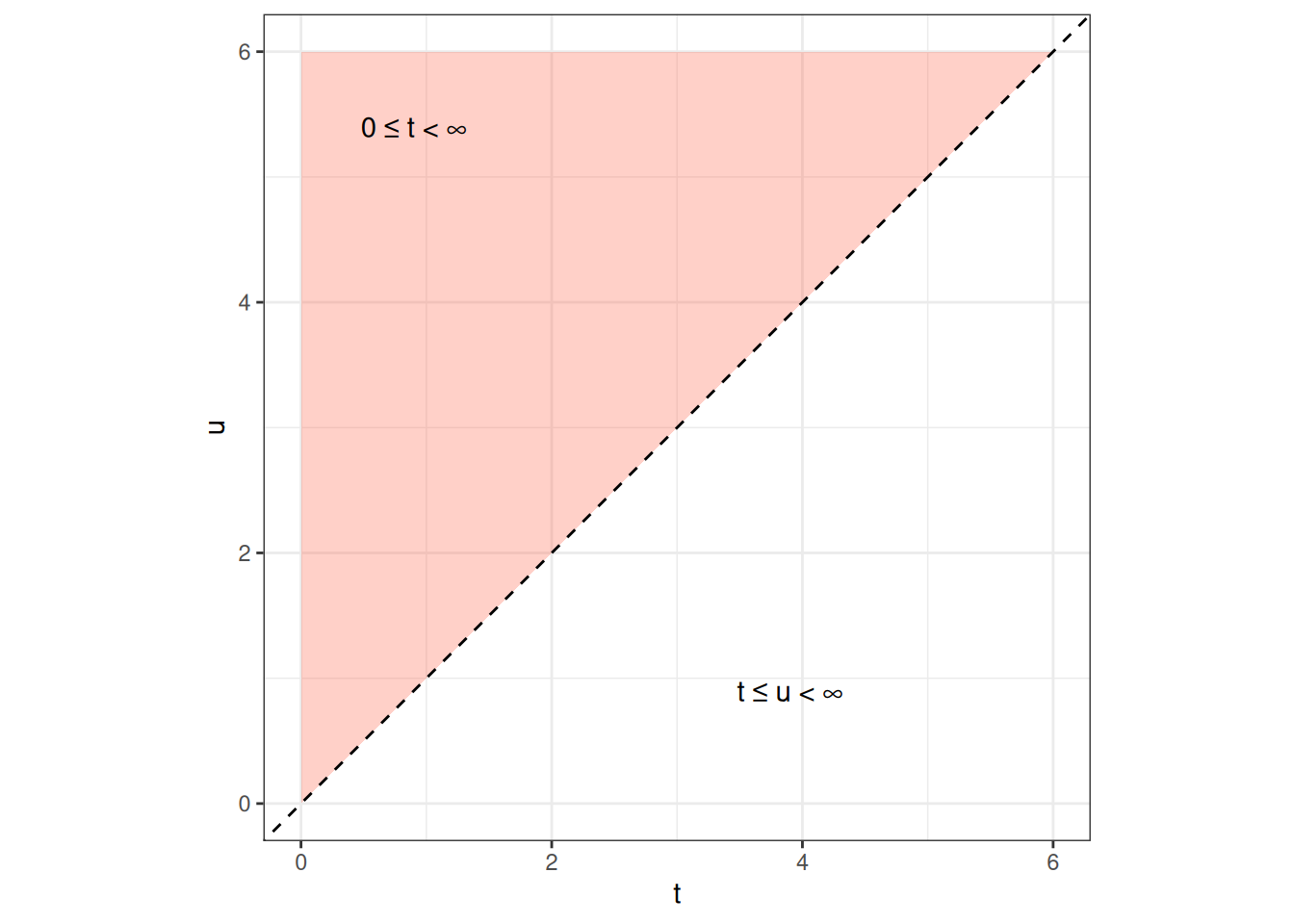
Proof. Since \(\tau_2 > \tau_1\), the event \(\{T > \tau_2\}\) is a subset of \(\{T > \tau_1\}\), so their intersection is just \(\{T > \tau_2\}\) (subset property). By the definition of conditional probability,
\[
\begin{aligned}
\Pr(T > \tau_2 \mid T > \tau_1)
&= \frac{\Pr(T > \tau_2,\ T > \tau_1)}{\Pr(T > \tau_1)}
&& \text{(definition of conditional probability)}
\\
&= \frac{\Pr(T > \tau_2)}{\Pr(T > \tau_1)}
