Functions from these packages will be used throughout this document:
[R code]
library(conflicted) # check for conflicting function definitions# library(printr) # inserts help-file output into markdown outputlibrary(rmarkdown) # Convert R Markdown documents into a variety of formats.library(pander) # format tables for markdownlibrary(ggplot2) # graphicslibrary(ggfortify) # help with graphicslibrary(dplyr) # manipulate datalibrary(tibble) # `tibble`s extend `data.frame`slibrary(magrittr) # `%>%` and other additional piping toolslibrary(haven) # import Stata fileslibrary(knitr) # format R output for markdownlibrary(tidyr) # Tools to help to create tidy datalibrary(plotly) # interactive graphicslibrary(dobson) # datasets from Dobson and Barnett 2018library(parameters) # format model output tables for markdownlibrary(haven) # import Stata fileslibrary(latex2exp) # use LaTeX in R code (for figures and tables)library(fs) # filesystem path manipulationslibrary(survival) # survival analysislibrary(survminer) # survival analysis graphicslibrary(KMsurv) # datasets from Klein and Moeschbergerlibrary(parameters) # format model output tables forlibrary(webshot2) # convert interactive content to static for pdflibrary(forcats) # functions for categorical variables ("factors")library(stringr) # functions for dealing with stringslibrary(lubridate) # functions for dealing with dates and times
