Functions from these packages will be used throughout this document:
[R code]
library(conflicted) # check for conflicting function definitions# library(printr) # inserts help-file output into markdown outputlibrary(rmarkdown) # Convert R Markdown documents into a variety of formats.library(pander) # format tables for markdownlibrary(ggplot2) # graphicslibrary(ggfortify) # help with graphicslibrary(dplyr) # manipulate datalibrary(tibble) # `tibble`s extend `data.frame`slibrary(magrittr) # `%>%` and other additional piping toolslibrary(haven) # import Stata fileslibrary(knitr) # format R output for markdownlibrary(tidyr) # Tools to help to create tidy datalibrary(plotly) # interactive graphicslibrary(dobson) # datasets from Dobson and Barnett 2018library(parameters) # format model output tables for markdownlibrary(haven) # import Stata fileslibrary(latex2exp) # use LaTeX in R code (for figures and tables)library(fs) # filesystem path manipulationslibrary(survival) # survival analysislibrary(survminer) # survival analysis graphicslibrary(KMsurv) # datasets from Klein and Moeschbergerlibrary(parameters) # format model output tables forlibrary(webshot2) # convert interactive content to static for pdflibrary(forcats) # functions for categorical variables ("factors")library(stringr) # functions for dealing with stringslibrary(lubridate) # functions for dealing with dates and timeslibrary(broom) # Summarizes key information about statistical objects in tidy tibbleslibrary(broom.helpers) # Provides suite of functions to work with regression model 'broom::tidy()' tibbles
Here are some R settings I use in this document:
[R code]
rm(list =ls()) # delete any data that's already loaded into Rconflicts_prefer(dplyr::filter)ggplot2::theme_set( ggplot2::theme_bw() +# ggplot2::labs(col = "") + ggplot2::theme(legend.position ="bottom",text = ggplot2::element_text(size =12, family ="serif")))knitr::opts_chunk$set(message =FALSE)options('digits'=6)panderOptions("big.mark", ",")pander::panderOptions("table.emphasize.rownames", FALSE)pander::panderOptions("table.split.table", Inf)conflicts_prefer(dplyr::filter) # use the `filter()` function from dplyr() by defaultlegend_text_size =9run_graphs =TRUE
Most of the content in this chapter should be review from UC Davis Epi 202.
1 Core properties of probabilities
1.1 Defining probabilities
Definition 1 (Probability measure) A probability measure, often denoted \(\Pr()\) or \(\operatorname{P}()\), is a function whose domain is a \(\sigma\)-algebra of possible outcomes, \(\mathscr{S}\), and which satisfies the following properties:
For any statistical event \(A \in \mathscr{S}\), \(\Pr(A) \ge 0\).
The probability of the union of all outcomes (\(\Omega \stackrel{\text{def}}{=}\cup \mathscr{S}\)) is 1:
\[\Pr(\Omega) = 1\]
The probability of the union of countably many mutually disjoint events \(A_1, A_2, \ldots\) (where \(A_i \cap A_j = \emptyset\) for all \(i \neq j\)) is equal to the sum of their probabilities (countable additivity or sigma-additivity):
Corollary 2 (Complement rule in probability (\(\pi\)) notation) If the probability of an outcome \(A\) is \(\Pr(A)=\pi\), then the probability that \(A\) does not occur is:
Definition 2 (Conditional probability) For two events \(A\) and \(B\) with \(\Pr(B) > 0\), the conditional probability of \(A\) given \(B\), denoted \(\Pr(A \mid B)\), is:
\[\Pr(A \mid B) \stackrel{\text{def}}{=}\frac{\Pr(A \cap B)}{\Pr(B)}\]
Theorem 3 (Law of conditional probability) For any two events \(A\) and \(B\) with \(\Pr(B) > 0\):
\[
\begin{aligned}
\Pr(A \mid B) &= \frac{\Pr(A \cap B)}{\Pr(B)}
\\ \Pr(A \cap B) &= \Pr(A \mid B) \cdot\Pr(B)
\end{aligned}
\]
Example 1 (Applying the law of conditional probability) Suppose 30% of adults exercise regularly (\(\Pr(E) = 0.30\)), and among adults who exercise regularly, 60% have low blood pressure (\(\Pr(L \mid E) = 0.60\)).
Then the probability that a randomly selected adult both exercises regularly and has low blood pressure is:
Theorem 4 (Law of total probability) If \(B_1, B_2, \ldots\) is a countable partition of the sample space (i.e., countably many mutually exclusive events whose union is the entire sample space), then for any event \(A\):
Proof. Since \(B_1, B_2, \ldots\) partition the sample space, the events \(A \cap B_1, A \cap B_2, \ldots\) are mutually exclusive and their union is \(A\). By property 3 of Definition 1 (countable additivity), and then by Theorem 3:
Theorem 5 (Bayes’ theorem) For any two events \(A\) and \(B\) with \(\Pr(A) > 0\) and \(\Pr(B) > 0\):
\[\Pr(A \mid B) = \frac{\Pr(B \mid A) \cdot\Pr(A)}{\Pr(B)}\]
Proof. Apply Definition 2 to both \(\Pr(A \mid B)\) and \(\Pr(B \mid A)\):
\[
\begin{aligned}
\Pr(A \mid B)
&= \frac{\Pr(A \cap B)}{\Pr(B)}
\\&= \frac{\Pr(B \mid A) \cdot\Pr(A)}{\Pr(B)}
\end{aligned}
\]
The second equality follows from Theorem 3 applied to \(\Pr(B \cap A) = \Pr(B \mid A) \cdot\Pr(A)\).
Example 2 (Positive predictive value of a medical test) Suppose a disease test has 99% sensitivity and 99% specificity, and the prevalence of the disease in the population is 7%.
Let \(D\) be the event “person has the disease” and \(+\) be the event “test is positive”. Then:
\(\Pr(+ \mid D) = 0.99\) (sensitivity)
\(\Pr(\neg + \mid \neg D) = 0.99\) (specificity), so the false positive rate is \(\Pr(+ \mid \neg D) = 1 - 0.99 = 0.01\)
\(\Pr(D) = 0.07\) (prevalence)
By Bayes’ theorem (Theorem 5) and the law of total probability (Theorem 4):
Even with a highly accurate test (99% sensitive and 99% specific), only about 88% of people who test positive actually have the disease, because the disease prevalence is relatively low (7%).