&& \text{(}\{T > \tau_2\} \subseteq \{T > \tau_1\}\text{)}
\\
&= \frac{\operatorname{S}(\tau_2)}{\operatorname{S}(\tau_1)} .
&& \text{(definition of the survival function)}
\end{aligned}
\]
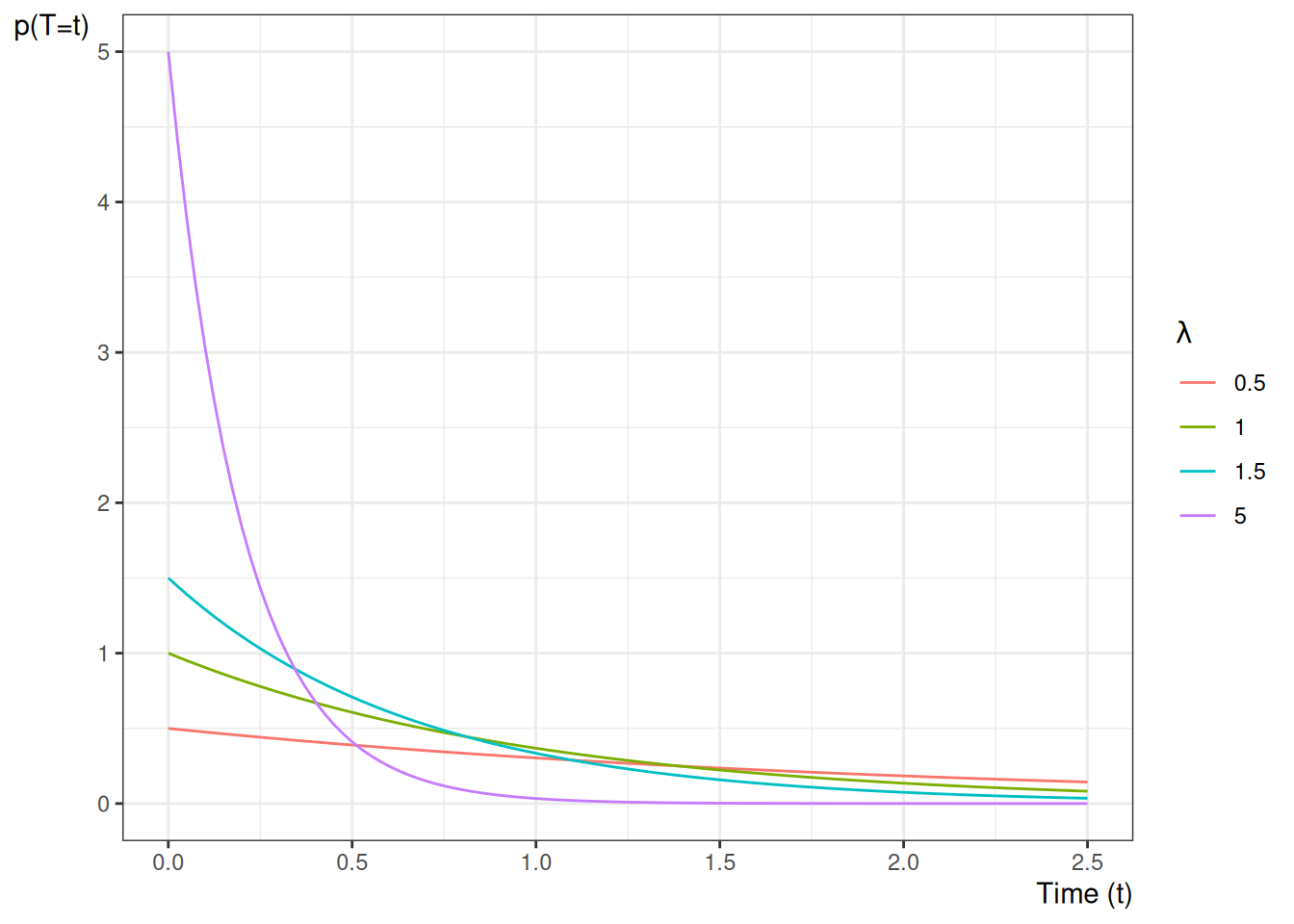
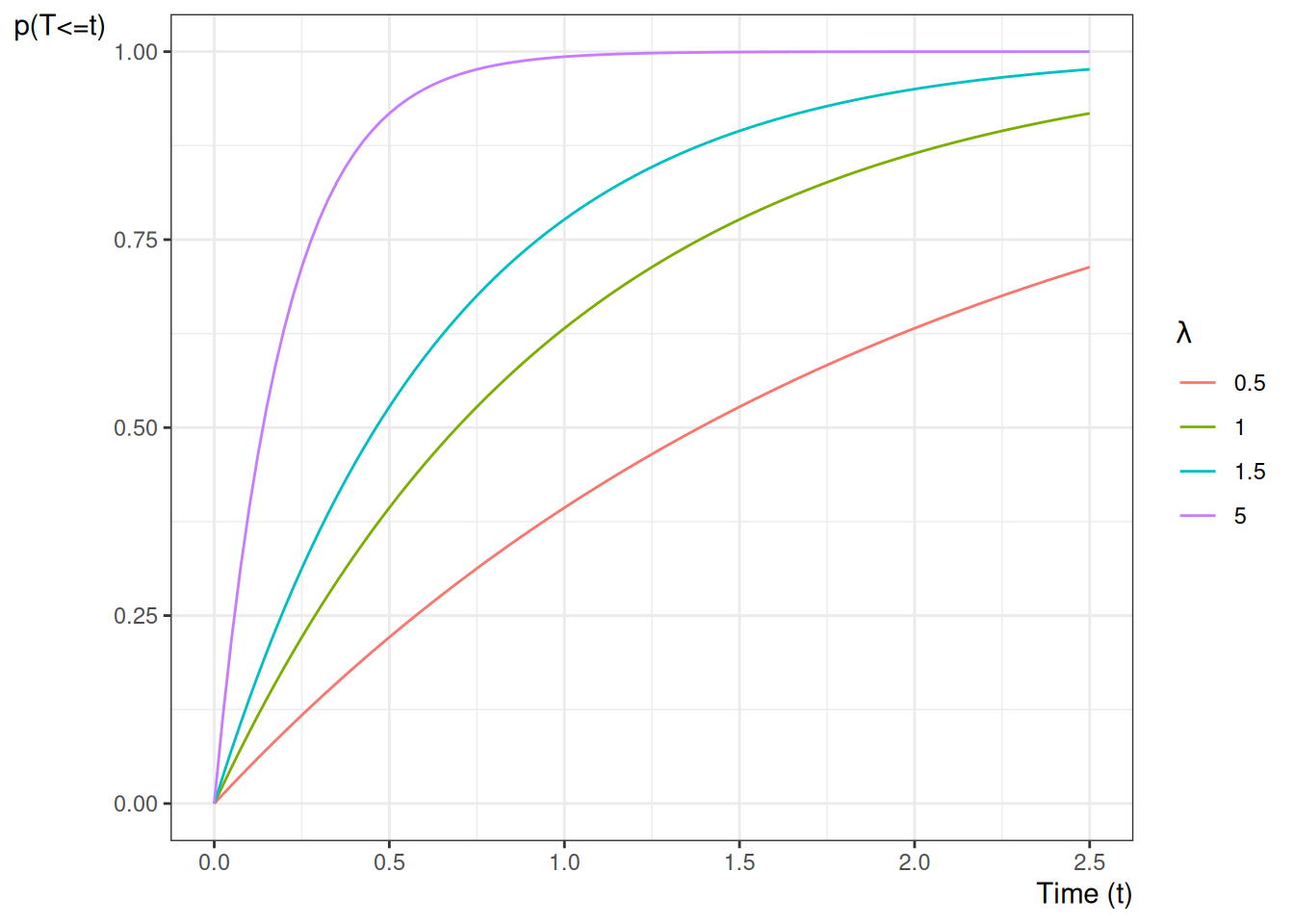
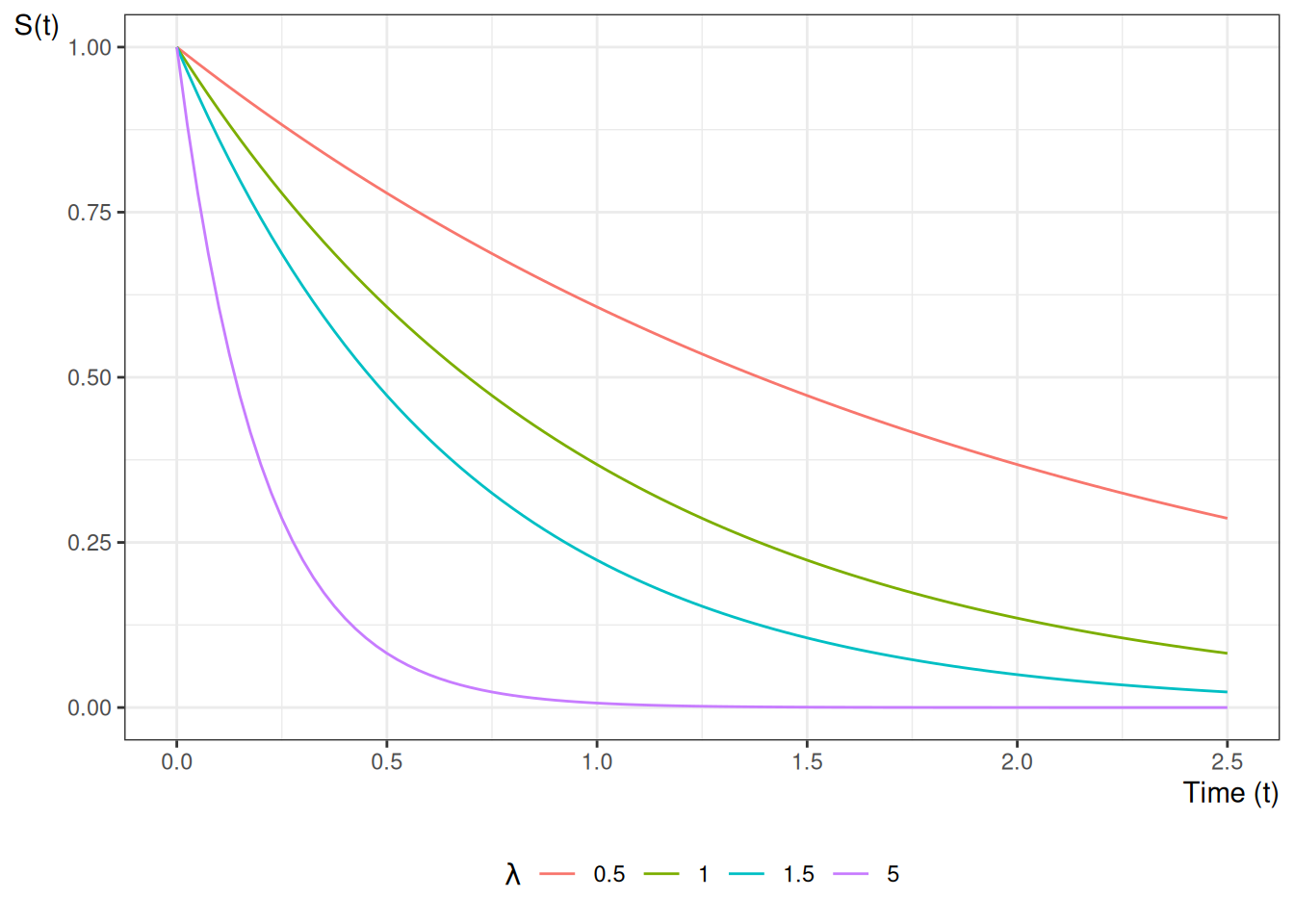
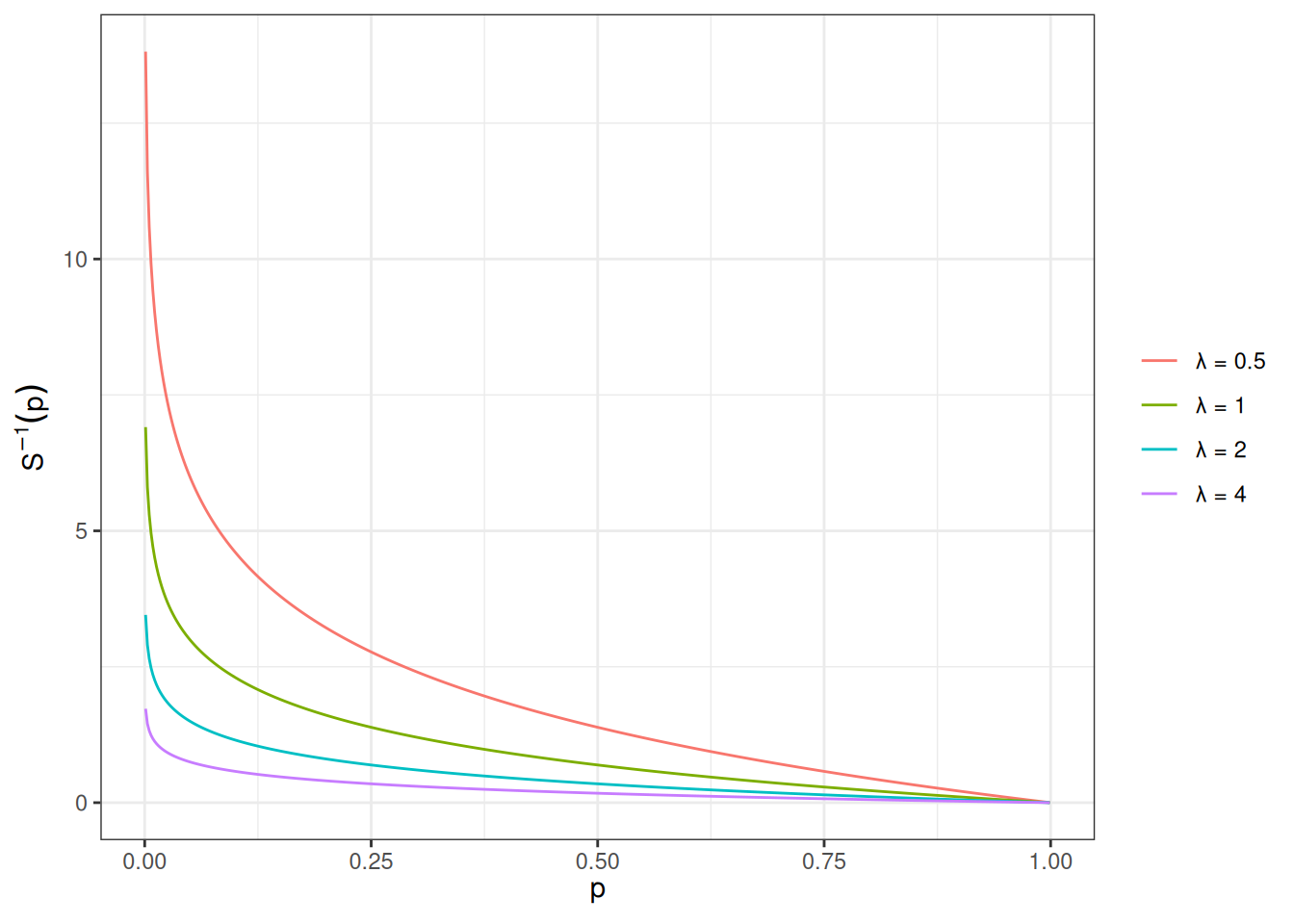
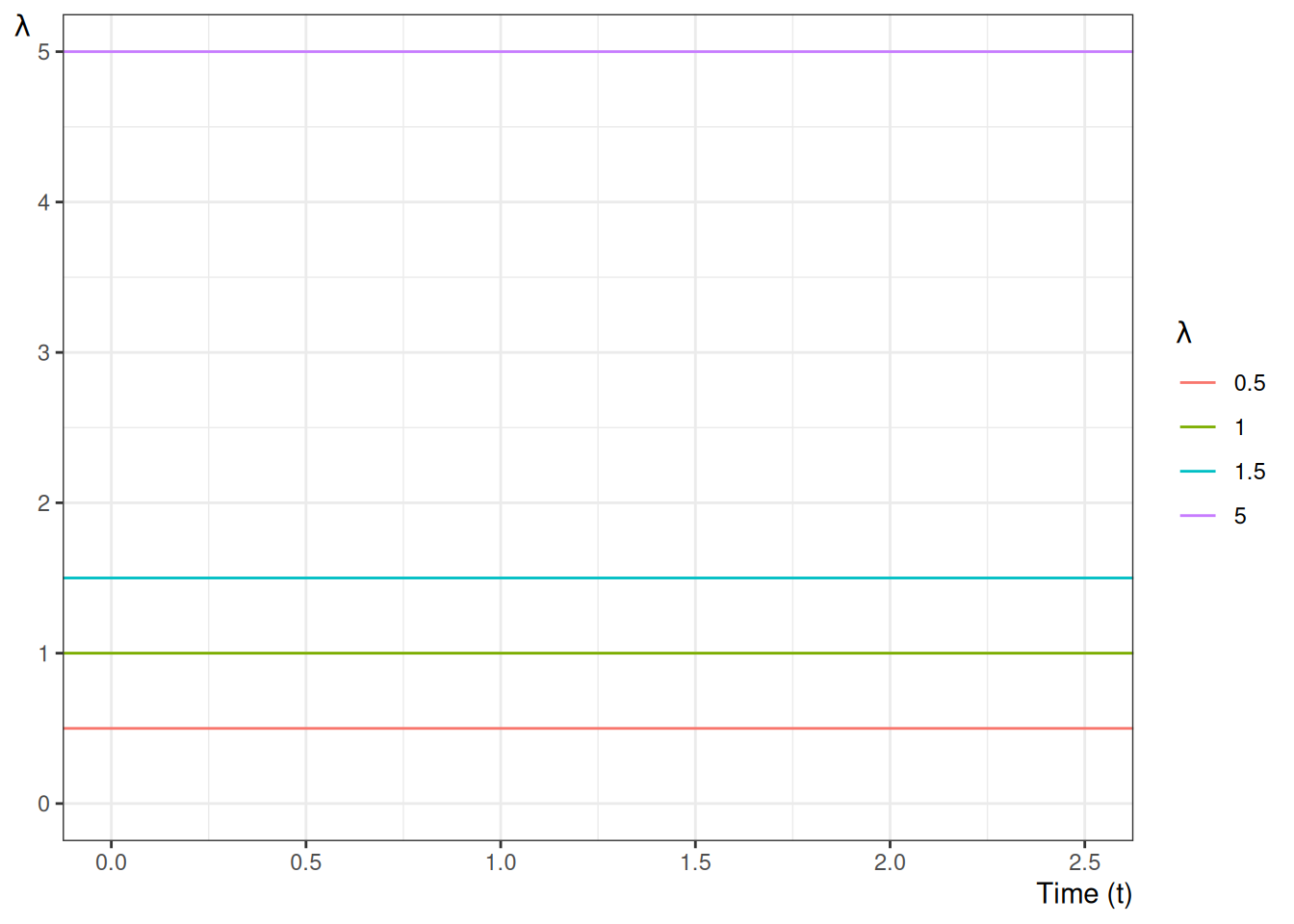
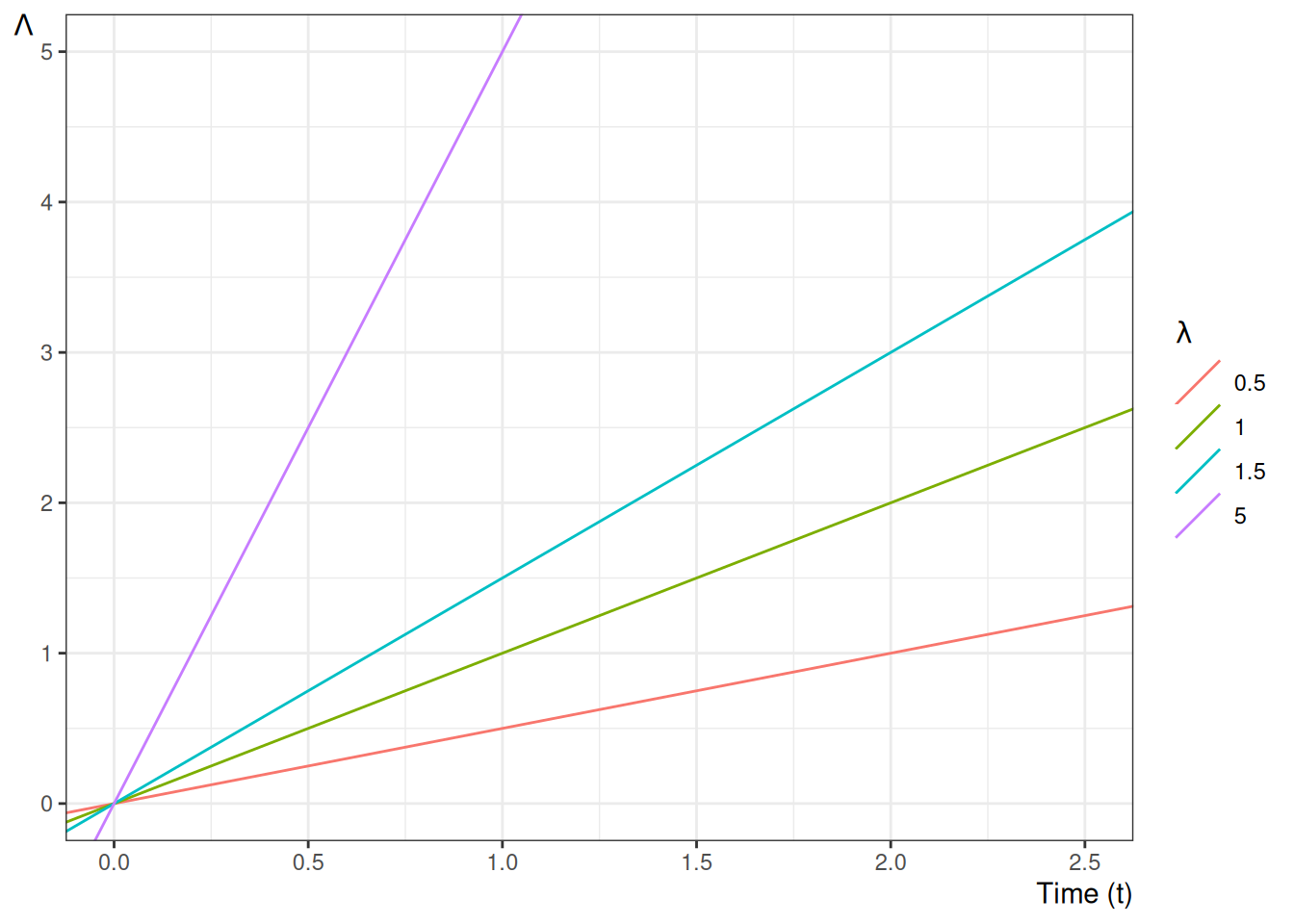
Example 9 (Conditional survival ratio for an exponential lifetime) Let \(T \sim \mathrm{Exponential}(\lambda)\), so \(\operatorname{S}(t) = \operatorname{exp}\mathopen{}\left\{-\lambda t\right\}\mathclose{}\). The probability of surviving past \(\tau_2\) given survival past \(\tau_1 < \tau_2\) is
\[
\begin{aligned}
\Pr(T > \tau_2 \mid T > \tau_1)
&= \frac{\operatorname{S}(\tau_2)}{\operatorname{S}(\tau_1)}
&& \text{(conditional survival ratio)}
\\
&= \frac{\operatorname{exp}\mathopen{}\left\{-\lambda \tau_2\right\}\mathclose{}}{\operatorname{exp}\mathopen{}\left\{-\lambda \tau_1\right\}\mathclose{}}
&& \text{(substitute the exponential survival function)}
\\
&= \operatorname{exp}\mathopen{}\left\{-\lambda(\tau_2 - \tau_1)\right\}\mathclose{} ,
&& \text{(quotient of exponentials)}
\end{aligned}
\]
which depends only on the elapsed time \(\tau_2 - \tau_1\), not on \(\tau_1\) itself — the memoryless property of the exponential distribution.