Here are some R settings I use in this document:
[R code]
rm(list =ls()) # delete any data that's already loaded into Rconflicts_prefer(dplyr::filter)ggplot2::theme_set( ggplot2::theme_bw() +# ggplot2::labs(col = "") + ggplot2::theme(legend.position ="bottom",text = ggplot2::element_text(size =12, family ="serif")))knitr::opts_chunk$set(message =FALSE)options('digits'=6)panderOptions("big.mark", ",")pander::panderOptions("table.emphasize.rownames", FALSE)pander::panderOptions("table.split.table", Inf)conflicts_prefer(dplyr::filter) # use the `filter()` function from dplyr() by defaultlegend_text_size =9run_graphs =TRUE
Therefore, according to this model, differences of \(\delta\) in covariate \(x_j\) correspond to rate ratios of \(\text{exp}{\left\{\beta_j \cdot \delta\right\}}\).
That is, letting \(\tilde{X}_{-j}\) denote vector \(\tilde{X}\) with element \(j\) removed:
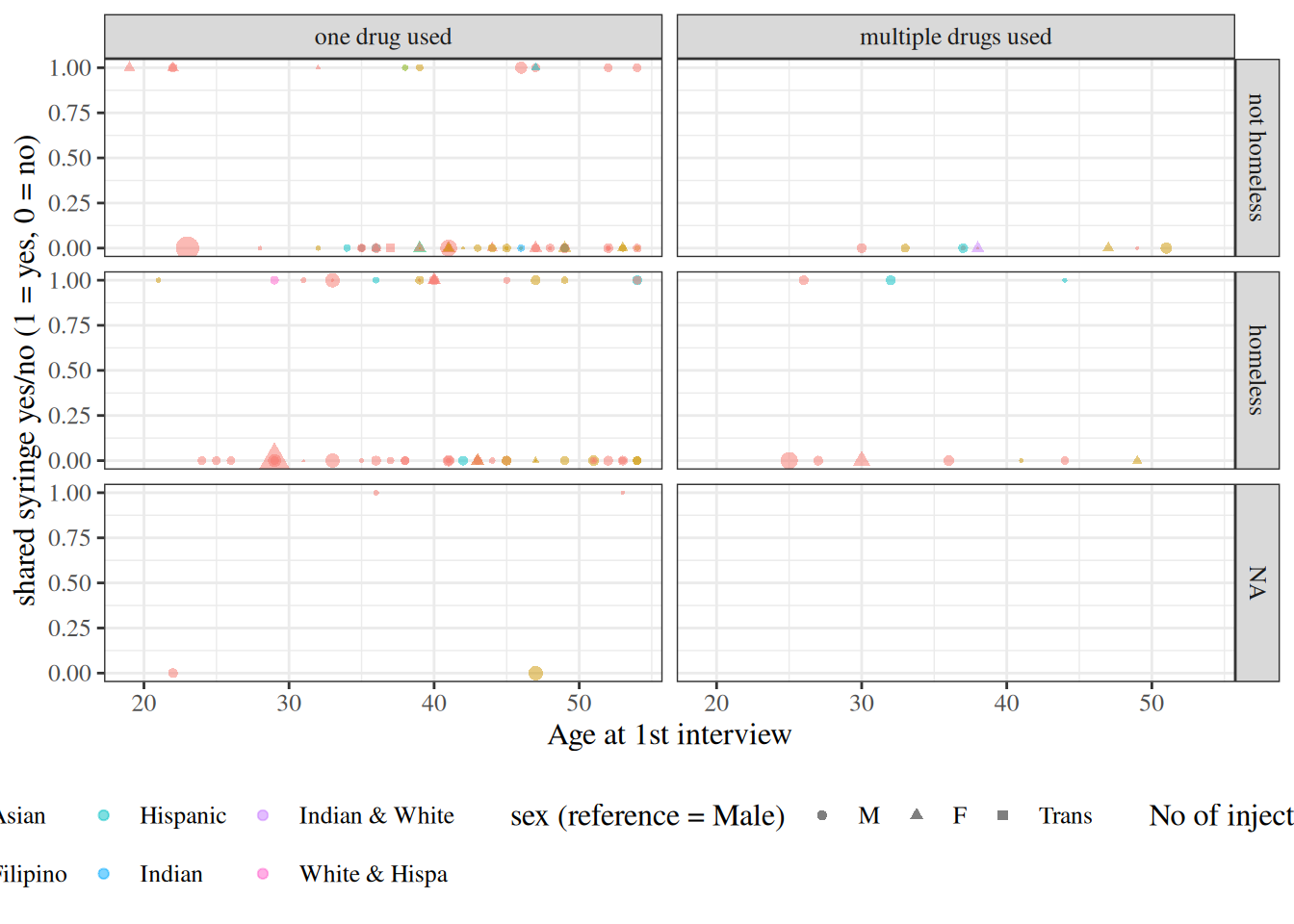
Table 3: Counts of observations in needles dataset by sex, unhoused status, and multiple drug use
[R code]
needles |> dplyr::select(sex, homeless, polydrug) |>summary()#> sex homeless polydrug #> M :97 not homeless:63 one drug used :109 #> F :30 homeless :61 multiple drugs used: 19 #> Trans: 1 NA's : 4