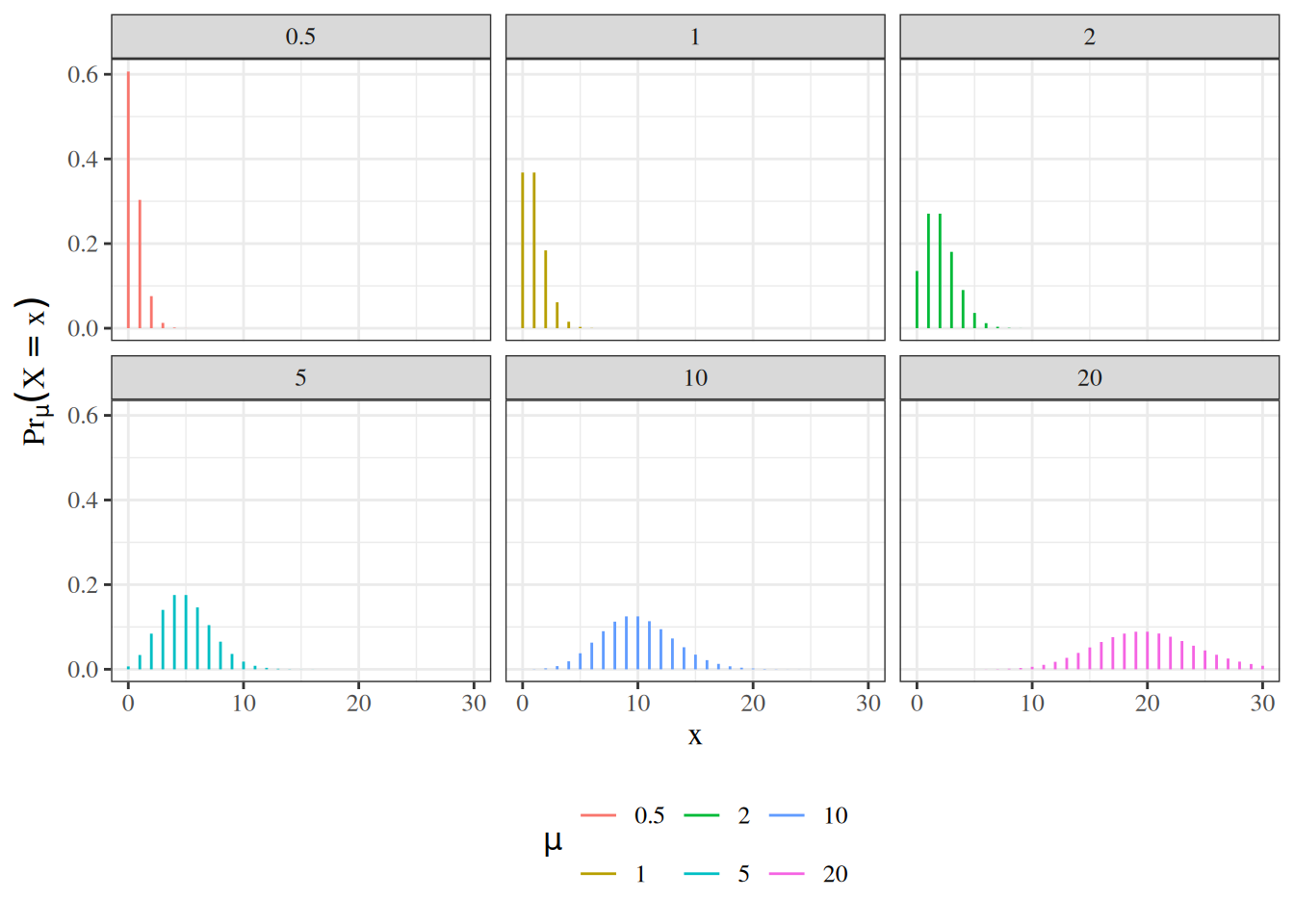
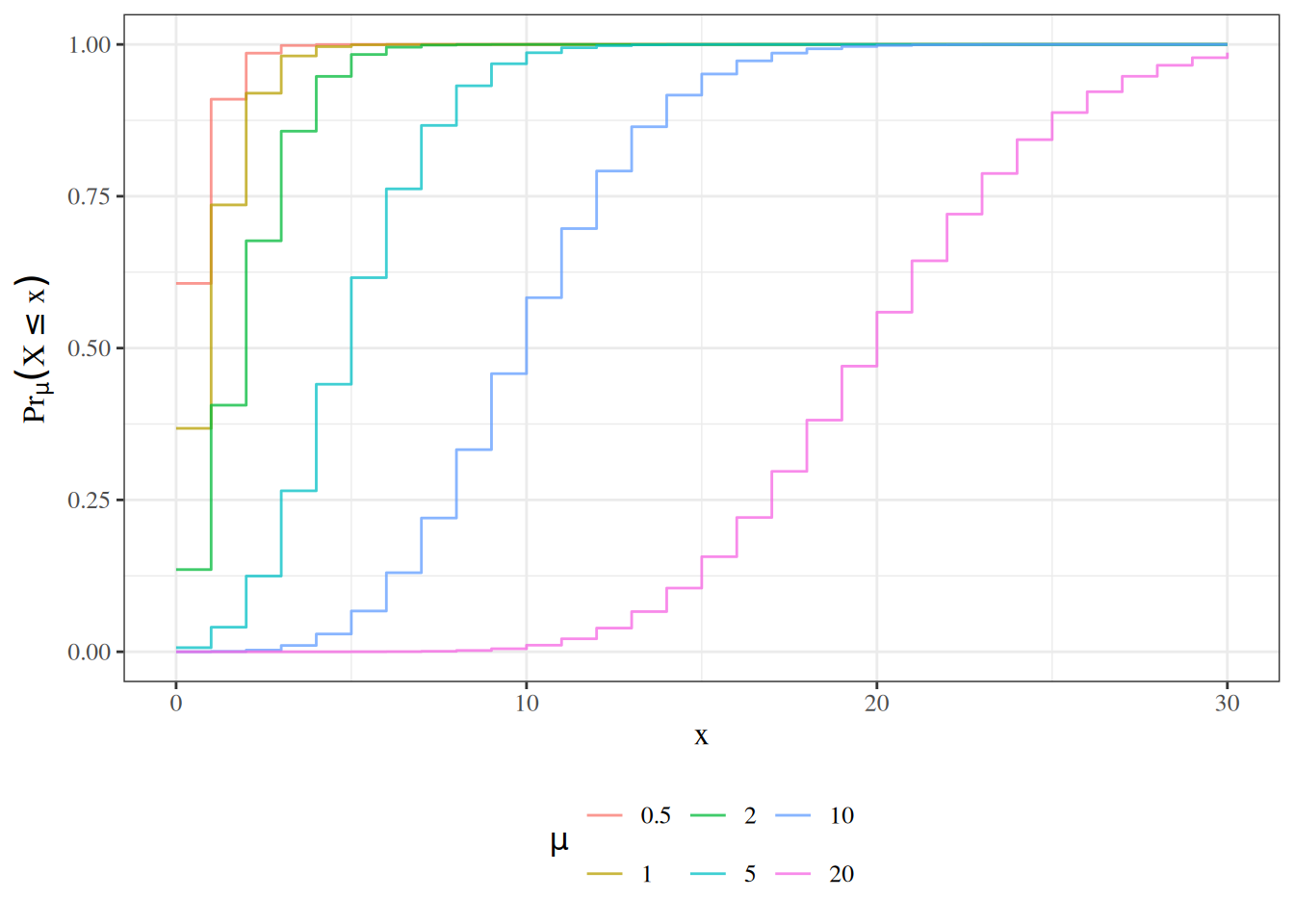
2 Key probability distributions
Table 1: Distributions typically used for outcome models
Distribution
Uses
Bernoulli
Binary outcomes
Binomial
Sums of Bernoulli outcomes
Poisson
unbounded count outcomes
Geometric
Counts of non-events before an event occurs
Negative binomal
Mixtures of Poisson distributions, counts of non-events until a given number of events occurs
Normal (Gaussian)
Continuous outcomes without a more specific distribution
exponential
Time to event outcomes
Gamma
Time to event outcomes
Weibull
Time to event outcomes
Log-normal
Time to event outcomes
Table 2: Distributions typically used for test statistics
Definition 5 (Exposure magnitude) For many count outcomes, there is some sense of an exposure magnitude, such as population size, or duration of observation, which multiplicatively rescales the expected (mean) count.
Exercise 5 What are some examples of exposure magnitudes?
Theorem 8 (Transformation function from event rate to mean) For a count variable with mean \(\mu\), event rate \(\lambda\), and exposure magnitude \(t\):
\[\mu = \lambda \cdot t \tag{4}\]
Solution. Start from definition of event rate and use algebra to solve for \(\mu\).
Equation 4 is analogous to the inverse-odds function for binary variables.
Theorem 9 (No exposure means no expected events) When the exposure magnitude is 0, there is no opportunity for events to occur:
The exposure magnitude, \(T\), is similar to a covariate in linear or logistic regression. However, there is an important difference: in count regression, there is no intercept corresponding to \(\operatorname{E}[Y|T=0]\). In other words, this model assumes that if there is no exposure, there can’t be any events.
Theorem 10 (Exposure is additive on the log scale) If \(\mu = \lambda\cdot t\), then:
\[\log{\mu} = \log{\lambda} + \log{t}\]
Definition 7 (Offset) When the linear component of a model involves a term without an unknown coefficient, that term is called an offset.
Theorem 11 (Sum of independent Poisson random variables) If \(X\) and \(Y\) are independent Poisson random variables with means \(\mu_X\) and \(\mu_Y\), their sum, \(Z=X+Y\), is also a Poisson random variable, with mean \(\mu_Z = \mu_X + \mu_Y\).
When \(\alpha=1\) this is the exponential. When \(\alpha>1\) the hazard is increasing and when \(\alpha < 1\) the hazard is decreasing. This provides more flexibility than the exponential.
We will see more of this distribution later.
3 Characteristics of probability distributions
3.1 Probability density function
Definition 9 (probability density) If \(X\) is a continuous random variable, then the probability density of \(X\) at value \(x\), denoted \(f(x)\), \(f_X(x)\), \(\operatorname{p}(x)\), \(\operatorname{p}_X(x)\), or \(\operatorname{p}(X=x)\), is defined as the limit of the probability (mass) that \(X\) is in an interval around \(x\), divided by the width of that interval, as that width reduces to 0.
