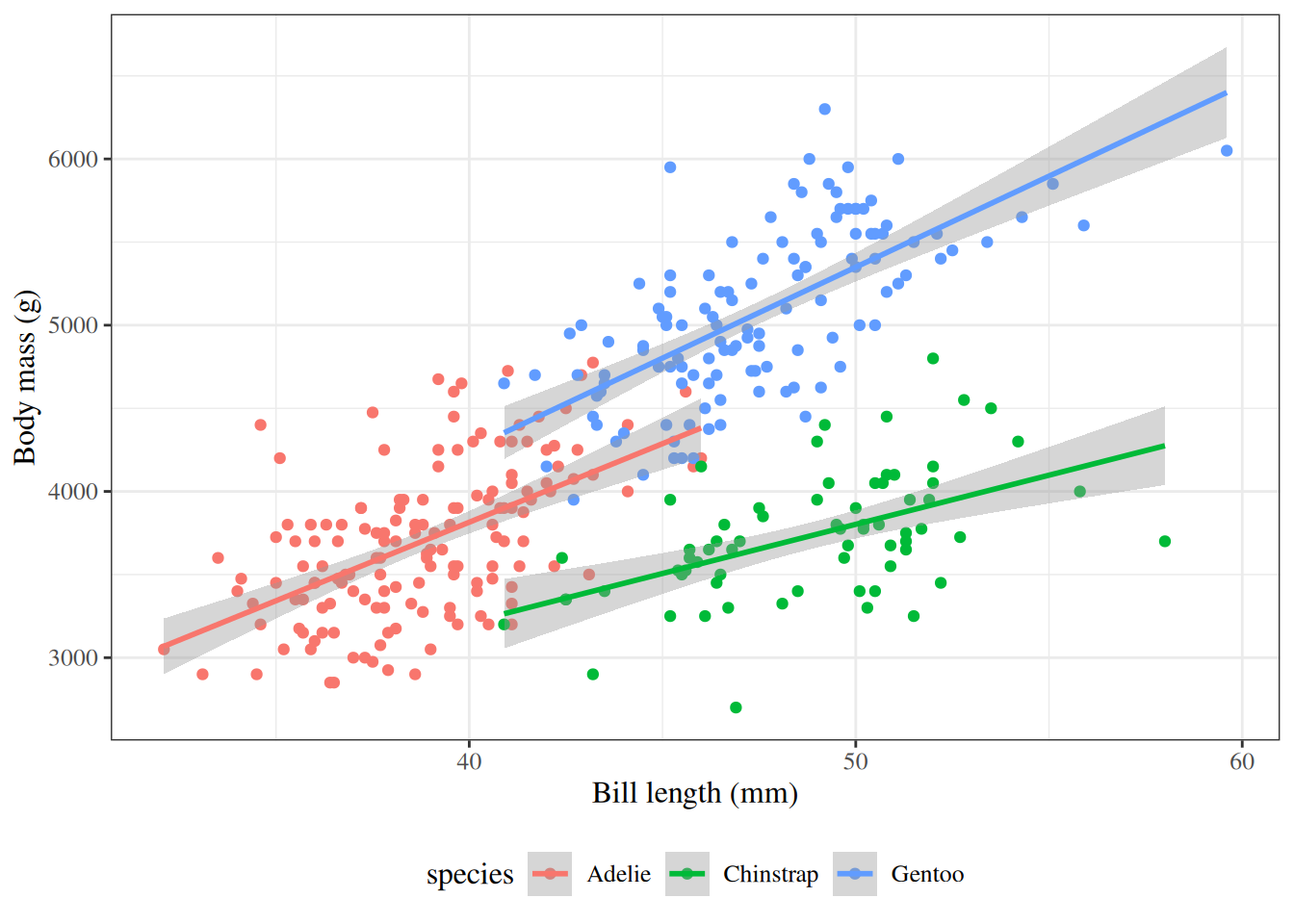
Uses of regression models
Vittinghoff et al. (2012, sec. 1.3) identifies three broad motivations for using multipredictor regression models:
Multipredictor regression can be a powerful tool for addressing three important practical questions. … [These] include prediction, isolating the effect of a single predictor, and understanding multiple predictors.
Prediction: “Multipredictor regression is a powerful and general tool for using multiple measured predictors to make useful predictions for future observations.”
Isolating the Effect of a Single Predictor: “In settings where multiple, related predictors contribute to study outcomes, it will be important to consider multiple predictors even when a single predictor is of interest.” (e.g., to minimize confounding and support causal interpretation)
Understanding Multiple Predictors: “Multipredictor regression can also be used when our aim is to identify multiple independent predictors of a study outcome — independent in the sense that they appear to have an effect over and above other measured variables.” (including mediation and interaction)
Kleinbaum et al. (2014, sec. 4.1) provides a more granular list of eight overlapping applications of regression analysis:
In practice, a regression analysis is appropriate for several possibly overlapping situations, including the following:
Characterize the association: “You want to characterize the relationship between the dependent and independent variables by determining the extent, direction, and strength of the association.”