There’s only one individual with sex = Trans, which unfortunately isn’t enough data to analyze. We will remove that individual:
remove singleton observation with sex == Trans
needles = needles |>filter(sex !="Trans")
Model
[R code]
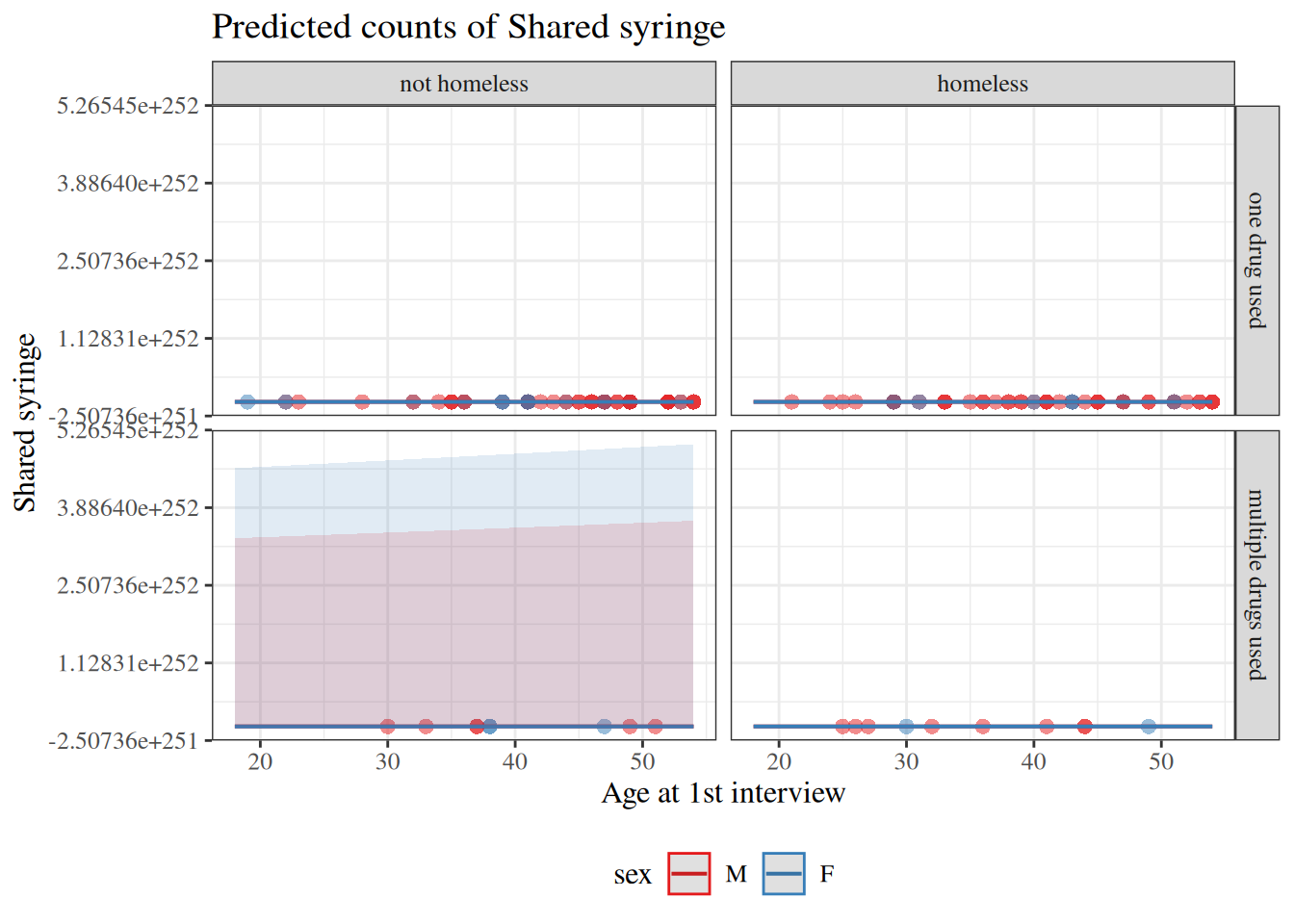
glm1 = needles |> dplyr::filter(nivdu >0) |>glm(offset =log(nivdu),family = stats::poisson,formula = shared_syr ~ age + sex + homeless*polydrug )library(equatiomatic)equatiomatic::extract_eq(glm1)
According to this model, if \(Z=1\), then \(Y\) will always be zero, regardless of \(X\) and \(T\):
\[P(Y=0|Z=1,X=x,T=t) = 1\]
Otherwise (if \(Z=0\)), \(Y\) will have a Poisson distribution, conditional on \(X\) and \(T\), as above.
Even though we never observe \(Z\), we can estimate the parameters \(\gamma_0\)-\(\gamma_p\), via maximum likelihood:
\[
\begin{aligned}
\text{P}(Y=y|X=x,T=t) &= \text{P}(Y=y,Z=1|...) + \text{P}(Y=y,Z=0|...)
\end{aligned}
\] (by the Law of Total Probability)
where \[
\begin{aligned}
P(Y=y,Z=z|...)
&= P(Y=y|Z=z,...)P(Z=z|...)
\end{aligned}
\]
Exercise 4 Expand \(P(Y=0|X=x,T=t)\), \(P(Y=1|X=x,T=t)\) and \(P(Y=y|X=x,T=t)\) into expressions involving \(P(Z=1|X=x,T=t)\) and \(P(Y=y|Z=0,X=x,T=t)\).