Definition 10 (Cumulative distribution function (CDF)) For a random variable \(X\), its population CDF is \[F(t)=\Pr(X\le t), \quad t\in\mathbb{R}.\]
Definition 11 (Quantile function (population inverse CDF)) For a random variable \(X\) with cumulative distribution function (CDF)\(F\), its population quantile function (generalized inverse of \(F\)) is \[Q(p)=\inf\{t:F(t)\ge p\}, \quad 0<p\le 1.\]
Theorem 13 (Density function is derivative of CDF) The density function \(f(t)\) or \(\operatorname{p}(T=t)\) for a random variable \(T\) at value \(t\) is equal to the derivative of the cumulative probability function \(F(t) \stackrel{\text{def}}{=}P(T\le t)\); that is:
Definition 13 (Expectation, expected value, population mean ) The expectation, expected value, or population mean of a continuous random variable \(X\), denoted \(\operatorname{E}\mathopen{}\left[X\right]\mathclose{}\), \(\mu(X)\), or \(\mu_X\), is the weighted mean of \(X\)’s possible values, weighted by the probability density function of those values:
\[\operatorname{E}\mathopen{}\left[X\right]\mathclose{} = \int_{x\in \mathcal{R}(X)} x \cdot \operatorname{p}(X=x)dx\]
The expectation, expected value, or population mean of a discrete random variable \(X\), denoted \(\operatorname{E}\mathopen{}\left[X\right]\mathclose{}\), \(\mu(X)\), or \(\mu_X\), is the mean of \(X\)’s possible values, weighted by the probability mass function of those values:
\[\operatorname{E}\mathopen{}\left[X\right]\mathclose{} = \sum_{x \in \mathcal{R}(X)} x \cdot \operatorname{P}(X=x)\]
Proof. We prove the continuous case, in which \(T\) has a density \(\operatorname{f}\). The result follows from applying Tonelli’s theorem (hypothesis (a) of Fubini–Tonelli) to the function \(g(t, u) = \operatorname{f}(u) \cdot \mathbb{1}\mathopen{}\left(0 \le t \le u\right)\mathclose{}\) on the product space \([0, \infty) \times [0, \infty)\): \(g\) is nonnegative everywhere and vanishes outside the (unbounded) triangular region \(D = \{(t, u) : 0 \le t \le u < \infty\}\), so the iterated integrals over \(D\) are exchangeable.
Since \(\operatorname{f}(u) \ge 0\), hypothesis (a) of Fubini–Tonelli (the nonnegative case, Tonelli’s theorem) applies, and we may exchange the order of integration over \(D\):
Example 3 (Mean of an exponential random variable via survival function) Let \(T \sim \mathrm{Exponential}(\lambda)\), so \(\operatorname{S}(t) = \text{e}^{-\lambda t}\) for \(t \ge 0\). By Theorem 16:
where the last equality follows by rearranging the double sum, grouping each term \(x\) by its image \(y = g(x)\).
The continuous case is the density-weighted analogue of this argument, but a fully rigorous proof needs the general change-of-variables theorem for integrals against a pushforward measure — approximating \(g\) by simple functions and passing to the limit — which is beyond Epi 204’s scope (Billingsley 1995; Gut 2013; Casella and Berger 2002; Wikipedia contributors 2026).
Example 4 (Expected value of \(X^2\) for a Bernoulli variable) Let \(X \sim \operatorname{Ber}(\pi)\). By LOTUS (Theorem 17, discrete case):
Example 5 (Expected value of \(X^2\) for a Uniform(0,1) variable) Let \(X \sim \text{Uniform}(0,1)\), so \(\operatorname{p}(X=x) = 1\) for \(x \in [0,1]\). By LOTUS (Theorem 17, continuous case):
\[
\begin{aligned}
\operatorname{E}\mathopen{}\left[X^2\right]\mathclose{}
&= \int_0^1 x^2 \cdot\operatorname{p}(X=x)\,dx
&& \text{(LOTUS, continuous case)}
\\&= \int_0^1 x^2 \cdot 1\,dx
&& \text{(}\operatorname{p}(X=x) = 1\text{ on } [0,1]\text{)}
\\&= \mathopen{}\left[\frac{x^3}{3}\right]\mathclose{}_0^1
&& \text{(antiderivative of } x^2\text{)}
\\&= \frac{1}{3}.
&& \text{(evaluate at the bounds)}
\end{aligned}
\]
Conditional distributions and expectations
Definition 14 (Conditional probability mass function) Let \(X\) and \(Y\) be jointly distributed discrete random variables. The conditional probability mass function of \(Y\) given \(X = x\) (for values of \(x\) with \(\operatorname{P}(X = x) > 0\)) is:
\[\operatorname{P}(Y = y \mid X = x) \stackrel{\text{def}}{=}\frac{\operatorname{P}(X = x,\, Y = y)}{\operatorname{P}(X = x)}\]
Example 6 (Conditional PMF from a vaccine trial) The vaccine dataset in the dobson package (Dobson and Barnett (2018), Table 9.6) records the response to treatment in a vaccine trial: \(X\) is treatment group (placebo or vaccine) and \(Y\) is response severity (small, moderate, or large).
The joint PMF of \((X, Y)\) is the table of frequencies divided by the total \(n = 73\) trial participants. The marginal probability \(\operatorname{P}(X = \text{placebo})\) is:
Definition 15 (Conditional probability density function) Let \(X\) and \(Y\) be jointly distributed continuous random variables with joint density \(\operatorname{p}(X = x,\, Y = y)\) and marginal density \(\operatorname{p}(X = x)\). The conditional probability density function of \(Y\) given \(X = x\) (for values of \(x\) with \(\operatorname{p}(X = x) > 0\)) is:
\[\operatorname{p}(Y = y \mid X = x) \stackrel{\text{def}}{=}\frac{\operatorname{p}(X = x,\, Y = y)}{\operatorname{p}(X = x)}\]
Example 7 (Conditional PDF from a bivariate normal model of birthweight data) The birthweight dataset in the dobson package (Dobson and Barnett (2018), Table 2.3) records gestational age (weeks) and birthweight (grams) for 12 boys and 12 girls. Let \(X\) be gestational age and \(Y\) be birthweight, pooling both sexes into \(n = 24\) observations.
Modeling \((X, Y)\) as bivariate normal with parameters set equal to these sample moments, the joint density is (a standard result; e.g. Casella and Berger (2002)):
A further standard fact about the bivariate normal (Casella and Berger (2002)) is that the marginal distribution of \(X\) is \(X \sim \operatorname{N}\mathopen{}\left(\mu_X, \sigma_X^2\right)\mathclose{}\). At \(x = 40\) weeks (a full-term pregnancy), \(\mu_X = 38.5417\) and \(\sigma_X = 1.8173\), so:
By Definition 15, dividing the joint density by this marginal density and simplifying the exponent (completing the square in \(y\); Casella and Berger (2002)) gives the conditional PDF of \(Y\) given \(X = 40\), which is itself normal with mean shifted along the regression line and variance reduced by a factor of \(1-\rho^2\):
The first equality substitutes the joint and marginal densities and combines their prefactors and exponents; the second equality combines the two \((40-\mu_X)^2\) terms using \(1 - \tfrac{1}{1-\rho^2} = \tfrac{-\rho^2}{1-\rho^2}\); the third equality factors \(-\tfrac{1}{2\sigma_Y^2(1-\rho^2)}\) out of the bracket (multiplying through confirms it reproduces the previous line); and the fourth equality completes the square in \(y\), since expanding \(\mathopen{}\left(y - \mathopen{}\left[\mu_Y + \rho\frac{\sigma_Y}{\sigma_X}(40-\mu_X)\right]\mathclose{}\right)\mathclose{}^2\) reproduces exactly the bracketed quadratic in the third equality.