Example 10 (Interval failure probability: exact value) Suppose subject \(j\) has constant hazard \({\lambda}(t) = 0.1\) per year, and consider the half-year interval \([4.0,\, 4.5)\), so \(\Delta t = 0.5\) years. By Lemma 2 and the survival/cumulative-hazard relationship (Corollary 1), the exact probability that \(j\) fails in this interval, given survival to year \(4\), is
\[
\begin{aligned}
q_j(4.0)
&= \Pr\mathopen{}\left[j \text{ fails in } [4.0,\, 4.5) \mid j \text{ at risk at } 4.0\right]\mathclose{}
&& \text{(definition of } q_j \text{)}
\\
&= 1 - \Pr\mathopen{}\left[j \text{ survives past } 4.5 \mid j \text{ at risk at } 4.0\right]\mathclose{}
&& \text{(complement rule)}
\\
&= 1 - \frac{\operatorname{S}(4.5)}{\operatorname{S}(4.0)}
&& \text{(conditional survival ratio)}
\\
&= 1 - \frac{\operatorname{exp}\mathopen{}\left\{-\int_{0}^{4.5} {\lambda}(u)\,du\right\}\mathclose{}}
{\operatorname{exp}\mathopen{}\left\{-\int_{0}^{4.0} {\lambda}(u)\,du\right\}\mathclose{}}
&& \text{(survival from cumulative hazard)}
\\
&= 1 - \operatorname{exp}\mathopen{}\left\{-\int_{4.0}^{4.5} {\lambda}(u)\,du\right\}\mathclose{}
&& \text{(quotient of exponentials)}
\\
&= 1 - \operatorname{exp}\mathopen{}\left\{-\int_{4.0}^{4.5} 0.1 \,du\right\}\mathclose{}
&& \text{(substitute } {\lambda}(u) = 0.1\text{)}
\\
&= 1 - \operatorname{exp}\mathopen{}\left\{-0.1 \times 0.5\right\}\mathclose{}
&& \text{(constant integrand over width } \Delta t = 0.5\text{)}
\\
&= 1 - \operatorname{exp}\mathopen{}\left\{-0.05\right\}\mathclose{}
&& \text{(arithmetic)}
\\
&\approx 0.0488 .
&& \text{(evaluate } e^{-0.05} \approx 0.9512\text{)}
\end{aligned}
\]
Definition 13 (Risk Set) For a survival study with \(n\) subjects, let \(T_i\) denote the true event time and \(C_i\) the censoring time for subject \(i\), and let \(\tilde{T}_i = \min(T_i, C_i)\) be the observed follow-up time. The risk set at time \(t\) is
\[\mathcal{R}(t) \;\stackrel{\text{def}}{=}\; \bigl\{i \in \{1, \ldots, n\} : \tilde{T}_i \geq t\bigr\},\]
the set of subjects still under observation (neither having experienced the event nor been censored) immediately before time \(t\).
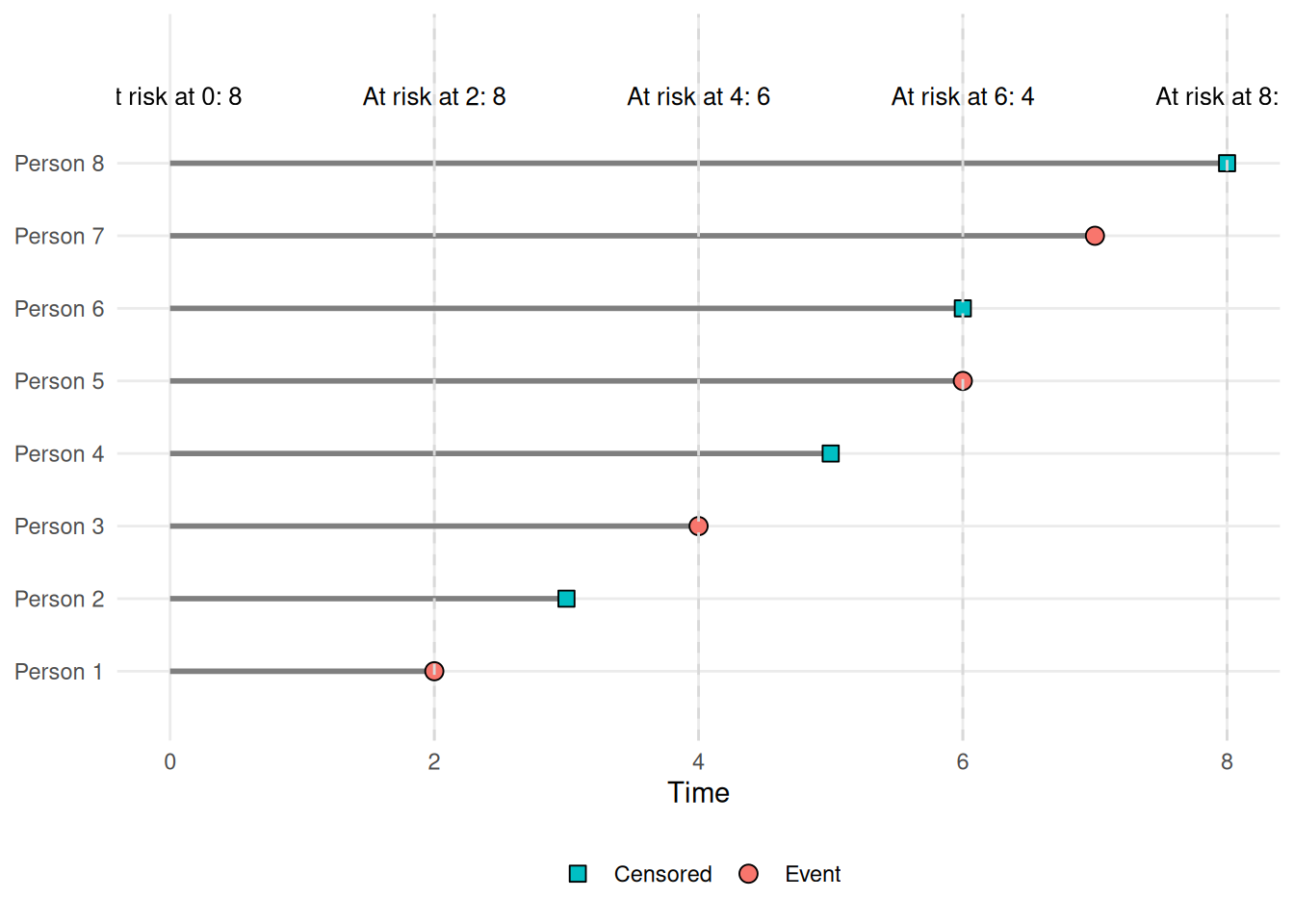
Example 12 In Figure 11, the 8-person study has \(\tilde{T}_i \in \{2, 3, 4, 5, 6, 6, 7, 8\}\). At time \(t = 4\), subjects 3, 4, 5, 6, 7, and 8 still have \(\tilde{T}_i \geq 4\), so \(\mathcal{R}(4) = \{3, 4, 5, 6, 7, 8\}\).