Prediction: “You seek a quantitative formula or equation to describe (e.g., predict) the dependent variable \(Y\) as a function of the independent variables \(X_1, X_2, \ldots, X_k\).”
Controlled description: “You want to describe quantitatively or qualitatively the relationship between \(X_1, X_2, \ldots, X_k\) and \(Y\) but control for the effects of still other variables \(X_{k+1}, X_{k+2}, \ldots, X_{k+p}\), which you believe have an important relationship with the dependent variable.”
Variable selection: “You want to determine which of several independent variables are important and which are not for describing or predicting a dependent variable. You may want to control for other variables. You may also want to rank independent variables in their order of importance.”
Model selection: “You want to determine the best mathematical model for describing the relationship between a dependent variable and one or more independent variables.”
Comparing regression relationships: “You want to compare several derived regression relationships.” (e.g., whether a relationship between two variables differs across subgroups)
Interaction: “You want to assess the interactive effects of two or more independent variables with regard to a dependent variable.”
Adjusted coefficient estimation: “You want to obtain a valid and precise estimate of one or more regression coefficients from a larger set of regression coefficients in a given model.” (i.e., estimating the effect of one variable after adjusting for others)
Relating the two lists
The two lists use different levels of granularity to describe the same landscape of regression uses. Vittinghoff et al. (2012) provides three broad categories, while Kleinbaum et al. (2014) identifies eight more specific applications.
Applications 6 and 7 are related but distinct: Application 6 asks whether a derived regression relationship (e.g., a coefficient or the overall model) differs across pre-defined groups, typically by comparing models fit separately for each group. Application 7 asks whether two predictors interact within a single model — that is, whether the effect of one predictor on the outcome depends on the value of another predictor. In that sense, Application 6 can be viewed as a special case of Application 7 where the grouping variable is the effect modifier.
The key conceptual distinction made by Vittinghoff et al. (2012) — but not explicitly highlighted by Kleinbaum et al. (2014) — is between prediction (forecasting future outcomes) and causal inference (estimating the effect of a specific predictor). This distinction has important implications for model building strategy: prediction models can include any variables that improve predictive accuracy, while causal inference requires careful consideration of confounding, mediation, and the causal structure of the data.
Prediction, Inference, and Causal Inference
The goal of prediction is to forecast an outcome \(Y\) for new observations, given observed predictor variables \(X_1, \ldots, X_p\). In a prediction problem, the model is often treated as a “black box”: we care about predictive accuracy, not about the exact form or interpretation of the relationship between predictors and outcome (James et al. 2021, chap. 2).
Example 1 For example, a clinical prediction model might identify which patients are at highest risk of hospital readmission, using demographics, diagnoses, and laboratory values, without requiring that each predictor be causally related to readmission.
At its core, prediction aspires to minimize uncertainty: the goal is that, by including enough informative predictors and combining them flexibly, we can reduce as much as possible the residual randomness in our forecasts.
Statistical inference also studies the relationship between \(Y\) and \(X_1, \ldots, X_p\), but the goal shifts from accuracy to understanding: which predictors are associated with the response, in what direction, and by how much (James et al. 2021, chap. 2)?
Example 2 For example, a cohort study might estimate the association between smoking and lung cancer incidence, along with a confidence interval quantifying uncertainty about the magnitude of that association.
Unlike prediction, statistical inference treats the uncertainty in outcomes as a meaningful quantity to characterize, not merely residual noise to be minimized.
Causal inference asks a distinct third question. A predictive association between a predictor \(X\) and an outcome \(Y\) does not imply that intervening to change \(X\) will change \(Y\). Causal inference addresses this gap: it asks what would happen to \(Y\) if we were to actively set \(X\) to a particular value, rather than passively observe it (Vittinghoff et al. 2012, chap. 12).
Example 3 For example, even if smoking is strongly associated with lung cancer in observational data, causal inference asks whether reducing smoking rates would cause a reduction in lung cancer incidence — a question that requires additional assumptions about the data-generating process.
One useful framing of causal inference is as a prediction problem in counterfactual worlds: predicting what outcomes would have occurred under treatment conditions that were not actually administered. Under the potential outcomes framework (Neyman 1990; Rubin 1974, 688–701; Vittinghoff et al. 2012, chap. 12), individual causal effects are treated as deterministic in principle — each person has a fixed potential outcome under each treatment condition — and uncertainty arises from the fact that we can observe only one potential outcome per person, and from heterogeneity in effects across individuals.
Accurate causal inference typically requires accounting for confounding: in observational data, people who receive a treatment are often systematically different from those who do not in ways that also affect the outcome. These differences can make predictive associations misleading for causal questions.
A useful informal distinction: prediction asks which individuals are at highest risk, while causal inference asks what is the effect of a particular intervention, and statistical inference asks what the association is without necessarily specifying an intervention.
For an accessible introduction to the distinction between prediction and statistical inference, see James et al. (2021, chap. 2). For coverage of causal inference methods in an epidemiological setting, see Vittinghoff et al. (2012, chap. 12) and Hernán and Robins (2020, pt. I). For an in-depth treatment, see the causal inference chapter.