So \(Y \mid X = 40 \sim \operatorname{N}\mathopen{}\left(3136.15,\, 188.37^2\right)\mathclose{}\): the conditional mean, 3136.15 g, is exactly the fitted regression line’s prediction at \(x=40\) (\(-1484.9846 + 115.5283 \times 40 = 3136.15\)), matching R’s lm(wt ~ ga) fit directly:
[R code]
pander::pander(coef(lm(wt ~ ga)))
(Intercept)
ga
-1,485
115.5
Definition 16 (Conditional expectation)Discrete case. Let \(X\) and \(Y\) be jointly distributed discrete random variables. The conditional expectation of \(Y\) given \(X = x\), using Definition 14, is:
\[\operatorname{E}\mathopen{}\left[Y \mid X = x\right]\mathclose{} \stackrel{\text{def}}{=}\sum_{y \in \mathcal{R}(Y)} y \cdot\operatorname{P}(Y = y \mid X = x)\]
Continuous case. Let \(X\) and \(Y\) be jointly distributed continuous random variables. The conditional expectation of \(Y\) given \(X = x\), using Definition 15, is:
\[\operatorname{E}\mathopen{}\left[Y \mid X = x\right]\mathclose{} \stackrel{\text{def}}{=}\int_{y \in \mathcal{R}(Y)} y \cdot\operatorname{p}(Y = y \mid X = x)\, dy\]
Example 8 (Conditional expectation from real trial and birthweight data)Discrete case. Continuing Example 6, score the vaccine trial’s response levels \(\text{small} = 1\), \(\text{moderate} = 2\), \(\text{large} = 3\). The conditional PMF of \(Y\) given \(X = \text{placebo}\) (from Example 6) is:
Continuous case. Continuing Example 7, \(Y \mid X = 40 \sim \operatorname{N}\mathopen{}\left(3136.15,\, 188.37^2\right)\mathclose{}\). Since the mean of a normal random variable is its own location parameter, integrating \(y\) against this conditional density directly gives:
\[
\begin{aligned}
\operatorname{E}\mathopen{}\left[Y \mid X = 40\right]\mathclose{}
&= \int_{-\infty}^{\infty} y \cdot\operatorname{p}(Y=y \mid X=40)\,dy
\\&= 3136.15 \text{ g}
\end{aligned}
\]
matching the fitted regression line’s prediction at \(x=40\) weeks exactly, as expected since the conditional mean of a bivariate normal is the linear regression of \(Y\) on \(X\).
Definition 17 (Conditional expectation: mixed case) Suppose exactly one of \(X, Y\) is discrete and the other is continuous. Write \(\operatorname{p}(X = x,\, Y = y)\) for their joint density-mass function: a probability density in the continuous variable and a probability mass in the discrete variable.
\(X\) discrete, \(Y\) continuous. Here \(\operatorname{p}(X=x,\,Y=y)\) is, for each fixed \(x\), a probability density in \(y\), scaled so that \(\int_{y} \operatorname{p}(X=x,\,Y=y)\,dy = \operatorname{P}(X=x)\). The conditional PDF of \(Y\) given \(X = x\) (for values of \(x\) with \(\operatorname{P}(X = x) > 0\)) is:
\[\operatorname{p}(Y = y \mid X = x) \stackrel{\text{def}}{=}\frac{\operatorname{p}(X = x,\, Y = y)}{\operatorname{P}(X = x)}\]
and the conditional expectation of \(Y\) given \(X = x\) is:
\[\operatorname{E}\mathopen{}\left[Y \mid X = x\right]\mathclose{} \stackrel{\text{def}}{=}\int_{y \in \mathcal{R}(Y)} y \cdot\operatorname{p}(Y = y \mid X = x)\, dy\]
\(X\) continuous, \(Y\) discrete. Here \(\operatorname{p}(X=x,\,Y=y)\) is, for each fixed \(y\), a probability density in \(x\), scaled so that \(\sum_{y} \operatorname{p}(X=x,\,Y=y) = \operatorname{p}(X=x)\). The conditional PMF of \(Y\) given \(X = x\) (for values of \(x\) with \(\operatorname{p}(X = x) > 0\)) is:
\[\operatorname{P}(Y = y \mid X = x) \stackrel{\text{def}}{=}\frac{\operatorname{p}(X = x,\, Y = y)}{\operatorname{p}(X = x)}\]
and the conditional expectation of \(Y\) given \(X = x\) is:
\[\operatorname{E}\mathopen{}\left[Y \mid X = x\right]\mathclose{} \stackrel{\text{def}}{=}\sum_{y \in \mathcal{R}(Y)} y \cdot\operatorname{P}(Y = y \mid X = x)\]
Example 9 (Conditional expectation, one discrete variable and one continuous variable)\(X\) discrete, \(Y\) continuous. The plasma dataset in the dobson package (Dobson and Barnett (2018), Table 6.25) records plasma inorganic phosphate levels (mg/dL) one hour after a glucose tolerance test, for hyperinsulinemic obese (H-O) and control (C) participants. Let \(X\) be group and \(Y\) be phosphate level.
Modeling phosphate as approximately normal within each group, with parameters set equal to each group’s sample mean and SD, and \(\operatorname{P}(X = \text{H-O}) = 11/23\):
\[\operatorname{p}(Y = y \mid X = \text{H-O}) \approx \operatorname{N}\mathopen{}\left(3.95,\, 0.78^2\right)\mathclose{}\]\[\operatorname{p}(Y = y \mid X = \text{C}) \approx \operatorname{N}\mathopen{}\left(2.78,\, 0.41^2\right)\mathclose{}\]
By Definition 17, since the mean of a normal random variable is its own location parameter:
\[\operatorname{E}\mathopen{}\left[Y \mid X = \text{H-O}\right]\mathclose{} = 3.95 \text{ mg/dL}, \qquad
\operatorname{E}\mathopen{}\left[Y \mid X = \text{C}\right]\mathclose{} = 2.78 \text{ mg/dL}\]
\(X\) continuous, \(Y\) discrete. The senility dataset in the dobson package (Dobson and Barnett (2018), Table 7.8) records, for 54 elderly people, a WAIS (Wechsler Adult Intelligence Scale) score and whether symptoms of senility were present. Let \(X\) be WAIS score and \(Y\) indicate senility symptoms.
[R code]
data(senility)senility_fit <-glm(s ~ x, data = senility, family = binomial)b0 <-coef(senility_fit)[["(Intercept)"]]b1 <-coef(senility_fit)[["x"]]pander::pander(coef(senility_fit))
(Intercept)
x
2.404
-0.3235
Modeling \(\operatorname{P}(Y = 1 \mid X = x)\) with the fitted logistic regression:
senility_p10 <-predict(senility_fit,newdata =data.frame(x =10), type ="response")senility_p15 <-predict(senility_fit,newdata =data.frame(x =15), type ="response")
At \(x = 10\): \(\operatorname{E}\mathopen{}\left[Y \mid X=10\right]\mathclose{} = 0.3\). At \(x = 15\): \(\operatorname{E}\mathopen{}\left[Y \mid X=15\right]\mathclose{} = 0.08\) — a lower WAIS score is associated with higher predicted probability of senility symptoms.
Definition 18 (Conditional expectation function) The conditional expectation function\(\operatorname{E}\mathopen{}\left[Y \mid X\right]\mathclose{}\) is the function (and hence random variable) of \(X\) obtained by evaluating \(\operatorname{E}\mathopen{}\left[Y \mid X = x\right]\mathclose{}\) at \(X\); that is, \(\operatorname{E}\mathopen{}\left[Y \mid X\right]\mathclose{} = g(X)\) where \(g(x) \stackrel{\text{def}}{=}\operatorname{E}\mathopen{}\left[Y \mid X = x\right]\mathclose{}\).
Example 10 (The conditional expectation function of the birthweight model) Continuing Example 7 and Example 8, \((X, Y)\) (gestational age, birthweight) is modeled as bivariate normal. The general form of the conditional mean derived in Example 7, evaluated at an arbitrary \(x\) instead of just \(x=40\), gives the conditional expectation function directly:
which is exactly the fitted regression line (the general algebraic identity \(\mu_Y + \rho\frac{\sigma_Y}{\sigma_X}(x-\mu_X) = \mathopen{}\left(\mu_Y - \rho\frac{\sigma_Y}{\sigma_X}\mu_X\right)\mathclose{} + \rho\frac{\sigma_Y}{\sigma_X}x\) is what makes the bivariate-normal conditional mean linear in \(x\)).
As a check, evaluating at \(x = 40\) recovers Example 8’s result:
Solution. Treating \((X, Y)\) as a single discrete random object taking one of the four values \((0,0)\), \((0,1)\), \((1,0)\), \((1,1)\), LOTUS (Theorem 17) applied to \(g(x, y) = x + y\) gives directly:
Figure 4: Joint probability mass function \(\operatorname{P}(X = x, Y = y)\). Marginal totals: \(\operatorname{P}(X = 0) = 0.5\), \(\operatorname{P}(X = 1) = 0.5\), \(\operatorname{P}(Y = 0) = 0.3\), \(\operatorname{P}(Y = 1) = 0.7\).
3.4 Fubini–Tonelli for expectations
The Riemann version of Fubini’s theorem, stated in the math-prereqs chapter, lets us switch the order of integration for continuous integrands on simple regions. For expectations against probability measures we use its measure-theoretic form, which holds on any σ-finite measure space. The σ-finiteness hypothesis is automatic for probability measures (every probability measure is finite, hence σ-finite), so Fubini–Tonelli yields the corollary below directly.