To see why multiplying the conditional survival factors estimates marginal survival, write the ordered distinct exit times as \(y_1 < y_2 < \cdots < y_m\). Here \(Y\) denotes exit time (either event time or censoring time), while \(T\) denotes the underlying event time, which is not always observed.
Because \(y_{j-1}\) and \(y_j\) are consecutive distinct exit times, there are no exits between them. Therefore the conditional probability of surviving between these two times is 1:
\[
\Pr(Y \geq y_j \mid Y > y_{j-1}) = 1.
\]
Then the event \(\{Y \geq y_j\}\) is contained in the event \(\{Y > y_{j-1}\}\), because \(y_j > y_{j-1}\). Therefore intersecting \(\{Y \geq y_j\}\) with \(\{Y > y_{j-1}\}\) does not change the event:
Theorem 11 (Consecutive Exit-Time Identity) If \(\Pr(Y \geq y_j \mid Y > y_{j-1}) = 1\), then:
\[\Pr(Y \geq y_j) = \Pr(Y > y_{j-1})\]
Proof. \[
\begin{aligned}
\Pr(Y \geq y_j)
\\
&= \Pr(Y \geq y_j, Y > y_{j-1})
\\
&= \Pr(Y \geq y_j \mid Y > y_{j-1}) \Pr(Y > y_{j-1})
\\
&= 1 \Pr(Y > y_{j-1})
\\
&= \Pr(Y > y_{j-1})
\end{aligned}
\]
The first equality uses the containment \(\{Y \geq y_j\} \subseteq \{Y > y_{j-1}\}\) (subset property). The second equality uses the multiplication rule for probabilities, and the third equality uses the between-exit-time survival assumption.