Exercise 5 Derive the expected value and variance of \(Y\), conditional on \(X\) and \(T\), as functions of \(P(Z=1|X=x,T=t)\) and \(\text{E}[Y|Z=0,X=x,T=t]\).
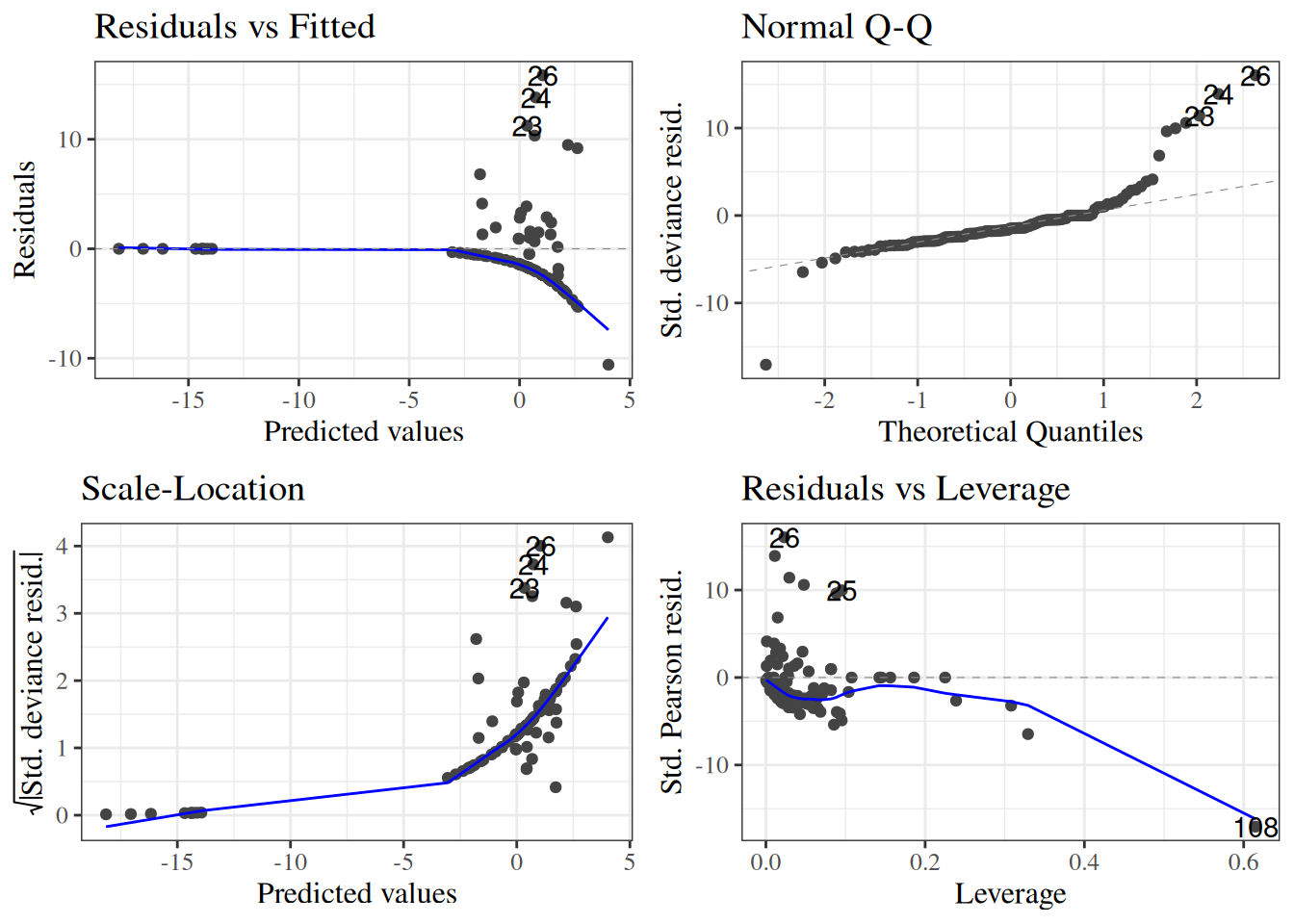
8 Over-dispersion
Definition 1 (Overdispersion) A random variable \(X\) is overdispersed relative to a model \(\text{p}(X=x)\) if if its empirical variance in a dataset is larger than the value is predicted by the fitted model \(\hat{\text{p}}(X=x)\).