Corollary 3 (Joint-distribution form (without independence; corollary of Fubini–Tonelli)) Let \((X, Y)\) be jointly distributed random variables whose joint distribution has a density \(f_{X,Y}\) with respect to a product of σ-finite reference measures \(\mu_X \otimes \mu_Y\) on \(\mathcal{R}(X) \times \mathcal{R}(Y)\), and let \(h : \mathcal{R}(X) \times \mathcal{R}(Y) \to \mathbb{R}\) be measurable. If either
The choice of reference measures covers three cases:
Both continuous:\(\mu_X = \mu_Y = \text{Lebesgue measure}\); \(f_{X,Y}\) is the joint probability density function (PDF), and \(\int g(x)\,d\mu_X(x) = \int g(x)\,dx\).
Both discrete:\(\mu_X = \mu_Y = \text{counting measure}\); \(f_{X,Y}(x,y) = \operatorname{P}(X = x,\, Y = y)\) is the joint probability mass function (PMF), and \(\int g(x)\,d\mu_X(x) = \sum_{x \in \mathcal{R}(X)} g(x)\).
Mixed (one continuous, one discrete): one reference measure is Lebesgue and the other is counting; \(f_{X,Y}(x,y) = f_{X \mid Y}(x \mid y)\,\operatorname{P}(Y = y)\) (or \(\operatorname{P}(X = x \mid Y = y)\,f_Y(y)\) if \(X\) is discrete and \(Y\) continuous), and the iterated integrals combine an ordinary integral with a sum. The conditional densities/PMFs here are defined the same way as in Definition 17, just conditioning on \(Y\) instead of \(X\).
Proof. Apply Fubini–Tonelli with \(\mu_1 = \mu_X\) and \(\mu_2 = \mu_Y\) to the integrand \(h(x,y)\,f_{X,Y}(x,y)\) on \(\mathcal{R}(X) \times \mathcal{R}(Y)\). Lebesgue measure and counting measure on a countable set are each σ-finite, so \(\mu_X \otimes \mu_Y\) is σ-finite in all three cases. The relevant hypothesis is (a) when \(h \ge 0\) and (b) when \(\operatorname{E}\mathopen{}\left[\mathopen{}\left|h(X, Y)\right|\mathclose{}\right]\mathclose{} < \infty\). Independence is not required. When \(X\) and \(Y\) are independent, \(f_{X,Y}(x,y) = f_X(x)\,f_Y(y)\) (or \(\operatorname{P}(X=x,Y=y) = \operatorname{P}(X=x)\,\operatorname{P}(Y=y)\) in the discrete case), and the iterated integrals factor into separate integrals over the marginals.
Example 11 (Expectation of a product of independent variables) Let \(X \sim \mathrm{Uniform}(0, 1)\) and \(Y \sim \mathrm{Uniform}(0, 2)\), independently distributed. Compute \(\operatorname{E}\mathopen{}\left[XY\right]\mathclose{}\).
We apply Corollary 3 (both-continuous case) with \(h(x, y) = xy\). Since \(X\) and \(Y\) are independent with densities \(f_X(x) = 1\) on \([0,1]\) and \(f_Y(y) = \tfrac{1}{2}\) on \([0,2]\), the joint density factors as \(f_{X,Y}(x,y) = f_X(x)\,f_Y(y) = \tfrac{1}{2}\), and \(\mu_X = \mu_Y = \text{Lebesgue measure}\):
As a check: \(\operatorname{E}\mathopen{}\left[X\right]\mathclose{} = \tfrac{1}{2}\), \(\operatorname{E}\mathopen{}\left[Y\right]\mathclose{} = 1\), and \(\operatorname{E}\mathopen{}\left[X\right]\mathclose{}\operatorname{E}\mathopen{}\left[Y\right]\mathclose{} = \tfrac{1}{2}\).
Example 12 (When independence fails: a counterexample) Correctly applying Corollary 3 requires the actual joint density \(f_{X,Y}\) — not the product of marginals \(f_X(x)\,f_Y(y)\), which is valid only when \(X\) and \(Y\) are independent. Using the wrong joint density gives the wrong answer.
Let \(X \sim \mathrm{Uniform}(0, 1)\) and set \(Y = X\) (so \(X\) and \(Y\) are perfectly correlated and not independent).
Note that Fubini–Tonelli’s own conditions still hold here (\(h(x,y) = xy\) is nonnegative and integrable), so the error is not a failure of Fubini–Tonelli. Rather, the error is using the wrong measure: the joint distribution of \((X, X)\) is concentrated on the diagonal \(\{(x, x) : x \in [0, 1]\} \subset [0, 1]^2\), which has Lebesgue measure zero in \(\mathbb{R}^2\). The joint distribution is therefore not absolutely continuous with respect to two-dimensional Lebesgue measure, so no joint density \(f_{X,Y}\) on \([0, 1]^2\) exists, which is the reference density Corollary 3 requires.
The calculation below is what someone would erroneously write if they assumed independence and used \(f_X(x)\,f_Y(y)\) as a “joint density” — a function that does not in fact correspond to the joint distribution of \((X, X)\). The marginals \(X \sim \mathrm{Uniform}(0,1)\) and \(Y \sim \mathrm{Uniform}(0,1)\) do have densities \(f_X = f_Y = 1\), but the product\(f_X(x)\,f_Y(y) = 1\) on \([0, 1]^2\) is the density of an independent pair, not of \((X, X)\):
This recovers \(\operatorname{E}\mathopen{}\left[XY\right]\mathclose{}\) for independent uniforms (\(\tfrac{1}{4}\)), not \(\operatorname{E}\mathopen{}\left[XX\right]\mathclose{}\) for the perfectly correlated pair (\(\tfrac{1}{3}\)). The lesson is that Corollary 3 requires the actual joint density \(f_{X,Y}\). For independent \((X, Y)\), this factors as \(f_X(x)\,f_Y(y)\); for dependent \((X, Y)\), \(f_{X,Y}\) need not factor — and for \((X, X)\), no joint density on \(\mathbb{R}^2\) exists at all, so Corollary 3 simply does not apply.
[R code]
set.seed(204)n <-400x_dep <-runif(n)y_dep <- x_depx_ind <-runif(n)y_ind <-runif(n)plotly::plot_ly() |> plotly::add_trace(type ="scatter", mode ="markers",x = x_ind, y = y_ind,name ="Assumed independent (X<sub>1</sub>, X<sub>2</sub>)",marker =list(size =5, color ="#999999", opacity =0.5) ) |> plotly::add_trace(type ="scatter", mode ="markers",x = x_dep, y = y_dep,name ="Actual (X, X) on diagonal",marker =list(size =6, color ="#b40426") ) |> plotly::layout(xaxis =list(title ="x", range =c(0, 1), scaleanchor ="y"),yaxis =list(title ="y", range =c(0, 1)),legend =list(orientation ="h", y =-0.2) )
Figure 5: Samples from the joint distribution of \((X, X)\) (red, on the diagonal) versus an independent pair \((X_1, X_2)\) with the same marginals (grey, scattered over \([0, 1]^2\)). The actual joint mass for \((X, X)\) is concentrated on a 1-dimensional diagonal — a set of Lebesgue measure zero in \(\mathbb{R}^2\) — so no joint density on \([0, 1]^2\) exists, and the “\(f_X(x)\,f_Y(y) = 1\)” calculation integrates against the wrong measure (the grey distribution).
Example 13 (Both-continuous case: joint PDF on a non-rectangular support) Let \((X, Y)\) have joint density \(f_{X,Y}(x, y) = 2\) for \(0 \le x \le y \le 1\) (and \(0\) otherwise). Compute \(\operatorname{E}\mathopen{}\left[X + Y\right]\mathclose{}\).
n_grid <-51x_seq <-seq(0, 1, length.out = n_grid)y_seq <-seq(0, 1, length.out = n_grid)z_mat <-outer(x_seq, y_seq, function(x, y) { z <-rep(2, length(x)) z[x > y] <-NA z})plotly::plot_ly(x =~x_seq, y =~y_seq, z =~t(z_mat)) |> plotly::add_surface(showscale =FALSE) |> plotly::layout(scene =list(xaxis =list(title ="x"),yaxis =list(title ="y"),zaxis =list(title ="f(x, y)", range =c(0, 2.5)),camera =list(eye =list(x =1.6, y =-1.6, z =0.8)) ))
Figure 6: Joint density \(f_{X,Y}(x, y) = 2\) on the triangular support \(\{(x, y) : 0 \le x \le y \le 1\}\), and zero elsewhere. The total “volume” under the density is \(2 \cdot \tfrac{1}{2} = 1\), as required.