Let \(\kappa(y_j) = \Pr(Y > y_j \mid Y \geq y_j)\) denote the conditional probability of surviving past the exit time \(y_j\), given survival up to \(y_j\). By Theorem 11, the conditioning event \(\{Y \geq y_j\}\) has the same probability as \(\{Y > y_{j-1}\}\), so \(\kappa(y_j)\) is really a conditional survival probability spanning the previous exit time to this one; applying Lemma 2 to that pair of times gives:
\[
\begin{aligned}
\kappa(y_j)
&\stackrel{\text{def}}{=}\Pr(Y > y_j \mid Y \geq y_j)
&& \text{(definition of } \kappa(y_j)\text{)}
\\
&= \frac{\Pr(Y > y_j,\ Y \geq y_j)}{\Pr(Y \geq y_j)}
&& \text{(definition of conditional probability)}
\\
&= \frac{\Pr(Y > y_j)}{\Pr(Y \geq y_j)}
&& \text{(}\{Y > y_j\} \subseteq \{Y \geq y_j\}\text{)}
\\
&= \frac{\Pr(Y > y_j)}{\Pr(Y > y_{j-1})}
&& \text{(consecutive exit-time identity)}
\\
&= \frac{\Pr(Y > y_j,\ Y > y_{j-1})}{\Pr(Y > y_{j-1})}
&& \text{(}\{Y > y_j\} \subseteq \{Y > y_{j-1}\}\text{)}
\\
&= \Pr(Y > y_j \mid Y > y_{j-1})
&& \text{(definition of conditional probability)}
\\
&= \frac{\operatorname{S}\mathopen{}\left(y_j\right)\mathclose{}}{\operatorname{S}\mathopen{}\left(y_{j-1}\right)\mathclose{}} ,
&& \text{(conditional survival ratio)}
\end{aligned}
\]
so, rearranging, the marginal survival through \(y_j\) is written recursively:
\[
\operatorname{S}\mathopen{}\left(y_j\right)\mathclose{} = \kappa(y_j)\,\operatorname{S}\mathopen{}\left(y_{j-1}\right)\mathclose{}.
\]
The same recursion can be applied repeatedly. If \(S_j = \Pr(Y > y_j)\) and \(S_0 = 1\), then:
\[
\begin{aligned}
S_1
&= \kappa(y_1)S_0\\