Note
Logistic regression is named after the (inverse) link function. Poisson regression is named after the outcome distribution. I think this naming convention reflects the strongest (most questionable assumption) in the model. In binary data regression, the outcome distribution essentially must be Bernoulli (or Binomial), but the link function could be logit, log, identity, probit, or something more unusual. In count data regression, the outcome distribution could have many different shapes, but the link function will probably end up being log, so that covariates have multiplicative effects on the rate.
8.1 Negative binomial models
Example: needle-sharing
[R code]
library(MASS) #need this for glm.nb()glm1.nb =glm.nb(data = needles, shared_syr ~ age + sex + homeless*polydrug)equatiomatic::extract_eq(glm1.nb)
Table 6: Negative binomial model for needle-sharing data
[R code]
summary(glm1.nb)#> #> Call:#> glm.nb(formula = shared_syr ~ age + sex + homeless * polydrug, #> data = needles, init.theta = 0.08436295825, link = log)#> #> Coefficients:#> Estimate Std. Error z value#> (Intercept) 9.91e-01 1.71e+00 0.58#> age -2.76e-02 3.82e-02 -0.72#> sexF 1.06e+00 8.07e-01 1.32#> homelesshomeless 1.65e+00 7.22e-01 2.29#> polydrugmultiple drugs used -2.46e+01 3.61e+04 0.00#> homelesshomeless:polydrugmultiple drugs used 2.32e+01 3.61e+04 0.00#> Pr(>|z|) #> (Intercept) 0.563 #> age 0.469 #> sexF 0.187 #> homelesshomeless 0.022 *#> polydrugmultiple drugs used 0.999 #> homelesshomeless:polydrugmultiple drugs used 0.999 #> ---#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#> #> (Dispersion parameter for Negative Binomial(0.0844) family taken to be 1)#> #> Null deviance: 69.193 on 119 degrees of freedom#> Residual deviance: 57.782 on 114 degrees of freedom#> (7 observations deleted due to missingness)#> AIC: 315.5#> #> Number of Fisher Scoring iterations: 1#> #> #> Theta: 0.0844 #> Std. Err.: 0.0197 #> #> 2 x log-likelihood: -301.5060
[R code]
tibble(name =names(coef(glm1)), poisson =coef(glm1), nb =coef(glm1.nb))
Table 7: Poisson versus Negative Binomial Regression coefficient estimates
zero-inflation
[R code]
library(glmmTMB)zinf_fit1 =glmmTMB(family ="poisson",data = needles,formula = shared_syr ~ age + sex + homeless*polydrug,ziformula =~ age + sex + homeless + polydrug # fit won't converge with interaction)zinf_fit1 |>parameters(exponentiate =TRUE) |>print_md()
An alternative to Negative binomial is the “quasipoisson” distribution. I’ve never used it, but it seems to be a method-of-moments type approach rather than maximum likelihood. It models the variance as \(\text{Var}{\left(Y\right)} = \mu\theta\), and estimates \(\theta\) accordingly.
Dobson, Annette J, and Adrian G Barnett. 2018. An Introduction to Generalized Linear Models. 4th ed. CRC press. https://doi.org/10.1201/9781315182780.
Vittinghoff, Eric, David V Glidden, Stephen C Shiboski, and Charles E McCulloch. 2012. Regression Methods in Biostatistics: Linear, Logistic, Survival, and Repeated Measures Models. 2nd ed. Springer. https://doi.org/10.1007/978-1-4614-1353-0.
Zeileis, Achim, Christian Kleiber, and Simon Jackman. 2008. “Regression Models for Count Data in R.”Journal of Statistical Software 27 (8). https://www.jstatsoft.org/v27/i08/.