Exercise 7 (Both-discrete case, infinite support: joint PMF) Let \(X\) and \(Y\) be independent, each Geometric on \(\mathcal{R}(X) = \mathcal{R}(Y) = \{0, 1, 2, \dots\}\) with \(\operatorname{P}(X = x) = (1-p)\,p^x\) for a fixed \(p \in (0, 1)\) (\(X\) counts the number of failures before the first success in a sequence of independent trials with success probability \(1-p\); likewise for \(Y\)). Unlike Exercise 6, the support here is countably infinite. The joint PMF is \(\operatorname{P}(X = x,\, Y = y) = (1-p)^2\,p^{x+y}\).
Solution. Compute \(\operatorname{E}\mathopen{}\left[X + Y\right]\mathclose{}\) using Corollary 3 with \(\mu_X = \mu_Y = \text{counting measure}\) and \(h(x, y) = x + y\). Since \(h(x,y) = x + y \ge 0\) for every \((x,y)\) in this support, hypothesis (a) holds, so Corollary 3 (via Tonelli’s theorem) guarantees the order of this now-infinite double sum is exchangeable — unlike the finite case, elementary algebra alone could not establish this.
By Corollary 3 (both-discrete case), summing over \(y\) first for each fixed \(x\):
using the standard geometric-series facts \(\sum_{y=0}^{\infty} p^y = \frac{1}{1-p}\) and \(\sum_{y=0}^{\infty} y\,p^y = \frac{p}{(1-p)^2}\) (e.g. Casella and Berger (2002)).
As a check, \(\operatorname{E}\mathopen{}\left[X\right]\mathclose{} = \operatorname{E}\mathopen{}\left[Y\right]\mathclose{} = \frac{p}{1-p}\) (the mean of this Geometric distribution; Casella and Berger (2002)), so \(\operatorname{E}\mathopen{}\left[X + Y\right]\mathclose{} = \operatorname{E}\mathopen{}\left[X\right]\mathclose{} + \operatorname{E}\mathopen{}\left[Y\right]\mathclose{} = \frac{2p}{1-p}\) by linearity, matching.
[R code]
p <-0.4exact_sum <-2* p / (1- p)n_trunc <-500support <-0:n_truncjoint_pmf_fn <-function(x, y) (1- p)^2* p^(x + y)joint_probs <-outer(support, support, joint_pmf_fn)h_vals <-outer(support, support, function(x, y) x + y)sum_y_first <-sum(rowSums(h_vals * joint_probs))sum_x_first <-sum(colSums(h_vals * joint_probs))pander::pander(data.frame(quantity =c("exact (closed form)", "sum over y first, then x","sum over x first, then y"),value =round(c(exact_sum, sum_y_first, sum_x_first), 6)))
quantity
value
exact (closed form)
1.333
sum over y first, then x
1.333
sum over x first, then y
1.333
With \(p = 0.4\), summing \(y\) first then \(x\), and summing \(x\) first then \(y\), agree with each other and with the closed form \(\frac{2p}{1-p} = 1.3333\) up to truncation error — exactly Tonelli’s guarantee.
Tonelli’s nonnegativity condition, and what happens without it
The example above only needed hypothesis (a), \(h(X,Y) \ge 0\), because \(h(x,y) = x+y\) is nonnegative on this support. For a signed\(h\), interchanging an infinite double sum is not automatically valid — Corollary 3’s hypothesis (b), \(\operatorname{E}\mathopen{}\left[\mathopen{}\left|h(X,Y)\right|\mathclose{}\right]\mathclose{} < \infty\), is what licenses it in that case. Without either hypothesis, the two orders can genuinely disagree. A standard example (a signed array, not a probability distribution; see e.g. Rudin (1976) for the general theory of rearranging series): let \(a_{m,n} = 1\) if \(m = n\), \(a_{m,n} = -1\) if \(m = n+1\), and \(a_{m,n} = 0\) otherwise, for \(m, n = 0, 1, 2, \dots\). Summing each row \(m\) first: row \(0\) has only the term \(a_{0,0}=1\) (there is no valid \(n = -1\)), so its row sum is \(1\); every row \(m \ge 1\) has \(a_{m,m} = 1\) and \(a_{m,m-1} = -1\), so its row sum is \(0\). Summing the rows then gives \(1 + 0 + 0 + \cdots = 1\). Summing each column \(n\) first: every column \(n \ge 0\) has \(a_{n,n} = 1\) and \(a_{n+1,n} = -1\), so its column sum is always \(0\), and summing the columns then gives \(0 + 0 + \cdots = 0\). The two orders give \(1\) and \(0\): genuinely different answers, confirming that a condition like (a) or (b) really is needed once the terms are no longer all nonnegative.
Exercise 8 (Mixed case: one continuous variable, one discrete variable) Let \(Y \sim \mathrm{Bernoulli}(0.6)\) and, given \(Y = y\), let \(X \mid Y = y \sim \mathrm{Uniform}(0,\, y + 1)\).
As a check using the law of total expectation: \(\operatorname{E}\mathopen{}\left[X \mid Y = 0\right]\mathclose{} = \tfrac{1}{2}\) and \(\operatorname{E}\mathopen{}\left[X \mid Y = 1\right]\mathclose{} = 1\), so \(\operatorname{E}\mathopen{}\left[X\right]\mathclose{} = \tfrac{1}{2}(0.4) + 1(0.6) = 0.2 + 0.6 = 0.8\).
Figure 7: Joint density \(f_{X,Y}(x, y) = f_{X \mid Y}(x \mid y)\,\operatorname{P}(Y = y)\) for each value of the discrete variable \(Y\). The area under each component integrates to \(\operatorname{P}(Y = y)\): \(0.4 \cdot 1 = 0.4\) (blue) and \(0.3 \cdot 2 = 0.6\) (red), summing to 1.
Exercise 9 (Mixed case, infinite discrete support) Let \(Y\) be Geometric on \(\{0, 1, 2, \dots\}\) with \(\operatorname{P}(Y = y) = (1-q)\,q^y\) for a fixed \(q \in (0, 1)\) and, given \(Y = y\), let \(X \mid Y = y \sim \mathrm{Uniform}(0,\, y+1)\). Unlike Exercise 8, \(Y\)’s range here is countably infinite.
Solution. Compute \(\operatorname{E}\mathopen{}\left[X\right]\mathclose{}\) using Corollary 3 with \(\mu_X = \text{Lebesgue measure}\), \(\mu_Y = \text{counting measure}\), and \(h(x, y) = x\).
The joint density w.r.t. Lebesgue \(\times\) counting measure is \(f_{X,Y}(x, y) = f_{X \mid Y}(x \mid y)\,\operatorname{P}(Y = y)
= \frac{(1-q)\,q^y}{y+1}\) for \(x \in [0, y+1]\).
Since \(h(x, y) = x \ge 0\) on this support, hypothesis (a) holds, so Corollary 3 (via Tonelli’s theorem) guarantees the now-infinite sum-of-integrals below is valid — unlike Exercise 8, this is not simply linearity applied to a finite sum.
using the same geometric-series facts as Exercise 7 (e.g. Casella and Berger (2002)).
As a check using the law of total expectation: \(\operatorname{E}\mathopen{}\left[X \mid Y=y\right]\mathclose{} = \frac{y+1}{2}\) (the mean of \(\mathrm{Uniform}(0,y+1)\)) and \(\operatorname{E}\mathopen{}\left[Y\right]\mathclose{} = \frac{q}{1-q}\) (the mean of this Geometric distribution; Casella and Berger (2002)), so:
Proof. Discrete case. When \(X\) and \(Y\) are discrete, applying Definition 13 to \(\operatorname{E}\mathopen{}\left[\operatorname{E}\mathopen{}\left[Y \mid X\right]\mathclose{}\right]\mathclose{}\) and then the law of total probability (Theorem 4) applied to the countable partition \(\{X = x : x \in \mathcal{R}(X)\}\):
Continuous case. When \(X\) and \(Y\) are continuous, applying Definition 13 to \(\operatorname{E}\mathopen{}\left[\operatorname{E}\mathopen{}\left[Y \mid X\right]\mathclose{}\right]\mathclose{}\) and then using Definition 16 for \(\operatorname{E}\mathopen{}\left[Y \mid X=x\right]\mathclose{}\):
where the third equality exchanges the order of integration by hypothesis (b) of Fubini–Tonelli (the absolute-integrability case, Fubini’s theorem); this requires \(\operatorname{E}\mathopen{}\left[\mathopen{}\left|Y\right|\mathclose{}\right]\mathclose{} < \infty\), which is implicit in \(\operatorname{E}\mathopen{}\left[Y\right]\mathclose{}\) being defined, and the fourth equality uses \(\int_{x} \operatorname{p}(Y=y \mid X=x) \cdot\operatorname{p}(X=x)\, dx = \int_{x} \operatorname{p}(X=x, Y=y)\, dx = \operatorname{p}(Y=y)\) (marginalization of the joint density).