&= \kappa(y_1),\\
S_2
&= \kappa(y_2)S_1\\
&= \kappa(y_2)\kappa(y_1),\\
S_3
&= \kappa(y_3)S_2\\
&= \kappa(y_3)\kappa(y_2)\kappa(y_1).
\end{aligned}
\]
Continuing in this way gives \(S_j = \prod_{k=1}^j \kappa(y_k)\).
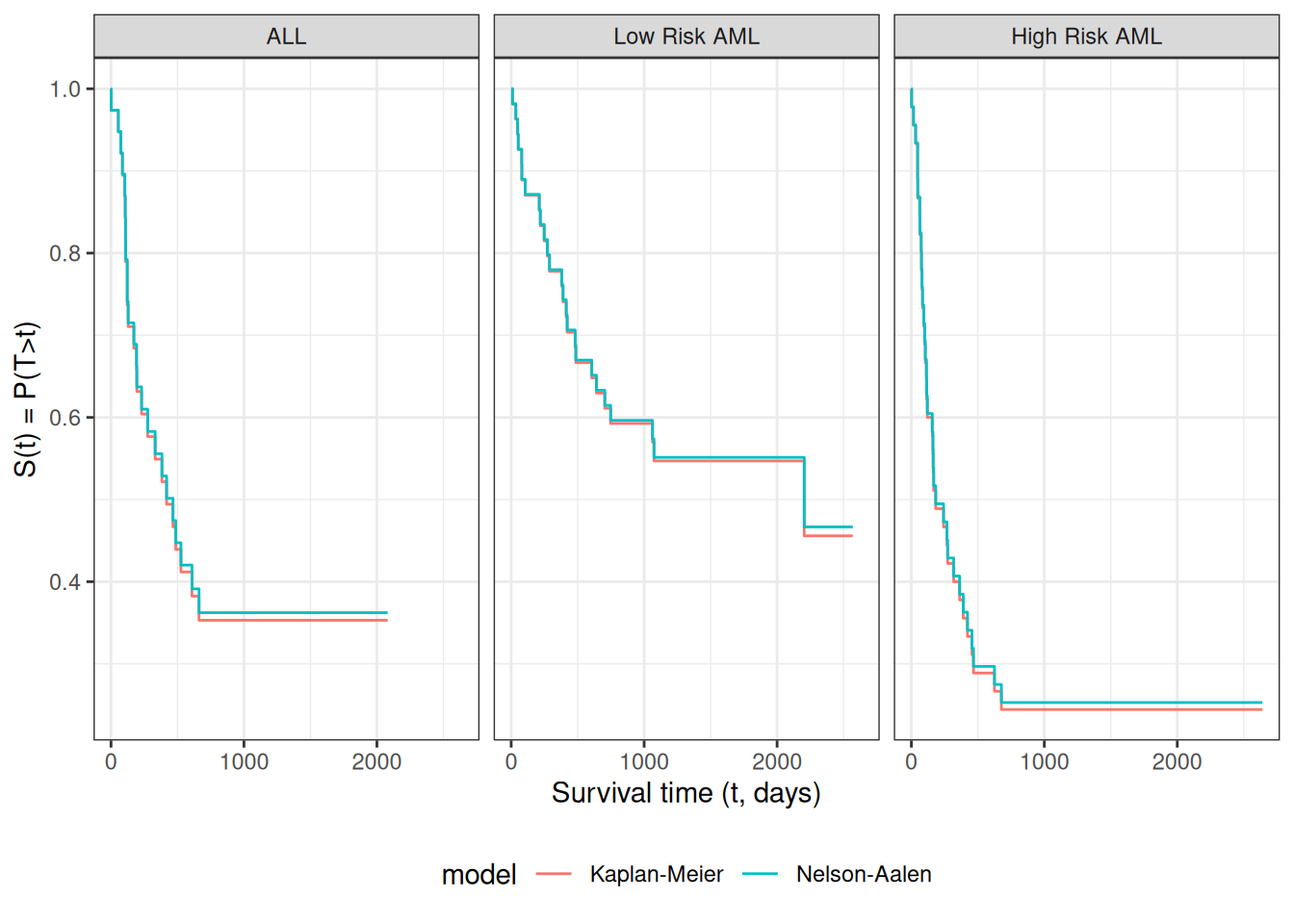
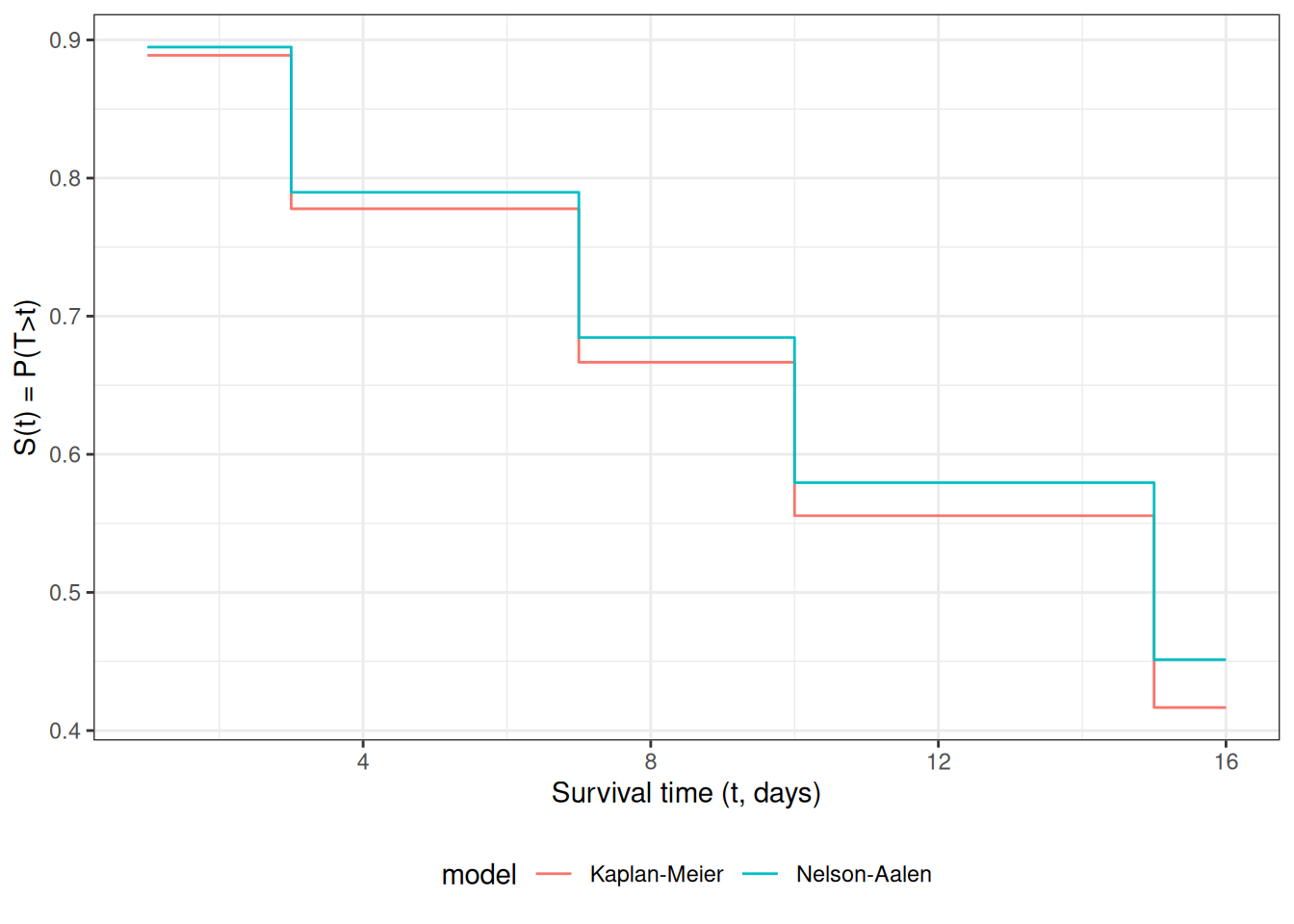
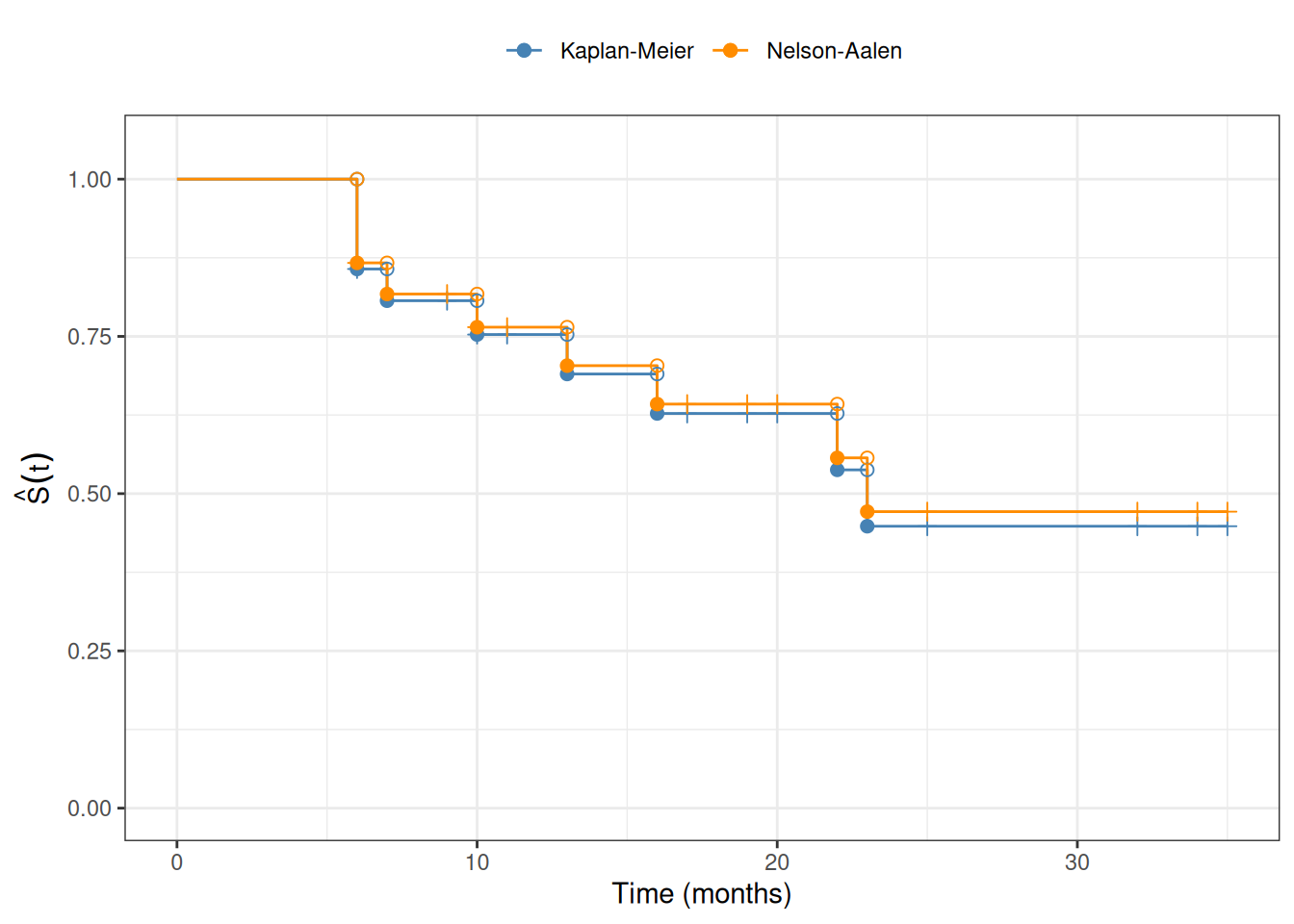
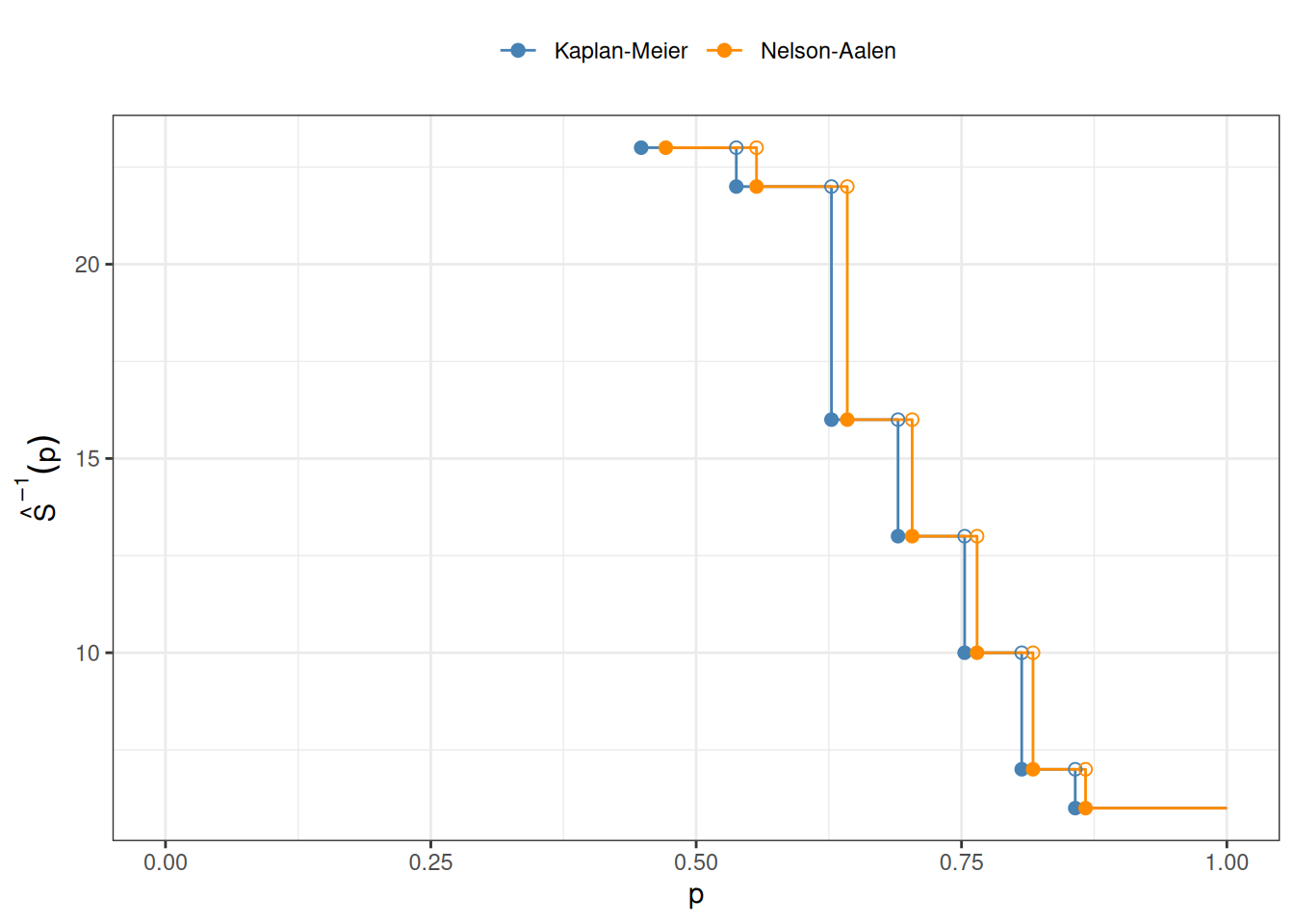
To estimate the survival function for the underlying event time \(T\), we replace the conditional survival probabilities \(\Pr(T > y_k \mid T \geq y_k)\) with their empirical estimates at the observed exit times. This gives the Kaplan-Meier product-limit estimator:
\[
\begin{aligned}
\hat{\Pr}(T > t)
&= \mathop{\hat{\operatorname{S}}}\nolimits_{\text{KM}}\mathopen{}\left(t\right)\mathclose{}\\
&= \prod_{k:\, y_k \leq t} \hat{\Pr}(T > y_k \mid T \geq y_k)\\
&= \prod_{k:\, y_k \leq t} \hat{\kappa}_k\\
&= \prod_{k:\, y_k \leq t} \frac{r_k - d_k}{r_k}
\end{aligned}
\]
where \(r_k\) is the number at risk at time \(y_k\) and \(d_k\) is the number of events (not total exits) at time \(y_k\). The empirical factor \((r_k - d_k)/r_k\) estimates \(\Pr(T > y_k \mid T \geq y_k)\) by counting only events in the numerator, since censoring times do not provide information about the event time distribution.
For any time \(t\) between two consecutive exit times, the estimate stays constant, because the only additional conditional survival factors are 1.