of 8 1/2 Years.”JAMA 233 (8): 872–77. https://doi.org/10.1001/jama.1975.03260080034016.
Sackett, David L, Jonathan J Deeks, and Doughs G Altman. 1996. “Down with Odds Ratios!”BMJ Evidence-Based Medicine 1 (6): 164.
Vittinghoff, Eric, David V Glidden, Stephen C Shiboski, and Charles E McCulloch. 2012. Regression Methods in Biostatistics: Linear, Logistic, Survival, and Repeated Measures Models. 2nd ed. Springer. https://doi.org/10.1007/978-1-4614-1353-0.