Theorem 19 (Conditional law of iterated expectations) For random variables \(X\), \(Y\), and \(Z\):
Proof. For each fixed value \(z\) with positive probability or density:
Discrete case. Conditioning on \(Z=z\), and applying the law of total probability to the partition \(\{X=x : x \in \mathcal{R}(X)\}\) under the conditional distribution given \(Z=z\):
Therefore, as random variables of \(Z\), \(\operatorname{E}\mathopen{}\left[Y \mid Z\right]\mathclose{} = \operatorname{E}\mathopen{}\left[\operatorname{E}\mathopen{}\left[Y \mid X,Z\right]\mathclose{} \mid Z\right]\mathclose{}\).
Example 14 (Marginal expectation from conditional expectations) Suppose \(X\) is a binary random variable indicating treatment assignment (\(X=1\) treated, \(X=0\) control), with \(\operatorname{P}(X=1) = 0.5\), and suppose the outcome \(Y\) has conditional expectations:
Definition 19 (Expectation of a random matrix) For a random matrix \(\mathbf{A}\) of size \(m \times n\) with \((i,j)\)-th element \(A_{ij}\), the expectation\(\operatorname{E}\mathbf{A}\) is the \(m \times n\) matrix whose \((i,j)\)-th element is \(\operatorname{E}\mathopen{}\left[A_{ij}\right]\mathclose{}\):
Definition 21 (Deviation from a population or subpopulation mean) In probabilistic models, we call this quantity a deviation from a mean. It is often also called an error or noise term in other sources. For the random variable \(Y\), define the deviation from its mean as:
For a realized observation \(y\): \[e(y) \stackrel{\text{def}}{=}y - \operatorname{E}\mathopen{}\left[Y\right]\mathclose{}\]
In regression settings, the reference mean is often conditional on covariates: \(e(y_i) \stackrel{\text{def}}{=}y_i - \operatorname{E}\mathopen{}\left[Y_i \mid X_i\right]\mathclose{}\).
In this course, we prefer “deviation” for this mean-deviation quantity. The terms “error” and “noise” are common aliases. We use “residual” (defined in the Linear regression chapter) for deviations from fitted values. For notation in this course, we use \(e(\cdot)\) for these model/data deviations, and reserve \(\varepsilon\mathopen{}\left(\cdot\right)\mathclose{}\) for estimator-to-estimand deviations (see Estimation).
Theorem 20 (Variance as expected squared deviation from the mean)\[\operatorname{Var}\mathopen{}\left(X\right)\mathclose{} = \operatorname{E}\mathopen{}\left[(X - \operatorname{E}\mathopen{}\left[X\right]\mathclose{})^2\right]\mathclose{}\]
Definition 23 (Precision) The precision of a random variable \(X\), often denoted \(\tau(X)\), \(\tau_X\), or shorthanded as \(\tau\), is the inverse of that random variable’s variance; that is:
Theorem 23 (Alternative formula for covariance)\[\operatorname{Cov}\mathopen{}\left(X,Y\right)\mathclose{}= \operatorname{E}\mathopen{}\left[XY\right]\mathclose{} - \operatorname{E}\mathopen{}\left[X\right]\mathclose{} \operatorname{E}\mathopen{}\left[Y\right]\mathclose{}\]
Theorem 24 (Law of total covariance) For random variables \(X\), \(Y\), and \(Z\):
Theorem 25 (Elements of the variance-covariance matrix are pairwise covariances) For a \(p \times 1\) random vector \(\tilde{X}= {(X_1, \ldots, X_p)}^{\top}\), the \((i,j)\)-th element of \(\operatorname{Var}\mathopen{}\left(\tilde{X}\right)\mathclose{}\) is \(\operatorname{Cov}\mathopen{}\left(X_i, X_j\right)\mathclose{}\):
Proof. Let \(\mu_i = \operatorname{E}\mathopen{}\left[X_i\right]\mathclose{}\) for \(i = 1, \ldots, p\), so \(\operatorname{E}\tilde{X}= {(\mu_1, \ldots, \mu_p)}^{\top}\). By Definition 26:
Theorem 26 (Alternate expression for variance of a random vector)\[
\begin{aligned}
\operatorname{Var}\mathopen{}\left(\tilde{X}\right)\mathclose{}
&= \operatorname{E}\mathopen{}\left[\tilde{X}{\tilde{X}}^{\top}\right]\mathclose{} - \mathopen{}\left(\operatorname{E}\tilde{X}\right)\mathclose{} {\mathopen{}\left(\operatorname{E}\tilde{X}\right)\mathclose{}}^{\top}
\end{aligned}
\]
Theorem 27 (Variance of a linear combination) For any vector of random variables \(\tilde{X}= (X_1, \ldots, X_n)\) and corresponding vector of constants \(\tilde{a}= (a_1, ... ,a_n)\), the variance of their linear combination is:
Definition 27 (homoskedastic, heteroskedastic) A random variable \(Y\) is homoskedastic (with respect to covariates \(X\)) if the variance of \(Y\) does not vary with \(X\):
Definition 28 (Statistical independence) A set of random variables \(X_1, \ldots, X_n\) are statistically independent if their joint probability is equal to the product of their marginal probabilities:
Definition 29 (Conditional independence) A set of random variables \(Y_1, \ldots, Y_n\) are conditionally statistically independent given a set of covariates \(X_1, \ldots, X_n\) if the joint probability of the \(Y_i\)s given the \(X_i\)s is equal to the product of their marginal probabilities:
Definition 30 (Identically distributed) A set of random variables \(X_1, \ldots, X_n\) are identically distributed if they have the same range \(\mathcal{R}(X)\) and if their marginal distributions \(\operatorname{P}(X_1=x_1), ..., \operatorname{P}(X_n=x_n)\) are all equal to some shared distribution \(\operatorname{P}(X=x)\):
Definition 31 (Conditionally identically distributed) A set of random variables \(Y_1, \ldots, Y_n\) are conditionally identically distributed given a set of covariates \(X_1, \ldots, X_n\) if \(Y_1, \ldots, Y_n\) have the same range \(\mathcal{R}(X)\) and if the distributions \(\operatorname{P}(Y_i=y_i|X_i =x_i)\) are all equal to the same distribution \(\operatorname{P}(Y=y|X=x)\):
Definition 32 (Independent and identically distributed) A set of random variables \(X_1, \ldots, X_n\) are independent and identically distributed (shorthand: “\(X_i\ \operatorname{iid}\)”) if they are statistically independent and identically distributed.
Definition 33 (Conditionally independent and identically distributed) A set of random variables \(Y_1, \ldots, Y_n\) are conditionally independent and identically distributed (shorthand: “\(Y_i | X_i\ \operatorname{ciid}\)” or just “\(Y_i |X_i\ \operatorname{iid}\)”) given a set of covariates \(X_1, \ldots, X_n\) if \(Y_1, \ldots, Y_n\) are conditionally independent given \(X_1, \ldots, X_n\) and \(Y_1, \ldots, Y_n\) are conditionally identically distributed given \(X_1, \ldots, X_n\).
3.7 The Central Limit Theorem
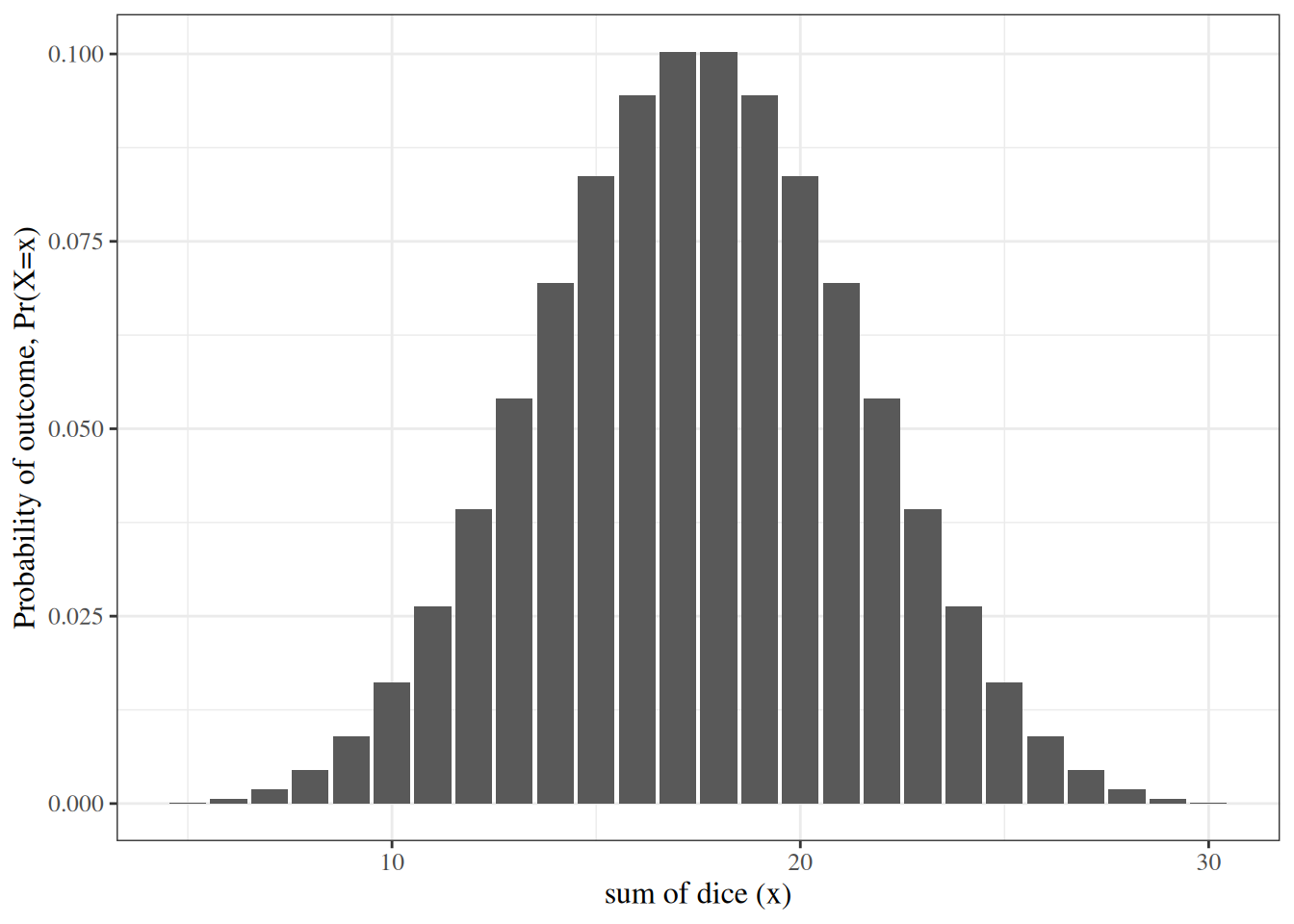
The sum of many independent or nearly-independent random variables with small variances (relative to the number of RVs being summed) produces bell-shaped distributions.
For example, consider the sum of five dice (Figure 8).
[R code]
library(dplyr)dist =expand.grid(1:6, 1:6, 1:6, 1:6, 1:6) |>rowwise() |>mutate(total =sum(c_across(everything()))) |>ungroup() |>count(total) |>mutate(`p(X=x)`= n/sum(n))library(ggplot2)dist |>ggplot() +aes(x = total, y =`p(X=x)`) +geom_col() +xlab("sum of dice (x)") +ylab("Probability of outcome, Pr(X=x)") +expand_limits(y =0)
Figure 8: Distribution of the sum of five dice
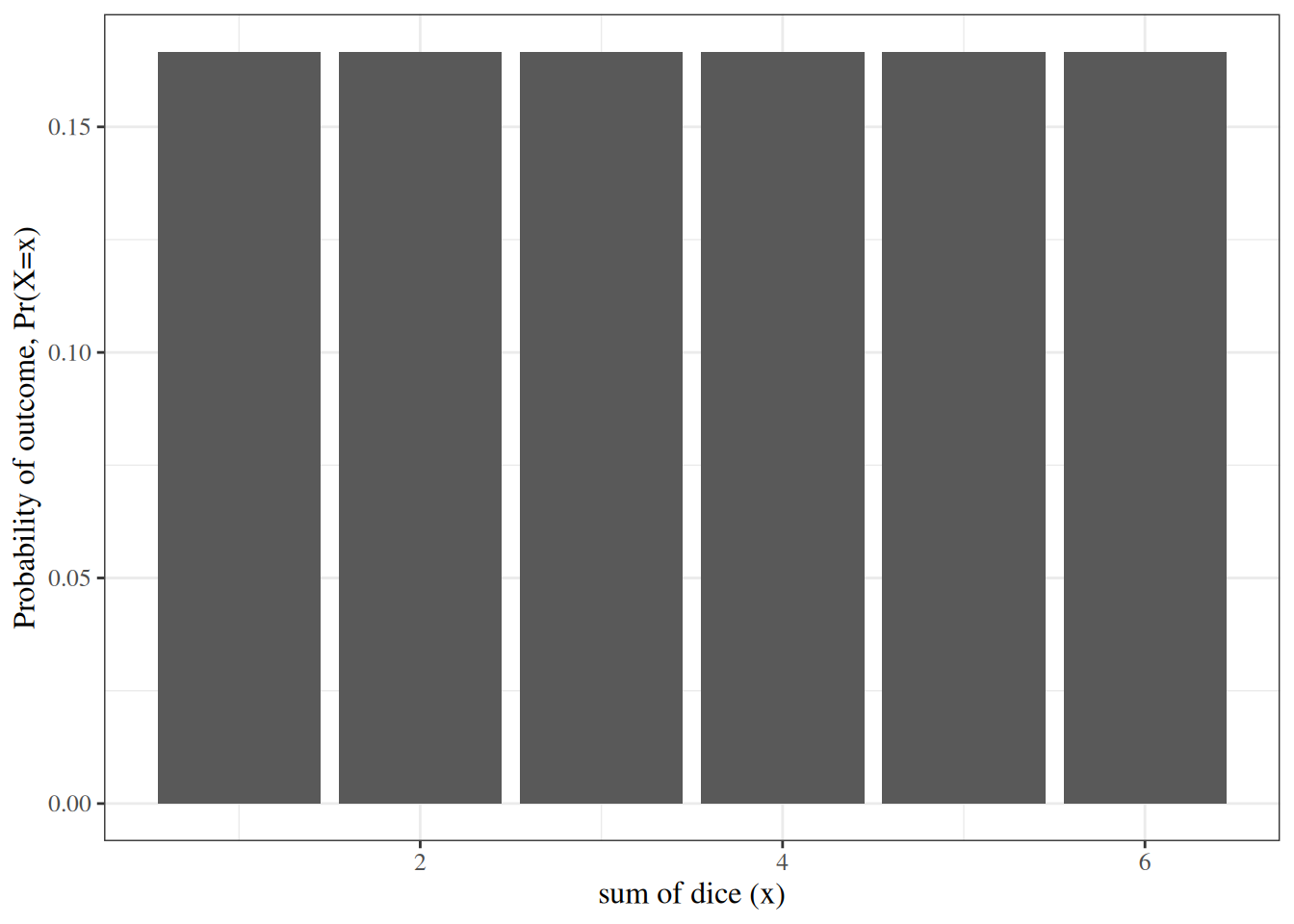
In comparison, the outcome of just one die is not bell-shaped (Figure 9).
[R code]
library(dplyr)dist =expand.grid(1:6) |>rowwise() |>mutate(total =sum(c_across(everything()))) |>ungroup() |>count(total) |>mutate(`p(X=x)`= n/sum(n))library(ggplot2)dist |>ggplot() +aes(x = total, y =`p(X=x)`) +geom_col() +xlab("sum of dice (x)") +ylab("Probability of outcome, Pr(X=x)") +expand_limits(y =0)
Rothman, Kenneth J., Timothy L. Lash, Tyler J. VanderWeele, and Sebastien Haneuse. 2021. Modern Epidemiology. Fourth edition. Wolters Kluwer.
Rudin, Walter. 1976. Principles of Mathematical Analysis. 3rd ed. International Series in Pure and Applied Mathematics. McGraw-Hill.
Vittinghoff, Eric, David V Glidden, Stephen C Shiboski, and Charles E McCulloch. 2012. Regression Methods in Biostatistics: Linear, Logistic, Survival, and Repeated Measures Models. 2nd ed. Springer. https://doi.org/10.1007/978-1-4614-1353-0.